Q1 2026 Frontier Model Report: What the Release Cycle Broke in Your Evaluation Stack
Author:
The LayerLens Team
Last updated:
Published:
Author Bio
Jake Meany is a digital marketing leader who has built and scaled marketing programs across B2B, Web3, and emerging tech. He holds an M.S. in Digital Social Media from USC Annenberg and leads marketing at LayerLens.
Executive Summary
Between January and March 2026, every major AI company released new models within six weeks of each other. LayerLens tested over 200 of them on Stratix, its platform for running standardized tests against AI models and comparing the results. This report covers what we found.
The short version: no company won. Google's model led one test. Anthropic's led another. xAI's led a third. OpenAI and others traded positions depending on the task. On the tests that get the most media attention, like math and general knowledge, the top models are now so close together that the differences are smaller than normal measurement variation. Ranking them is not meaningful.
This report also looks at what happens when AI models are used to grade other AI models. We had six leading models score the same AI system's work. They gave nearly identical grades, but when we examined their reasoning, each one focused on completely different evidence and reached its conclusions through different logic. That finding matters for any company relying on AI to check AI.
The key takeaway: companies can no longer pick one AI model and use it for everything. They need systems that continuously test models against their actual work and assign the right model to the right task. That category of infrastructure is what LayerLens builds, and it is the central argument of this report.
What Happened in Q1 2026
Nine significant model releases shipped in roughly six weeks. That pace is unprecedented.
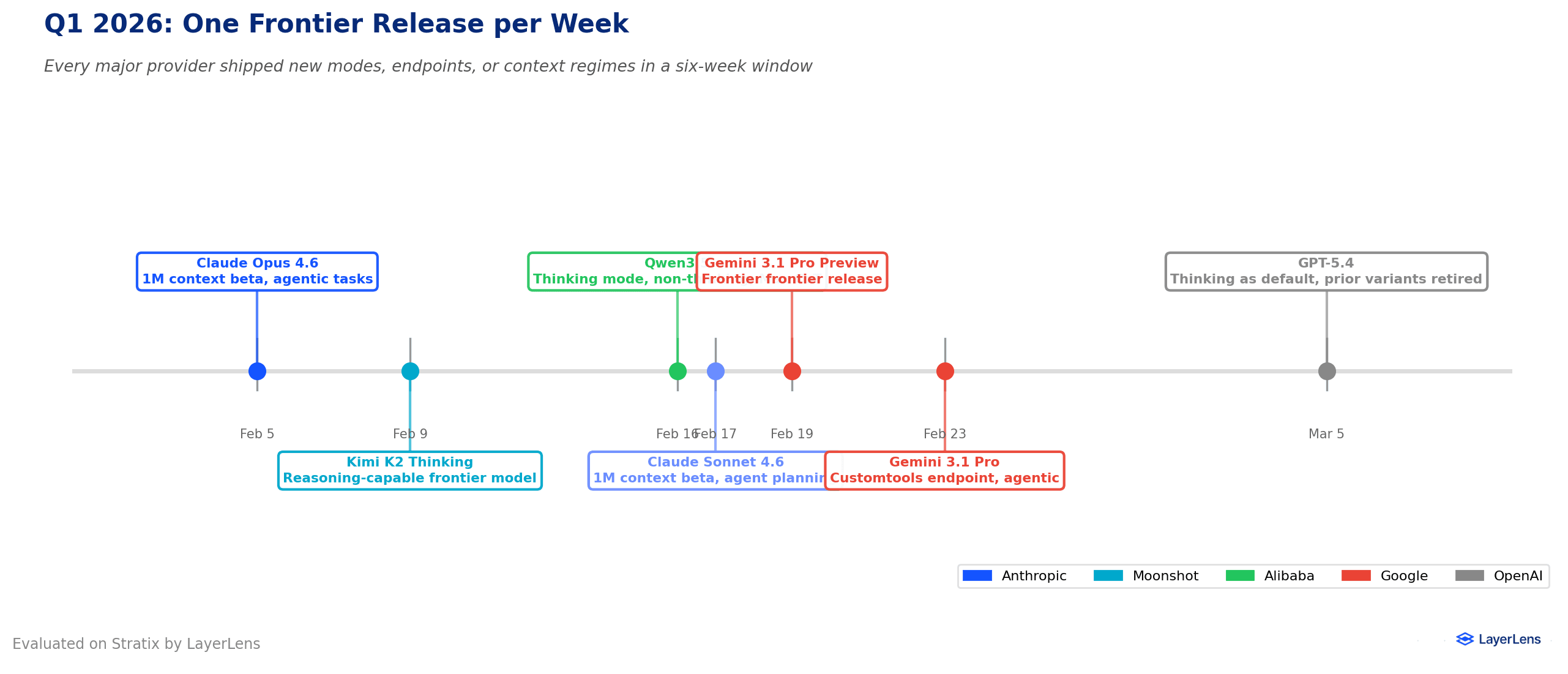
January 27: Moonshot AI released Kimi K2 Thinking, a large open-weight reasoning model.
February 5: Anthropic shipped Claude Opus 4.6 and Sonnet 4.6 with 1M token context.
February 12: MiniMax released M2.5, matching expensive models on SWE-bench.
February 14: ByteDance launched Seed 2.0 in three sizes.
February 16: Alibaba released Qwen 3.5, including phone-sized versions.
February 16: Zhipu AI released GLM-5, topping the open-weight leaderboard.
March 3: Google shipped Gemini 3.1 Flash-Lite and previewed Gemini 3.1 Pro.
March 5: OpenAI launched GPT-5.4 with computer use and mid-stream reasoning.
March 16: Mistral released Mistral Small 4, a compact open-weight model.
Two patterns stand out. First, models now ship as bundles of settings: reasoning mode on or off, different input sizes, different tool access. Second, the affordable model category exploded, making it practical to use different models for different tasks.
The Rise of Affordable AI Models
The biggest story of Q1 2026 may be the affordable models. They score well on tests that only the most expensive models could pass a year ago.
Gemini 3.1 Flash-Lite (Google): About $0.25 per million words. Built for high-volume tasks.
Qwen 3.5 (Alibaba): Phone-sized to frontier-class. LiveCodeBench v6: 83.6%.
Mistral Small 4 (Mistral): Free, handles text and images, 180 pages per request.
Seed 2.0 Mini (ByteDance): Priced for thousands of AI tasks per hour.
MiniMax M2.5: 80.2% on SWE-bench Verified at half the frontier price.
This makes a tiered approach practical. That requires knowing how each model performs on your specific work, which is what Stratix tests.What Five Tests Reveal
What Five Tests Reveal
Stratix sends the same questions to every AI model, scores the answers the same way, and locks down which version is being tested. In Q1 2026, LayerLens tested over 200 models across five exams.
What the five tests measure. Two test knowledge: MATH-500 (math) and MMLU Pro (academic subjects). Three test execution: SWE-bench Lite (fixing real bugs), LiveCodeBench (new programming challenges), and Terminal-Bench (system administration).
On execution tests, models still differ meaningfully. Claude Opus 4.6 leads bug-fixing by 6.3 points. Grok 4 Fast leads programming by 7.3 points. Gemini 3 Pro leads system administration by 2.5 points.On knowledge tests, the top models are essentially tied. On MATH-500, fifteen models score above 96%. The top-five gap is 0.4 points, but run-to-run variation is 1.3 points. The ranking is not statistically meaningful.
No single model wins all five. Claude Opus 4.6 ranks first on bug-fixing but outside the top 25 on math. Grok 4 Fast dominates programming but scores poorly on system administration. Any company choosing based on one leaderboard will be wrong for at least one use case.
When AI Grades AI: A Six-Model Case Study
Many companies use AI models as graders to evaluate other AI systems. LayerLens took one execution trace from an AI agent handling IT access requests in a regulated environment and gave it to six leading models to grade using identical criteria.
The scores looked like agreement. The six grades ranged from 90 to 100 out of 100.
The reasoning told a completely different story.
Claude Opus 4.6 docked points for undocumented verbal manager approval.
Gemini 3.1 Pro flagged gaps in prerequisite verification sequencing.
GPT-5.4 focused on whether every software tool was called correctly.
Grok 4.1 Fast flagged missing metadata in the ticket record.
Each model pulled different evidence, built a different failure theory, and applied a different definition of "good work."
The models that looked harder gave lower scores. Kimi K2 Thinking did the least investigation (8 steps) and scored 100. GPT-5.4 investigated the most and scored 90.
Every grader had blind spots. Kimi K2 spread attention evenly. Claude Opus 4.6 focused on compliance. GPT-5.4 focused on ticket management. No single model covered everything.
The implication: any company using one AI model to grade another's work will permanently inherit that grader's blind spots. Using multiple grading models is not redundancy. It is coverage.What This Means
What This Means
A single grade is not enough. If your evaluation captures only a final score and throws away the reasoning, you are missing the most important information.
One grader is not enough. Every AI model brought its own biases to the grading task, even with identical instructions.
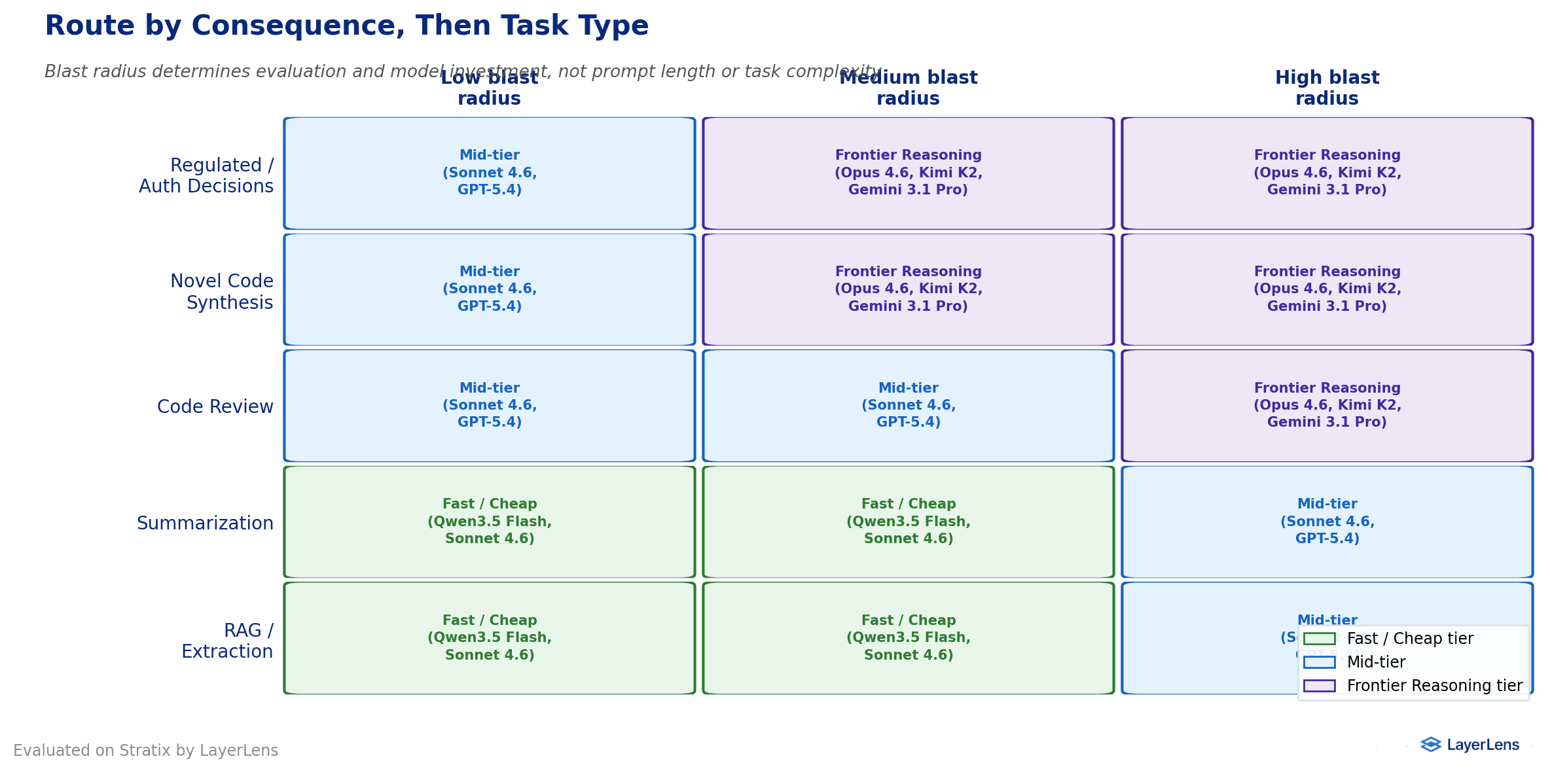
Evaluation effort should match risk. An AI agent handling passwords or regulated data deserves a multi-model grading panel. An agent reformatting a spreadsheet can use a quicker check.
The release pace demands continuous testing. LayerLens tested 25 unique models in Q3 2025, 83 in Q4, and 44 in the first 2.5 months of Q1 2026.
LayerLens calls this approach Judgment Engineering: testing infrastructure that creates its own test cases from real company data, uses AI to grade AI at the level of individual actions, and updates its own standards as models change.
Five Actions for Q2 2026
If you only do one thing this quarter, do the first.
Build a test set from your own data. Collect 300 to 500 real examples of what your AI does in production. Run these against every model update before sending real work to the new version.
Keep the full grading record, not just the score. Store the full record. Surface it when something goes wrong.
Match the model to the risk, then to the task. Use capable models for serious consequences. Use affordable models for routine tasks.
Do not lock yourself into one AI provider. Build your system so you can switch providers without rewriting software.
Plan for AI agent failures. Set time limits. Cap retry logic. Summarize long conversation histories.
These five actions describe Continuous Evaluation Infrastructure. That infrastructure is what Stratix provides.
Key Takeaways
No AI provider leads more than two of five tests on Stratix. Choosing one model for all tasks means underperforming on at least one important job.
Knowledge tests have reached a ceiling. "Doing real work" tests still show clear differences of 2.5 to 7.3 points.
Six AI models graded an agent's work within 10 points of each other, but their reasoning was completely different.
Affordable AI models matured rapidly. This makes using different models for different tasks practical for the first time.
Nine releases in six weeks makes continuous testing the baseline, not the goal.
Frequently Asked Questions
Which AI model performed best overall in Q1 2026?
None of them. No single model won across all five tests on Stratix. The best model depends entirely on the task.
What tests did LayerLens use?
Five: MATH-500, MMLU Pro, LiveCodeBench, SWE-bench Lite, and Terminal-Bench. All ran on Stratix with identical conditions.
How does AI grade AI?
AI models read the complete record of what another AI did and score it against a checklist. Six models graded the same record with similar scores but completely different reasoning.
What is Judgment Engineering?
Testing infrastructure that creates its own test cases from real company data, uses AI to grade results, and updates its grading standards as models change.
Why do test scores not tell the full story?
On knowledge tests, the top models are within 0.4 points while run-to-run variation is 1.3 points. The grading case study showed identical scores can hide completely different reasoning.
How should companies choose AI models?
Collect 300 to 500 real examples of your AI's production work. Run those against every model update. Use capable models for high-stakes decisions and cheaper models for routine tasks.
What is the difference between one-time and continuous testing?
One-time testing runs evaluations once. Continuous testing re-runs on every model update and updates grading standards over time. At this release pace, one-time results expire in weeks.
How many models does Stratix test?
Over 200, spanning every major AI provider. Explore the full results at app.layerlens.ai.
Methodology
All tests were run on Stratix across 200+ models with identical conditions and version-locked endpoints. The five tests: MATH-500, MMLU Pro, LiveCodeBench (Q1 2026 contamination-aware variant), SWE-bench Lite, and Terminal-Bench. Run-to-run variation on MATH-500 across 49 models was 1.3 percentage points.
For the grading experiment, six AI models independently graded one IT service desk agent's work against identical criteria. All reasoning is preserved and viewable on Stratix. This is a single-case study and should be validated across additional cases.
Full results are available on Stratix. Try it free with 200+ models at Stratix Public. For custom grading criteria, AI-powered judges, and team workspaces, Stratix Premium runs everything described in this report end to end.