
LLM Evaluation Framework for Enterprise AI
Author:
Jake Meany (Dir. of Marketing, LayerLens)
Last updated:
Published:

An LLM evaluation framework is the system that governs model quality before and after deployment.
It connects benchmarks, domain datasets, deployment gates, shadow validation, continuous monitoring, drift detection, and governance into a structured control layer for enterprise AI.
Most teams think they have evaluation because they run benchmarks. In reality, they have generic comparison data, not production-grade control over their agent or agentic workflow.
A production-grade LLM evaluation framework defines what acceptable performance means before release, validates candidates under realistic conditions, and ties measurable thresholds directly to deployment authority. Multi-dimensional evaluation research shows that single-score benchmarking fails to capture real-world reliability.
[IMG PENDING HERE
Diagram of an LLM evaluation framework lifecycle including gating, shadow deployment, monitoring, and governance
What Is an LLM Evaluation Framework?
An LLM evaluation framework is a structured methodology for measuring and governing model performance across accuracy, safety, latency, cost, and robustness.
The framework answers:
Is this model production-ready?
Should we deploy or rollback?
Which model best fits this workload?
How do we detect drift?
Where does the model degrade?
Benchmarks, domain datasets, automated scoring, statistical monitoring, and governance rules work together as a unified control system.
For a metric-level breakdown that feeds into this system, see our guide to LLM evaluation metrics that actually matter.
Why Do Enterprises Need a Structured Evaluation Framework?
Benchmark success does not equal production reliability.
Academic benchmarks measure fixed datasets. Production systems operate under evolving inputs, adversarial prompting, infrastructure constraints, and distribution shift (distribution shift research: https://arxiv.org/abs/2203.14997). Task misalignment compounds this issue; models can score highly on academic tasks while underperforming on domain-specific workloads (benchmark misalignment analysis: https://arxiv.org/abs/2308.02014).
In practice, this gap shows up as subtle degradation. A model may retain 94% task accuracy while latency rises from 1.2 seconds to 3.8 seconds at p95 under real traffic. That shift alone can change the economic viability of deployment.
A structured LLM evaluation framework forces explicit alignment between business KPIs and measurable evaluation dimensions.
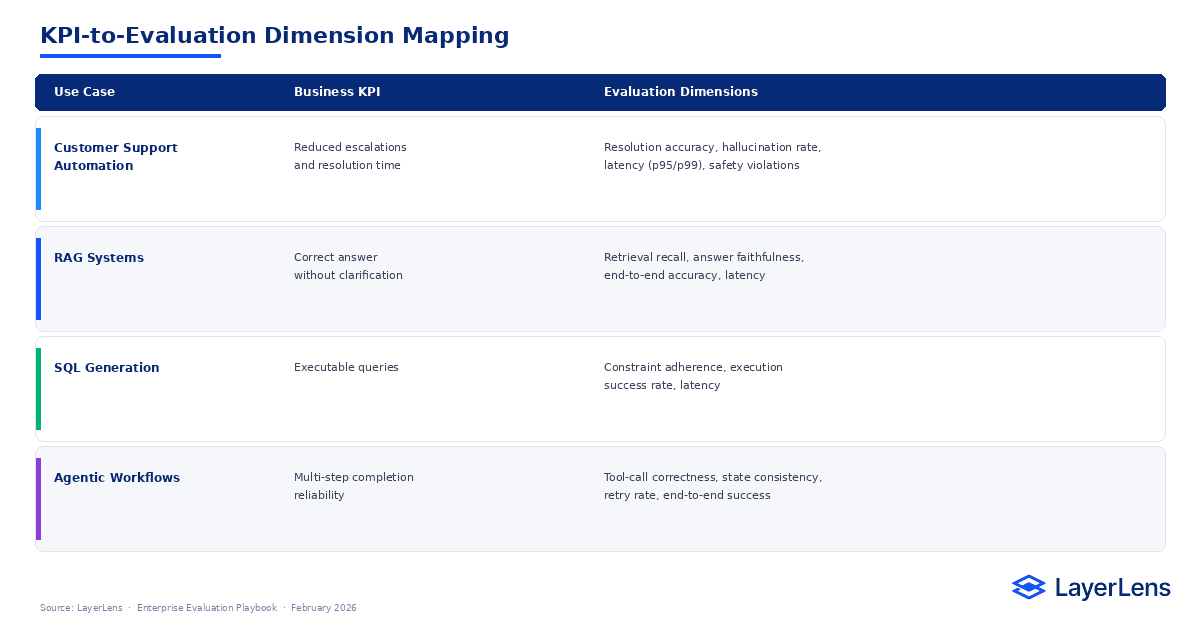
How Do You Map Business KPIs to Evaluation Dimensions?
Start with the business outcome.
Then map it directly to evaluation dimensions.
Customer Support Automation
Business KPI: Reduced escalations and resolution time
Evaluation Dimensions: Resolution accuracy, hallucination rate, latency (p95/p99), safety violations
RAG Systems
Business KPI: Correct answer without clarification
Evaluation Dimensions: Retrieval recall, answer faithfulness, end-to-end accuracy, latency
SQL Generation
Business KPI: Executable queries
Evaluation Dimensions: Constraint adherence, execution success rate, latency
Agentic Workflows
Business KPI: Multi-step completion reliability
Evaluation Dimensions: Tool-call correctness, state consistency, retry rate
Every evaluation dimension must connect to operational risk. If a metric shifts, someone should be able to explain the business impact.
LayerLens benchmark coverage exists across 200+ benchmark categories provides structured baselines for many of these evaluation dimensions.
What Does a Production Evaluation Pipeline Look Like?
A mature LLM evaluation framework operates across three layers.
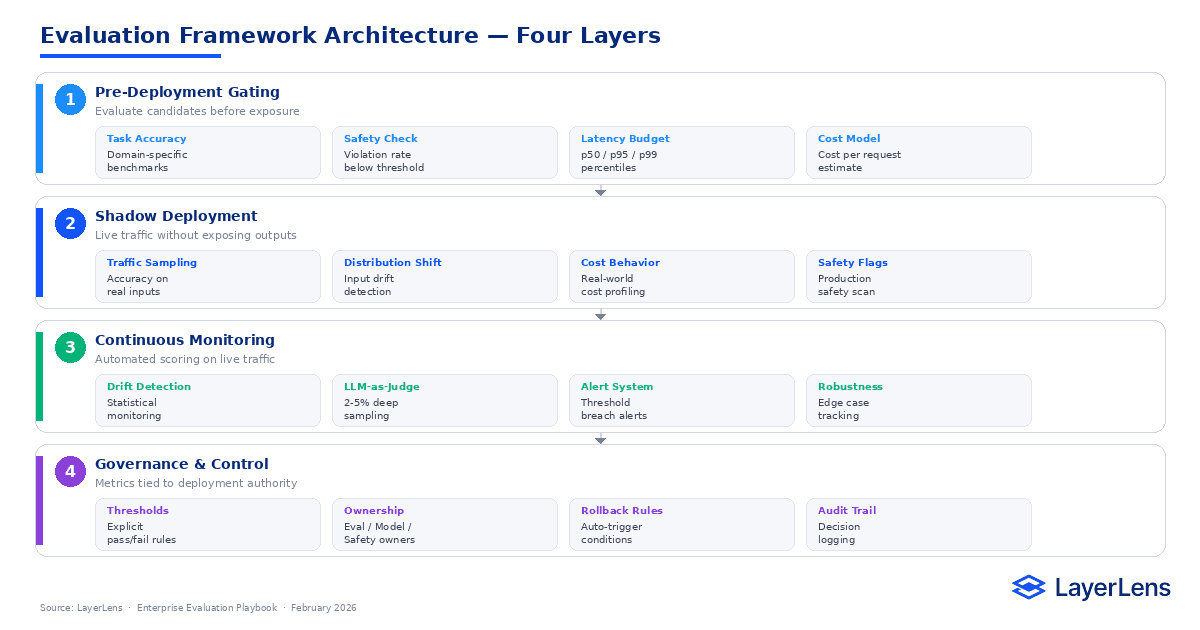
Pre-Deployment Gating
Evaluate candidates before exposure.
Measure:
Task-specific accuracy
Safety violations
Latency percentiles (p50, p95, p99)
Cost per request
Define explicit thresholds. Candidates that fail gating criteria do not deploy.
Structured side-by-side model comparison across these LLM metrics can be performed using LayerLens comparison dashboards.
Shadow Deployment
Shadow deployment runs a candidate model on live traffic without exposing outputs.
It establishes real-world baselines and surfaces distribution shift before public rollout.
Log:
Accuracy on sampled traffic
Latency and cost behavior
Safety flags
Input distribution changes
Continuous Evaluation
Evaluation continues after deployment.
Run automated scoring on live traffic. Sample 2–5% for deeper review using LLM-as-judge methods.
Implement statistical drift detection across accuracy, safety, latency, and cost.
LayerLens evaluation dashboards support ongoing monitoring and model comparison across production systems.
Which LLM Metrics Map to Each Pipeline Stage?
Pre-deployment focuses on task accuracy, safety violations, and cost modeling.
Shadow deployment emphasizes real-traffic accuracy and latency distribution under production load.
Continuous monitoring prioritizes statistical drift metrics, robustness signals, and safety spikes.
Governance enforces threshold compliance across all measured dimensions.
Each stage emphasizes different LLM metrics because the failure surface shifts over time. Pre-deployment evaluates candidate suitability. Shadow deployment reveals distribution sensitivity. Continuous monitoring detects degradation. Governance enforces control.

How Does Governance Turn Metrics into Control?
Metrics without authority remain diagnostics.
Governance defines explicit rules:
Accuracy drop greater than threshold → investigation
Safety violation rate exceeds threshold → rollback
p99 latency breaches SLO → restrict rollout
Assign ownership:
Evaluation Owner
Model Owner
Safety Reviewer
Product Owner
Governance ensures that performance degradation triggers action rather than debate.
For organizations requiring integrated lifecycle gating and monitoring at scale, Stratix Premium supports evaluation governance across full model portfolios.
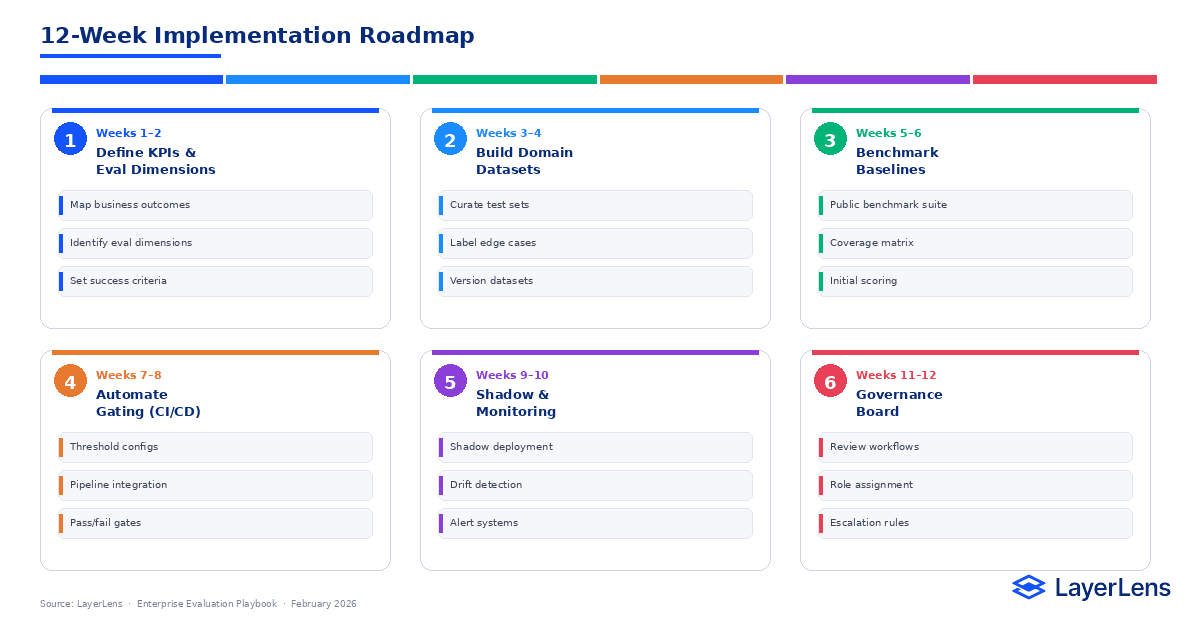
What Is a Realistic 12-Week Implementation Plan?
Weeks 1–2
Define KPIs and evaluation dimensions.
Weeks 3–4
Build domain datasets and label edge cases.
Weeks 5–6
Integrate public benchmark baselines and establish coverage matrix.
Weeks 7–8
Automate pre-deployment gating in CI/CD.
Weeks 9–10
Implement shadow validation and continuous monitoring.
Weeks 11–12
Establish governance board and deployment review workflow.
Conclusion: Evaluation as Control Infrastructure
An LLM evaluation framework transforms measurement into operational control.
It aligns performance metrics with business objectives, validates candidates before exposure, monitors behavior under real conditions, detects degradation statistically, and enforces deployment authority through governance.
Organizations that implement structured evaluation frameworks detect regressions earlier, reduce rollback cycles, and make defensible model selection decisions. Evaluation becomes infrastructure rather than an afterthought.
Frequently Asked Questions
What is the difference between a benchmark and an LLM evaluation framework?
A benchmark measures performance on a dataset. An evaluation framework defines how benchmarks, monitoring, thresholds, and governance work together to control deployment decisions.
How often should evaluation datasets be updated?
Quarterly at minimum, and immediately after recurring production failure patterns. Production incidents should inform dataset updates.
Why is shadow deployment necessary?
Shadow deployment measures model behavior on live traffic without exposing outputs, revealing distribution shift and hidden failure modes before rollout.
What metrics matter most in enterprise evaluation?
Task accuracy, safety violations, p95/p99 latency, cost per request, and robustness under edge cases.