
LLM Evaluation Metrics for Production Systems
Author:
Jake Meany (Dir. of Marketing, LayerLens)
Last updated:
Published:
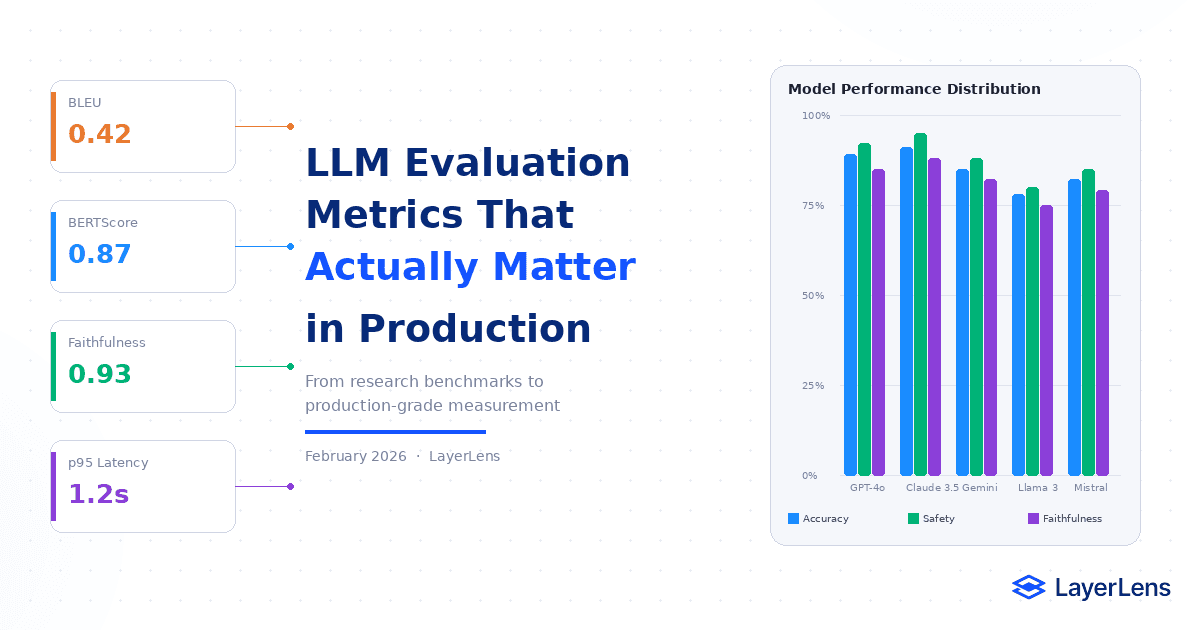
LLM evaluation metrics measure model performance across accuracy, safety, latency, cost, and robustness.
Token-overlap metrics such as BLEU and ROUGE often fail to predict production reliability.
Production systems require a portfolio of task-specific accuracy, safety, latency, and cost metrics aligned directly to business KPIs.
LLM evaluation metrics determine whether a model is ready for production deployment. They measure how well a large language model performs across task accuracy, semantic consistency, safety, latency, cost, and robustness under real conditions.
Many teams still default to metrics inherited from academic benchmarking. Those metrics were designed for comparability across papers, not for production reliability.
Metric misalignment causes deployment regressions. A model optimized for BLEU or ROUGE can score well on static datasets and degrade under real workloads.
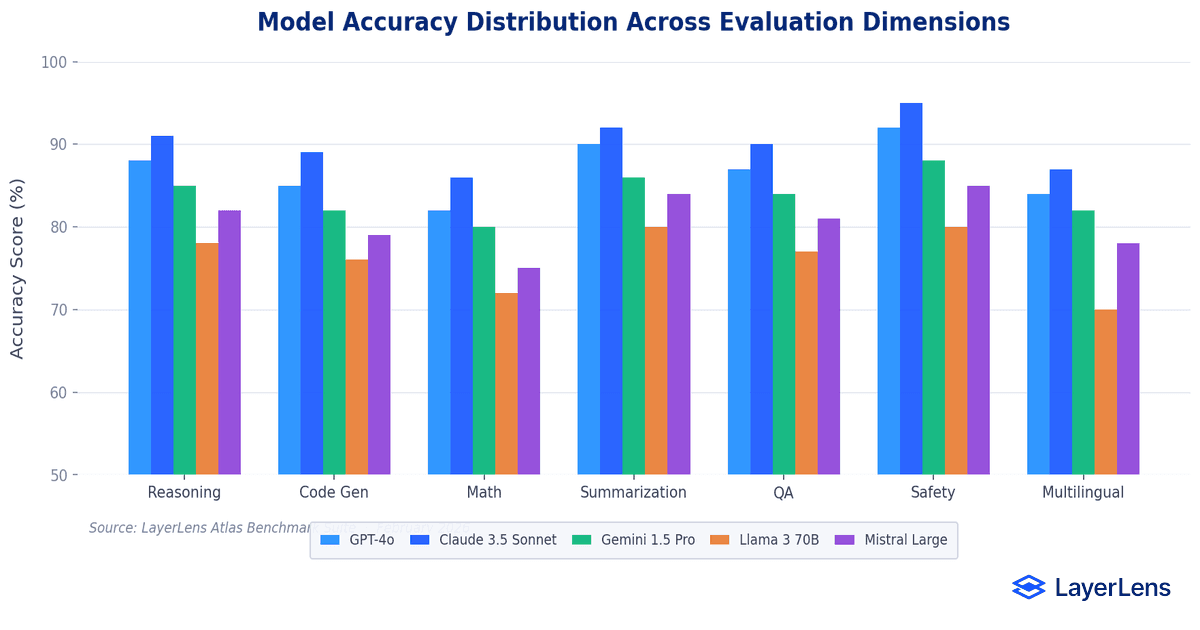
Model performance varies significantly across benchmark categories.
What Are LLM Evaluation Metrics?
LLM evaluation metrics are structured measures that assess model output quality across multiple dimensions, including:
Task-specific correctness
Semantic similarity
Factual grounding
Safety and alignment
Latency distribution
Cost per request
They range from automated overlap scores to model-based judges and human review pipelines.
LayerLens provides structured benchmark coverage across 200+ benchmark categories (explore benchmark coverage on LayerLens).
Why Is Accuracy Alone Insufficient?
Accuracy alone does not predict deployment value.
A model can achieve strong benchmark accuracy while failing latency and cost constraints under production workloads. Multi-dimensional evaluation outperforms single-metric optimization.
Production decisions require joint visibility into:
Task-specific accuracy
Latency percentiles (p50, p95, p99)
Cost per request
Safety violation rate
Robustness under adversarial prompts
Teams can evaluate these tradeoffs directly using LayerLens dashboards (compare LLM evaluation metrics across 200+ models).
Core LLM Metrics for Production Systems
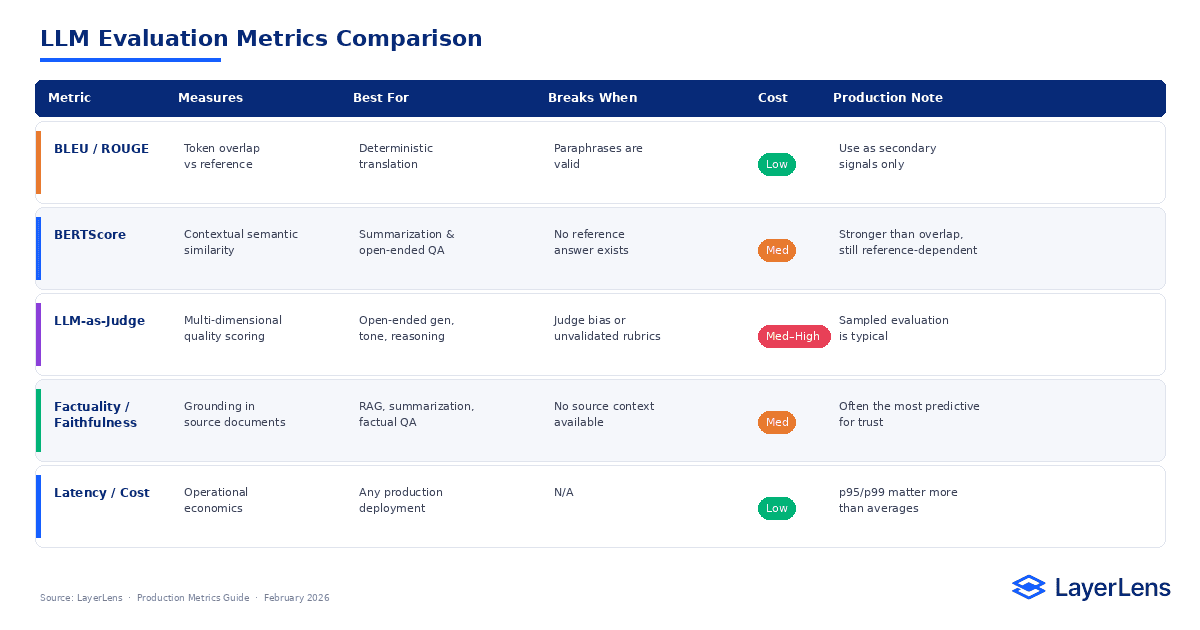
Token Overlap Metrics
BLEU and ROUGE measure n-gram overlap between generated output and reference answers. They are useful when exact references matter, such as deterministic translation tasks, but penalize valid paraphrases and do not measure semantic correctness.
Semantic Similarity Metrics
BERTScore measures contextual similarity using transformer embeddings. It captures meaning beyond token overlap but remains reference-dependent.
Factuality and Faithfulness Metrics
Truthfulness benchmarks measure whether models generate plausible but false claims. Faithfulness scoring evaluates whether outputs are grounded in source documents, critical in RAG and summarization systems (factual consistency research).
LLM-as-Judge Metrics
LLM-as-judge evaluation uses a capable model to score outputs across relevance, coherence, factuality, and safety dimensions. Properly validated judge systems correlate strongly with human judgment. Because judge scoring incurs cost, production systems often apply it to sampled traffic.
Task-Specific Metrics
Summarization → ROUGE + BERTScore + faithfulness
Question answering → Exact Match + F1 + factuality
Code generation → execution pass rate + functional correctness
Classification → accuracy + macro-F1
RAG → Recall@K + end-to-end accuracy + faithfulness
How Should You Choose LLM Metrics for Production?
Use a portfolio strategy.
Define the business outcome tied to the task.
Select 2–3 primary metrics that directly measure that outcome.
Add secondary metrics for nuance and failure decomposition.
Include safety and robustness metrics explicitly.
Validate offline metric performance against real production behavior.
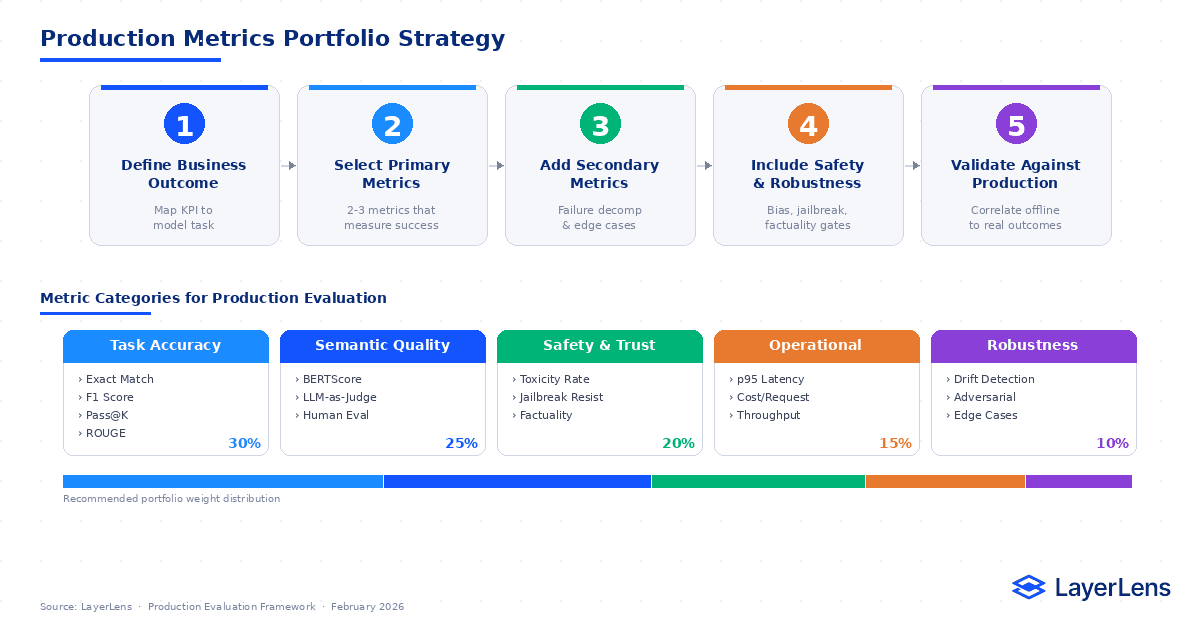
If metrics do not correlate with production outcomes, replace them.
For the full lifecycle framework that operationalizes these metrics, see the LLM evaluation framework guide (https://layerlens.ai/blog/llm-evaluation-framework-production).
LayerLens supports this workflow through structured evaluation dashboards.
What Are the Most Common LLM Metric Mistakes?
Optimizing for token overlap rather than task success
Relying on a single metric
Ignoring cost-per-quality tradeoffs
Failing to monitor distribution shift after deployment
Treating leaderboard position as deployment validation
Frequently Asked Questions
What is the difference between BLEU and BERTScore?
BLEU measures token overlap between generated text and a reference answer. BERTScore measures contextual semantic similarity using embeddings and handles paraphrasing more reliably for open-ended tasks.
What is LLM-as-judge evaluation?
LLM-as-judge uses a capable model to evaluate another model’s output across dimensions such as relevance, factuality, coherence, and safety. It works best with defined rubrics and periodic validation against human review.
How do you measure LLM safety in production?
Measure safety with toxicity classifiers, jailbreak tests, bias probes, and factuality checks. Track a safety violation rate over time and tie thresholds directly to deployment gates and rollback triggers.
What metrics should you use for RAG evaluation?
Use retrieval metrics (Recall@K, Precision@K), end-to-end answer accuracy, and faithfulness scoring to verify answers are grounded in retrieved documents. Retrieval and generation should be evaluated separately to localize failures.
How often should LLM evaluation metrics be recalibrated?
Validate metric predictiveness monthly and refresh benchmark coverage quarterly, or sooner when production drift is detected. If offline scores stop correlating with real outcomes, recalibrate the metric portfolio.
Conclusion: From Research Metrics to Production Metrics
LLM evaluation metrics designed for academic comparison often fail under real deployment constraints. Production systems require portfolios aligned with task accuracy, safety thresholds, latency limits, cost boundaries, and robustness under adversarial input.
Metric strategy should operate as decision infrastructure. When metrics are tied to deployment gates, teams reduce regressions, detect drift earlier, and make defensible model selection decisions. The goal is focus on production control, not ranking score.
For enterprise teams managing multi-model evaluation across systems, Stratix Premium by LayerLens provides integrated monitoring and governance workflows.
Key Takeaways
Effective LLM evaluation metrics:
Align directly to business KPIs
Use multi-dimensional measurement
Include safety and robustness explicitly
Validate offline results against production outcomes
Connect metrics to deployment governance