Explore the latest in AI
Benchmarking & Evaluation
Welcome to the LayerLens Blog, where we dive into the latest advancements in AI model evaluation, industry benchmarks, and the ever-evolving landscape of generative AI. Our mission is to provide transparent, data-driven insights that empower enterprises, researchers, and developers to make informed decisions about AI model performance, safety, and real-world applicability.

Stratix Can Now Generate Synthetic Evaluation Data (Public Preview)
Published:

Quarterfinals Recap: The Group Winner That Ran Out of Time
Published:

Stratic Cup Day 2 Recap: Four Definitions of Adaptation
Published:

Under the Hood: How the Stratix Cup Actually Works
Published:

Eval Fatigue Is a Process Problem
Published:

Stop Building Your Own LLM Evaluation Framework
Published:

How to Detect LLM Regression in Production
Published:

How to Evaluate AI Agents in Production
Published:

Qwen2.5 72B Instruct on Humanity's Last Exam: 3.7% accuracy
Published:

AI Teams Are Repeating the Biggest Mistake in Software History
Published:
Llama 4 Scout on AIME 2025: 6.7% accuracy
Published:
Llama 4 Maverick on SWE-bench Lite (SWE-agent): 8.0% accuracy
Published:

The Builder Path: From First Trace to Production-Grade AI Evaluation
Published:

Step-Level Evaluation vs Output-Level Evaluation for AI Agent Traces
Published:

AgentGraph is Live: See Every Decision Your Agent Made
Published:
Llama 4 Scout on Terminal-Bench (Terminus-1): 8.8% accuracy
Published:
Claude Opus 4.5 on Humanity's Last Exam: 13.6% accuracy
Published:
Claude Opus 4.6 on Humanity's Last Exam: 18.6% accuracy
Published:

The Cost of Not Evaluating Your AI Agents
Published:
Gemini 3.1 Flash Lite Preview on AIME 2025: 30.0% accuracy
Published:

LLM Evaluation Metrics: What to Measure and Why
Published:

Q1 2026 Frontier Model Report: What the Release Cycle Broke in Your Evaluation Stack
Published:

What Is LLM Evaluation? The Complete Guide for 2026
Published:
Gemini 3.1 Pro Preview on Humanity's Last Exam: 40.6% accuracy
Published:

Xiaomi MiMo-V2 Evaluation: Benchmark Results Across 7 Tests on Stratix
Published:
Llama 4 Maverick on LiveCodeBench: 45.4% accuracy
Published:
Claude Opus 4.5 on SWE-bench Lite (SWE-agent): 49.3% accuracy
Published:
Kimi K2.6 on AIME 2025: 56.7% accuracy
Published:

AI Agent Testing: From Unit Tests to Production Monitoring
Published:

Partner Evaluation Spaces: Benchmark Models on Fireworks AI and Nebius Infrastructure
Published:
Kimi K2.6 on AIME 2026: 63.3% accuracy
Published:

Gemini 3.1 Flash Lite Benchmark Results vs. GPT-5 Nano, Qwen3.5: Efficiency Model Comparison
Published:
GPT-5 on LiveCodeBench: 81.7% accuracy
Published:

Introducing Judge Optimization on Stratix Enterprise: Close the Gap Between Automated Scores and Human Judgment
Published:
Gemini 3.1 Pro Preview on AIME 2025: 93.3% accuracy
Published:
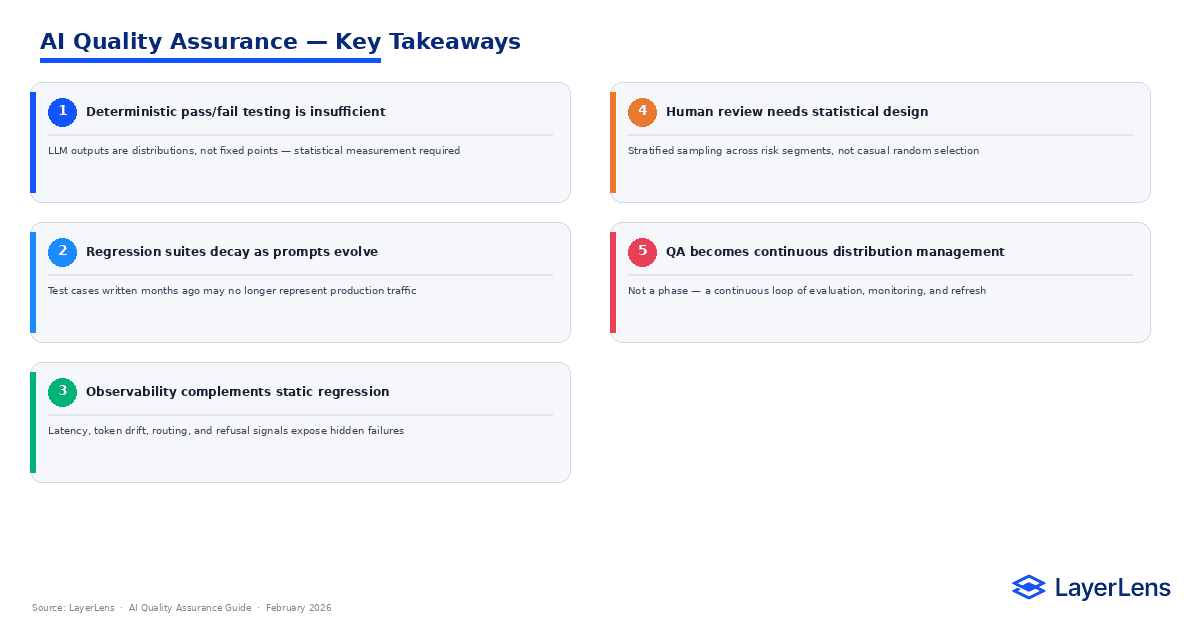
AI Quality Assurance for LLM Systems: Why Traditional QA Breaks
Published:
GPT-5 on AIME 2025: 96.7% accuracy
Published:

AI Model Comparison in Production
Published:

RAG Evaluation Framework for Production AI Systems
Published:
LLM Evaluation Framework for Production
Published:

Stratix Cup Season 1: Six Rounds of LLM Self-Improvement in Public
Published:

Stratix Cup Day 3 Recap: 16 Teams. 8 Eliminated today.
Published:

Matchday 1 Recap: What the Traces Actually Showed
Published:

The Compounding Math Engineers Miss When They Dismiss Agent Failures
Published:

How to Evaluate LLM Agents: A Step-by-Step Guide
Published:

Stratix Cup Draw Revealed: 16 AI Models, Four Groups, Two Wildcards
Published:

LangSmith Alternative: Vendor-Neutral LLM Evaluation
Published:

Add an AI Quality Gate to Your CI Pipeline in 15 Minutes
Published:
Llama 4 Scout on SWE-bench Lite (SWE-agent): 4.0% accuracy
Published:
Llama 4 Maverick on Humanity's Last Exam: 6.2% accuracy
Published:
Qwen2.5 72B Instruct on AIME 2025: 6.7% accuracy
Published:

The Operator Path: Running LayerLens in Production
Published:

From LangSmith to Stratix: A Migration Guide for Eval Pipelines
Published:

Judge Optimization with GEPA: How to Tune LLM Evaluation Prompts at Scale
Published:
Gemini 3.1 Flash Lite Preview on Humanity's Last Exam: 8.5% accuracy
Published:

How to Evaluate AI Models on SambaNova Cloud with LayerLens
Published:
Gemini 3.1 Flash Lite Preview on Terminal-Bench (Terminus-2): 17.5% accuracy
Published:
Llama 4 Maverick on AIME 2025: 20.0% accuracy
Published:
GPT-5 on Humanity's Last Exam: 21.7% accuracy
Published:
Claude Opus 4.7 on Humanity's Last Exam: 30.8% accuracy
Published:
DeepSeek V4 Flash on BIRD-CRITIC: 32.7% accuracy
Published:
Kimi K2.6 on BIRD-CRITIC: 33.3% accuracy
Published:
Claude Opus 4.6 on BIRD-CRITIC: 34.0% accuracy
Published:

RAG Evaluation Best Practices: A Complete Framework
Published:
Why AI Benchmarks Are Misleading (And What to Use Instead)
Published:
GPT-5 (high) on Terminal-Bench (Terminus-1): 46.2% accuracy
Published:

GPT-5.4 Benchmark Review: What Stratix Data Shows Across the Full Model Family
Published:
Claude Opus 4.6 on Terminal-Bench (Terminus-2): 58.8% accuracy
Published:

LLM Evaluation Frameworks: How to Choose the Right Approach
Published:

GLM-5 Benchmark Review: 20 Eval Runs, 13 Benchmarks, and the Data That Changed Between February and March
Published:
Claude Opus 4.5 on AIME 2025: 63.3% accuracy
Published:
Claude Opus 4.6 on AIME 2025: 70.0% accuracy
Published:
Claude Opus 4.7 on AIME 2026: 90.0% accuracy
Published:
GPT-5 (high) on AIME 2025: 90.0% accuracy
Published:

LLM Cost Optimization: What Actually Drives Production Spend
Published:

Gemini 3.1 Pro Benchmark Review: What 14,549 Tests Actually Reveal
Published:
DeepSeek V4 Pro on AIME 2026: 96.7% accuracy
Published:

LLM Observability for Production AI Systems
Published:

LLM Evaluation Framework for Enterprise AI
Published:

Stratix Cup Season 1 Semifinals and Final: Game Decided in Last Minute
Published:

The Stratix Cup: What Happens When Frontier Models Compete on Live Infrastructure
Published:

Stratix Cup Season 1 Is Live
Published:

Unit Test Pass Rate Is Not a Code Quality Signal
Published:

A history of games for AI/ML
Published:

Announcing the Stratix Cup
Published:

Gemini 3.5 Flash: Stratix Evaluation Data Reveals Where Google's Fastest Model Actually Wins
Published:

LayerLens and Subquadratic Announce Partnership to Enable Continuous, Transparent Evaluation of SubQ Models
Published:
Llama 4 Scout on Humanity's Last Exam: 4.3% accuracy
Published:

MLflow gives you the eval library. Production needs the platform.
Published:
Claude Opus 4.1 on Humanity's Last Exam: 7.3% accuracy
Published:

The Researcher Path: Evaluate Any AI Observability Platform in 56 Minutes
Published:

AI Evaluation Glossary: 25 Terms Every ML Team Needs in 2026
Published:

What Is Continuous Evaluation? A Working Definition for Production AI Teams
Published:

Advanced Agent Evaluation Patterns
Published:
Llama 4 Maverick on Terminal-Bench (Terminus-1): 8.8% accuracy
Published:
Gemini 3.1 Flash Lite Preview on Terminal-Bench (Terminus-1): 17.5% accuracy
Published:
GPT-5 (high) on Humanity's Last Exam: 21.4% accuracy
Published:
Claude Opus 4.1 on AIME 2025: 26.7% accuracy
Published:
Gemini 3.1 Pro Preview on Terminal-Bench (Terminus-1): 32.5% accuracy
Published:
Llama 4 Scout on LiveCodeBench: 33.2% accuracy
Published:
GPT-5 on Terminal-Bench (Terminus-1): 33.8% accuracy
Published:
Claude Opus 4.7 on BIRD-CRITIC: 36.3% accuracy
Published:

When Agents Fail: Why Evaluation Must Be Continuous
Published:
GPT-5 (high) on Terminal-Bench (Terminus-2): 42.5% accuracy
Published:
GPT-5 on SWE-bench Lite (SWE-agent): 47.3% accuracy
Published:
GPT-5 (high) on SWE-bench Lite (SWE-agent): 51.7% accuracy
Published:
Claude Opus 4.6 on SWE-bench Lite (SWE-agent): 62.7% accuracy
Published:

How to Evaluate AI Agents: Methods, Metrics, and Real-World Pitfalls
Published:
Claude Opus 4.1 on LiveCodeBench: 62.8% accuracy
Published:
Gemini 3.1 Flash Lite Preview on LiveCodeBench: 69.9% accuracy
Published:
Claude Opus 4.5 on LiveCodeBench: 76.8% accuracy
Published:
GLM 5.1 on AIME 2025: 90.0% accuracy
Published:

Moltbook Proved That the AI Agent Revolution Has a Governance Problem, Not a Readiness Problem
Published:
GLM 5.1 on AIME 2026: 93.3% accuracy
Published:
DeepSeek V4 Flash on AIME 2026: 96.7% accuracy
Published:

LLM Hallucination Detection in Production
Published:
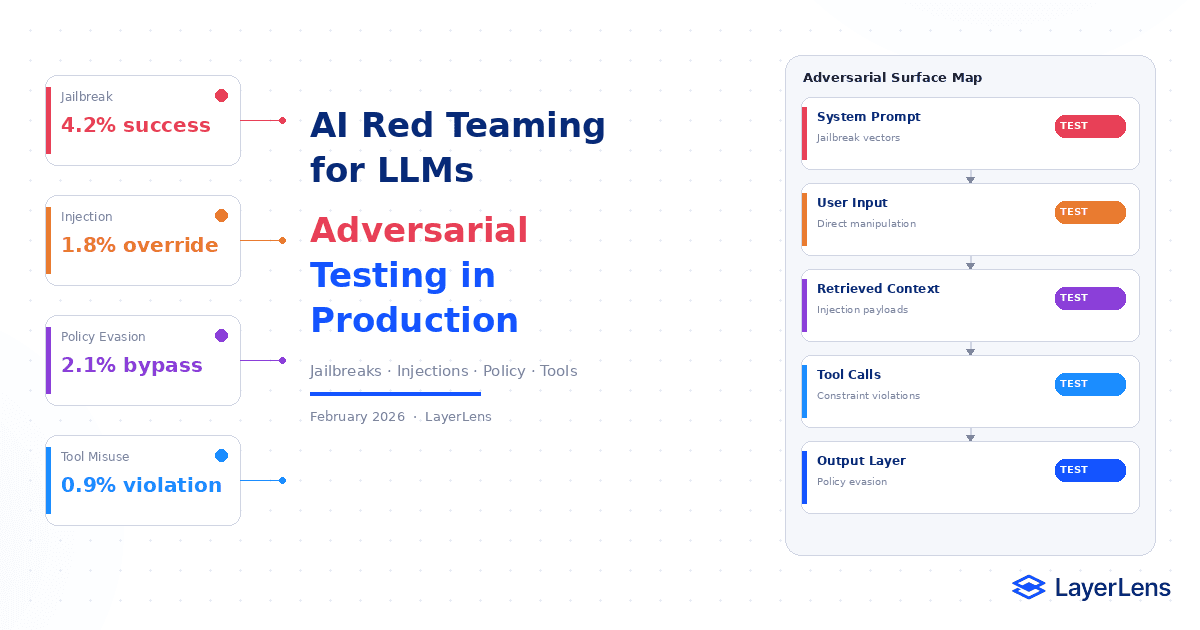
AI Red Teaming for LLMs in Production
Published:
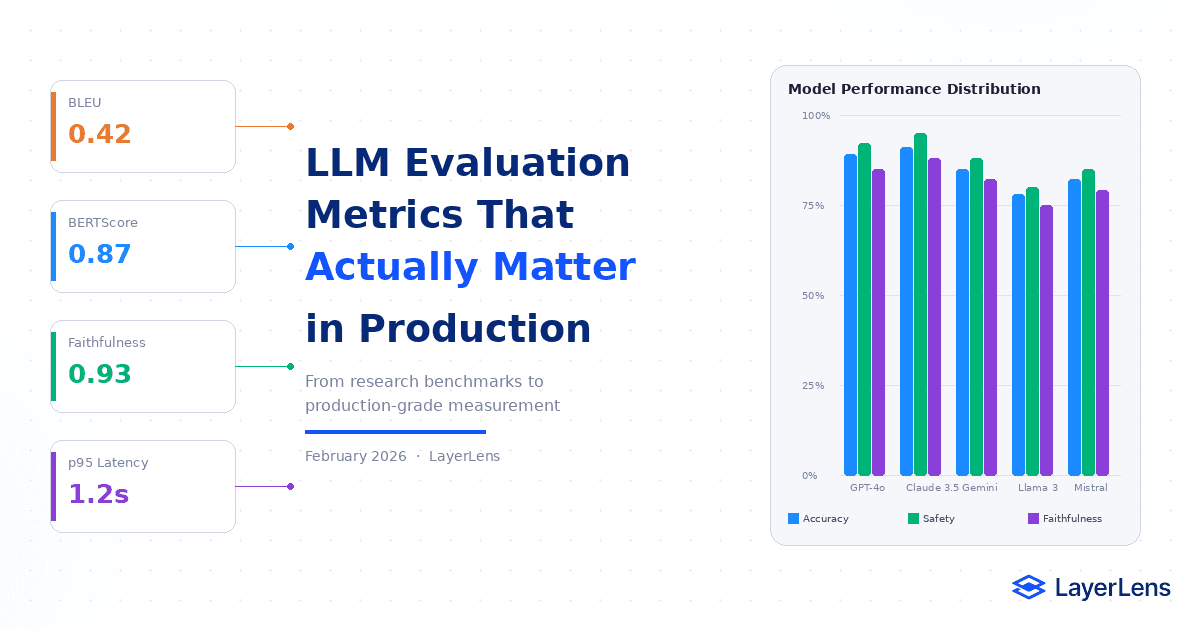
LLM Evaluation Metrics for Production Systems
Published:
Stratix Can Now Generate Synthetic Evaluation Data (Public Preview)
Published:
Quarterfinals Recap: The Group Winner That Ran Out of Time
Published:
Stratic Cup Day 2 Recap: Four Definitions of Adaptation
Published:
Under the Hood: How the Stratix Cup Actually Works
Published:
Eval Fatigue Is a Process Problem
Published:
Stop Building Your Own LLM Evaluation Framework
Published:
How to Detect LLM Regression in Production
Published:
How to Evaluate AI Agents in Production
Published:
Qwen2.5 72B Instruct on Humanity's Last Exam: 3.7% accuracy
Published:
AI Teams Are Repeating the Biggest Mistake in Software History
Published:
Llama 4 Scout on AIME 2025: 6.7% accuracy
Published:
Llama 4 Maverick on SWE-bench Lite (SWE-agent): 8.0% accuracy
Published:
The Builder Path: From First Trace to Production-Grade AI Evaluation
Published:
Step-Level Evaluation vs Output-Level Evaluation for AI Agent Traces
Published:
AgentGraph is Live: See Every Decision Your Agent Made
Published:
Llama 4 Scout on Terminal-Bench (Terminus-1): 8.8% accuracy
Published:
Claude Opus 4.5 on Humanity's Last Exam: 13.6% accuracy
Published:
Claude Opus 4.6 on Humanity's Last Exam: 18.6% accuracy
Published:
The Cost of Not Evaluating Your AI Agents
Published:
Gemini 3.1 Flash Lite Preview on AIME 2025: 30.0% accuracy
Published:
LLM Evaluation Metrics: What to Measure and Why
Published:
Q1 2026 Frontier Model Report: What the Release Cycle Broke in Your Evaluation Stack
Published:
What Is LLM Evaluation? The Complete Guide for 2026
Published:
Gemini 3.1 Pro Preview on Humanity's Last Exam: 40.6% accuracy
Published:
Xiaomi MiMo-V2 Evaluation: Benchmark Results Across 7 Tests on Stratix
Published:
Llama 4 Maverick on LiveCodeBench: 45.4% accuracy
Published:
Claude Opus 4.5 on SWE-bench Lite (SWE-agent): 49.3% accuracy
Published:
Kimi K2.6 on AIME 2025: 56.7% accuracy
Published:
AI Agent Testing: From Unit Tests to Production Monitoring
Published:
Partner Evaluation Spaces: Benchmark Models on Fireworks AI and Nebius Infrastructure
Published:
Kimi K2.6 on AIME 2026: 63.3% accuracy
Published:
Gemini 3.1 Flash Lite Benchmark Results vs. GPT-5 Nano, Qwen3.5: Efficiency Model Comparison
Published:
GPT-5 on LiveCodeBench: 81.7% accuracy
Published:
Introducing Judge Optimization on Stratix Enterprise: Close the Gap Between Automated Scores and Human Judgment
Published:
Gemini 3.1 Pro Preview on AIME 2025: 93.3% accuracy
Published:
AI Quality Assurance for LLM Systems: Why Traditional QA Breaks
Published:
GPT-5 on AIME 2025: 96.7% accuracy
Published:
AI Model Comparison in Production
Published:
RAG Evaluation Framework for Production AI Systems
Published:
LLM Evaluation Framework for Production
Published:
Stratix Cup Season 1: Six Rounds of LLM Self-Improvement in Public
Published:
Stratix Cup Day 3 Recap: 16 Teams. 8 Eliminated today.
Published:
Matchday 1 Recap: What the Traces Actually Showed
Published:
The Compounding Math Engineers Miss When They Dismiss Agent Failures
Published:
How to Evaluate LLM Agents: A Step-by-Step Guide
Published:
Stratix Cup Draw Revealed: 16 AI Models, Four Groups, Two Wildcards
Published:
LangSmith Alternative: Vendor-Neutral LLM Evaluation
Published:
Add an AI Quality Gate to Your CI Pipeline in 15 Minutes
Published:
Llama 4 Scout on SWE-bench Lite (SWE-agent): 4.0% accuracy
Published:
Llama 4 Maverick on Humanity's Last Exam: 6.2% accuracy
Published:
Qwen2.5 72B Instruct on AIME 2025: 6.7% accuracy
Published:
The Operator Path: Running LayerLens in Production
Published:
From LangSmith to Stratix: A Migration Guide for Eval Pipelines
Published:
Judge Optimization with GEPA: How to Tune LLM Evaluation Prompts at Scale
Published:
Gemini 3.1 Flash Lite Preview on Humanity's Last Exam: 8.5% accuracy
Published:
How to Evaluate AI Models on SambaNova Cloud with LayerLens
Published:
Gemini 3.1 Flash Lite Preview on Terminal-Bench (Terminus-2): 17.5% accuracy
Published:
Llama 4 Maverick on AIME 2025: 20.0% accuracy
Published:
GPT-5 on Humanity's Last Exam: 21.7% accuracy
Published:
Claude Opus 4.7 on Humanity's Last Exam: 30.8% accuracy
Published:
DeepSeek V4 Flash on BIRD-CRITIC: 32.7% accuracy
Published:
Kimi K2.6 on BIRD-CRITIC: 33.3% accuracy
Published:
Claude Opus 4.6 on BIRD-CRITIC: 34.0% accuracy
Published:
RAG Evaluation Best Practices: A Complete Framework
Published:
Why AI Benchmarks Are Misleading (And What to Use Instead)
Published:
GPT-5 (high) on Terminal-Bench (Terminus-1): 46.2% accuracy
Published:
GPT-5.4 Benchmark Review: What Stratix Data Shows Across the Full Model Family
Published:
Claude Opus 4.6 on Terminal-Bench (Terminus-2): 58.8% accuracy
Published:
LLM Evaluation Frameworks: How to Choose the Right Approach
Published:
GLM-5 Benchmark Review: 20 Eval Runs, 13 Benchmarks, and the Data That Changed Between February and March
Published:
Claude Opus 4.5 on AIME 2025: 63.3% accuracy
Published:
Claude Opus 4.6 on AIME 2025: 70.0% accuracy
Published:
Claude Opus 4.7 on AIME 2026: 90.0% accuracy
Published:
GPT-5 (high) on AIME 2025: 90.0% accuracy
Published:
LLM Cost Optimization: What Actually Drives Production Spend
Published:
Gemini 3.1 Pro Benchmark Review: What 14,549 Tests Actually Reveal
Published:
DeepSeek V4 Pro on AIME 2026: 96.7% accuracy
Published:
LLM Observability for Production AI Systems
Published:
LLM Evaluation Framework for Enterprise AI
Published:
Stratix Cup Season 1 Semifinals and Final: Game Decided in Last Minute
Published:
The Stratix Cup: What Happens When Frontier Models Compete on Live Infrastructure
Published:
Stratix Cup Season 1 Is Live
Published:
Unit Test Pass Rate Is Not a Code Quality Signal
Published:
A history of games for AI/ML
Published:
Announcing the Stratix Cup
Published:
Gemini 3.5 Flash: Stratix Evaluation Data Reveals Where Google's Fastest Model Actually Wins
Published:
LayerLens and Subquadratic Announce Partnership to Enable Continuous, Transparent Evaluation of SubQ Models
Published:
Llama 4 Scout on Humanity's Last Exam: 4.3% accuracy
Published:
MLflow gives you the eval library. Production needs the platform.
Published:
Claude Opus 4.1 on Humanity's Last Exam: 7.3% accuracy
Published:
The Researcher Path: Evaluate Any AI Observability Platform in 56 Minutes
Published:
AI Evaluation Glossary: 25 Terms Every ML Team Needs in 2026
Published:
What Is Continuous Evaluation? A Working Definition for Production AI Teams
Published:
Advanced Agent Evaluation Patterns
Published:
Llama 4 Maverick on Terminal-Bench (Terminus-1): 8.8% accuracy
Published:
Gemini 3.1 Flash Lite Preview on Terminal-Bench (Terminus-1): 17.5% accuracy
Published:
GPT-5 (high) on Humanity's Last Exam: 21.4% accuracy
Published:
Claude Opus 4.1 on AIME 2025: 26.7% accuracy
Published:
Gemini 3.1 Pro Preview on Terminal-Bench (Terminus-1): 32.5% accuracy
Published:
Llama 4 Scout on LiveCodeBench: 33.2% accuracy
Published:
GPT-5 on Terminal-Bench (Terminus-1): 33.8% accuracy
Published:
Claude Opus 4.7 on BIRD-CRITIC: 36.3% accuracy
Published:
When Agents Fail: Why Evaluation Must Be Continuous
Published:
GPT-5 (high) on Terminal-Bench (Terminus-2): 42.5% accuracy
Published:
GPT-5 on SWE-bench Lite (SWE-agent): 47.3% accuracy
Published:
GPT-5 (high) on SWE-bench Lite (SWE-agent): 51.7% accuracy
Published:
Claude Opus 4.6 on SWE-bench Lite (SWE-agent): 62.7% accuracy
Published:
How to Evaluate AI Agents: Methods, Metrics, and Real-World Pitfalls
Published:
Claude Opus 4.1 on LiveCodeBench: 62.8% accuracy
Published:
Gemini 3.1 Flash Lite Preview on LiveCodeBench: 69.9% accuracy
Published:
Claude Opus 4.5 on LiveCodeBench: 76.8% accuracy
Published:
GLM 5.1 on AIME 2025: 90.0% accuracy
Published:
Moltbook Proved That the AI Agent Revolution Has a Governance Problem, Not a Readiness Problem
Published:
GLM 5.1 on AIME 2026: 93.3% accuracy
Published:
DeepSeek V4 Flash on AIME 2026: 96.7% accuracy
Published:
LLM Hallucination Detection in Production
Published:
AI Red Teaming for LLMs in Production
Published:
LLM Evaluation Metrics for Production Systems
Published:
Stratix Can Now Generate Synthetic Evaluation Data (Public Preview)
Published:
Stratix Cup Season 1: Six Rounds of LLM Self-Improvement in Public
Published:
Stratix Cup Season 1 Semifinals and Final: Game Decided in Last Minute
Published:
Quarterfinals Recap: The Group Winner That Ran Out of Time
Published:
Stratix Cup Day 3 Recap: 16 Teams. 8 Eliminated today.
Published:
The Stratix Cup: What Happens When Frontier Models Compete on Live Infrastructure
Published:
Stratic Cup Day 2 Recap: Four Definitions of Adaptation
Published:
Matchday 1 Recap: What the Traces Actually Showed
Published:
Stratix Cup Season 1 Is Live
Published:
Under the Hood: How the Stratix Cup Actually Works
Published:
The Compounding Math Engineers Miss When They Dismiss Agent Failures
Published:
Unit Test Pass Rate Is Not a Code Quality Signal
Published:
Eval Fatigue Is a Process Problem
Published:
How to Evaluate LLM Agents: A Step-by-Step Guide
Published:
A history of games for AI/ML
Published:
Stop Building Your Own LLM Evaluation Framework
Published:
Stratix Cup Draw Revealed: 16 AI Models, Four Groups, Two Wildcards
Published:
Announcing the Stratix Cup
Published:
How to Detect LLM Regression in Production
Published:
LangSmith Alternative: Vendor-Neutral LLM Evaluation
Published:
Gemini 3.5 Flash: Stratix Evaluation Data Reveals Where Google's Fastest Model Actually Wins
Published:
How to Evaluate AI Agents in Production
Published:
Add an AI Quality Gate to Your CI Pipeline in 15 Minutes
Published:
LayerLens and Subquadratic Announce Partnership to Enable Continuous, Transparent Evaluation of SubQ Models
Published:
Qwen2.5 72B Instruct on Humanity's Last Exam: 3.7% accuracy
Published:
Llama 4 Scout on SWE-bench Lite (SWE-agent): 4.0% accuracy
Published:
Llama 4 Scout on Humanity's Last Exam: 4.3% accuracy
Published:
AI Teams Are Repeating the Biggest Mistake in Software History
Published:
Llama 4 Maverick on Humanity's Last Exam: 6.2% accuracy
Published:
MLflow gives you the eval library. Production needs the platform.
Published:
Llama 4 Scout on AIME 2025: 6.7% accuracy
Published:
Qwen2.5 72B Instruct on AIME 2025: 6.7% accuracy
Published:
Claude Opus 4.1 on Humanity's Last Exam: 7.3% accuracy
Published:
Llama 4 Maverick on SWE-bench Lite (SWE-agent): 8.0% accuracy
Published:
The Operator Path: Running LayerLens in Production
Published:
The Researcher Path: Evaluate Any AI Observability Platform in 56 Minutes
Published:
The Builder Path: From First Trace to Production-Grade AI Evaluation
Published:
From LangSmith to Stratix: A Migration Guide for Eval Pipelines
Published:
AI Evaluation Glossary: 25 Terms Every ML Team Needs in 2026
Published:
Step-Level Evaluation vs Output-Level Evaluation for AI Agent Traces
Published:
Judge Optimization with GEPA: How to Tune LLM Evaluation Prompts at Scale
Published:
What Is Continuous Evaluation? A Working Definition for Production AI Teams
Published:
AgentGraph is Live: See Every Decision Your Agent Made
Published:
Gemini 3.1 Flash Lite Preview on Humanity's Last Exam: 8.5% accuracy
Published:
Advanced Agent Evaluation Patterns
Published:
Llama 4 Scout on Terminal-Bench (Terminus-1): 8.8% accuracy
Published:
How to Evaluate AI Models on SambaNova Cloud with LayerLens
Published:
Llama 4 Maverick on Terminal-Bench (Terminus-1): 8.8% accuracy
Published:
Claude Opus 4.5 on Humanity's Last Exam: 13.6% accuracy
Published:
Gemini 3.1 Flash Lite Preview on Terminal-Bench (Terminus-2): 17.5% accuracy
Published:
Gemini 3.1 Flash Lite Preview on Terminal-Bench (Terminus-1): 17.5% accuracy
Published:
Claude Opus 4.6 on Humanity's Last Exam: 18.6% accuracy
Published:
Llama 4 Maverick on AIME 2025: 20.0% accuracy
Published:
GPT-5 (high) on Humanity's Last Exam: 21.4% accuracy
Published:
The Cost of Not Evaluating Your AI Agents
Published:
GPT-5 on Humanity's Last Exam: 21.7% accuracy
Published:
Claude Opus 4.1 on AIME 2025: 26.7% accuracy
Published:
Gemini 3.1 Flash Lite Preview on AIME 2025: 30.0% accuracy
Published:
Claude Opus 4.7 on Humanity's Last Exam: 30.8% accuracy
Published:
Gemini 3.1 Pro Preview on Terminal-Bench (Terminus-1): 32.5% accuracy
Published:
LLM Evaluation Metrics: What to Measure and Why
Published:
DeepSeek V4 Flash on BIRD-CRITIC: 32.7% accuracy
Published:
Llama 4 Scout on LiveCodeBench: 33.2% accuracy
Published:
Q1 2026 Frontier Model Report: What the Release Cycle Broke in Your Evaluation Stack
Published:
Kimi K2.6 on BIRD-CRITIC: 33.3% accuracy
Published:
GPT-5 on Terminal-Bench (Terminus-1): 33.8% accuracy
Published:
What Is LLM Evaluation? The Complete Guide for 2026
Published:
Claude Opus 4.6 on BIRD-CRITIC: 34.0% accuracy
Published:
Claude Opus 4.7 on BIRD-CRITIC: 36.3% accuracy
Published:
Gemini 3.1 Pro Preview on Humanity's Last Exam: 40.6% accuracy
Published:
RAG Evaluation Best Practices: A Complete Framework
Published:
When Agents Fail: Why Evaluation Must Be Continuous
Published:
Xiaomi MiMo-V2 Evaluation: Benchmark Results Across 7 Tests on Stratix
Published:
Why AI Benchmarks Are Misleading (And What to Use Instead)
Published:
GPT-5 (high) on Terminal-Bench (Terminus-2): 42.5% accuracy
Published:
Llama 4 Maverick on LiveCodeBench: 45.4% accuracy
Published:
GPT-5 (high) on Terminal-Bench (Terminus-1): 46.2% accuracy
Published:
GPT-5 on SWE-bench Lite (SWE-agent): 47.3% accuracy
Published:
Claude Opus 4.5 on SWE-bench Lite (SWE-agent): 49.3% accuracy
Published:
GPT-5.4 Benchmark Review: What Stratix Data Shows Across the Full Model Family
Published:
GPT-5 (high) on SWE-bench Lite (SWE-agent): 51.7% accuracy
Published:
Kimi K2.6 on AIME 2025: 56.7% accuracy
Published:
Claude Opus 4.6 on Terminal-Bench (Terminus-2): 58.8% accuracy
Published:
Claude Opus 4.6 on SWE-bench Lite (SWE-agent): 62.7% accuracy
Published:
AI Agent Testing: From Unit Tests to Production Monitoring
Published:
LLM Evaluation Frameworks: How to Choose the Right Approach
Published:
How to Evaluate AI Agents: Methods, Metrics, and Real-World Pitfalls
Published:
Partner Evaluation Spaces: Benchmark Models on Fireworks AI and Nebius Infrastructure
Published:
GLM-5 Benchmark Review: 20 Eval Runs, 13 Benchmarks, and the Data That Changed Between February and March
Published:
Claude Opus 4.1 on LiveCodeBench: 62.8% accuracy
Published:
Kimi K2.6 on AIME 2026: 63.3% accuracy
Published:
Claude Opus 4.5 on AIME 2025: 63.3% accuracy
Published:
Gemini 3.1 Flash Lite Preview on LiveCodeBench: 69.9% accuracy
Published:
Gemini 3.1 Flash Lite Benchmark Results vs. GPT-5 Nano, Qwen3.5: Efficiency Model Comparison
Published:
Claude Opus 4.6 on AIME 2025: 70.0% accuracy
Published:
Claude Opus 4.5 on LiveCodeBench: 76.8% accuracy
Published:
GPT-5 on LiveCodeBench: 81.7% accuracy
Published:
Claude Opus 4.7 on AIME 2026: 90.0% accuracy
Published:
GLM 5.1 on AIME 2025: 90.0% accuracy
Published:
Introducing Judge Optimization on Stratix Enterprise: Close the Gap Between Automated Scores and Human Judgment
Published:
GPT-5 (high) on AIME 2025: 90.0% accuracy
Published:
Moltbook Proved That the AI Agent Revolution Has a Governance Problem, Not a Readiness Problem
Published:
Gemini 3.1 Pro Preview on AIME 2025: 93.3% accuracy
Published:
LLM Cost Optimization: What Actually Drives Production Spend
Published:
GLM 5.1 on AIME 2026: 93.3% accuracy
Published:
AI Quality Assurance for LLM Systems: Why Traditional QA Breaks
Published:
Gemini 3.1 Pro Benchmark Review: What 14,549 Tests Actually Reveal
Published:
DeepSeek V4 Flash on AIME 2026: 96.7% accuracy
Published:
GPT-5 on AIME 2025: 96.7% accuracy
Published:
DeepSeek V4 Pro on AIME 2026: 96.7% accuracy
Published:
LLM Hallucination Detection in Production
Published:
AI Model Comparison in Production
Published:
LLM Observability for Production AI Systems
Published:
AI Red Teaming for LLMs in Production
Published:
RAG Evaluation Framework for Production AI Systems
Published:
LLM Evaluation Framework for Enterprise AI
Published:
LLM Evaluation Metrics for Production Systems
Published:
LLM Evaluation Framework for Production
Published: