
AI Quality Assurance for LLM Systems: Why Traditional QA Breaks
Author:
Jake Meany (Dir. of Marketing, LayerLens)
Last updated:
Published:
LLM testing requires statistical evaluation rather than deterministic pass/fail assertions.
AI quality assurance for LLM systems must account for distribution shift, prompt drift, routing logic, and retry behavior.
Regression testing decays unless datasets are refreshed against live traffic.
Release management for LLMs depends on threshold gating, not binary validation.
Observability, benchmarking, and governance together form the backbone of production AI QA.
Traditional QA assumes that the same input produces the same output.
LLM systems violate that assumption.
The same prompt can generate multiple valid responses. Minor wording changes alter structure, tone, or length. Temperature settings introduce variability. Routing logic may swap models midstream. Retry rules compound differences.
LLM testing is not broken. The assumptions underneath traditional QA are.
Why Deterministic QA Fails for LLM Testing
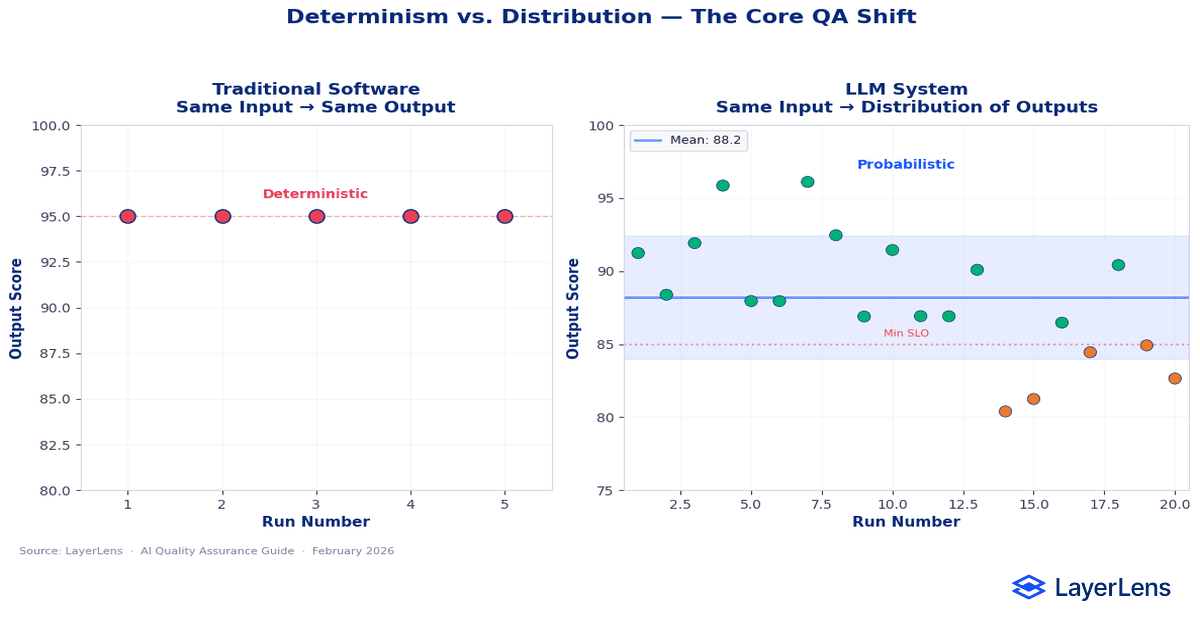
In traditional software QA, a function receives input and returns a predictable value. Unit tests assert equality. If the output changes unexpectedly, something is wrong.
LLM outputs are distributions, not fixed return values.
Two responses can differ syntactically while remaining semantically equivalent. A rigid equality assertion will misclassify correct outputs as failures. Conversely, a shallow validation may pass outputs that are semantically wrong but structurally acceptable.
This is why modern LLM testing depends on statistical metrics rather than strict equality. Accuracy, semantic similarity, entailment scoring, and rubric-based evaluation replace deterministic assertions. See LLM evaluation metrics for production systems for metric design considerations.
LLM test strategy must therefore define tolerance bands instead of fixed expected strings.
Why LLM Regression Testing Decays Over Time
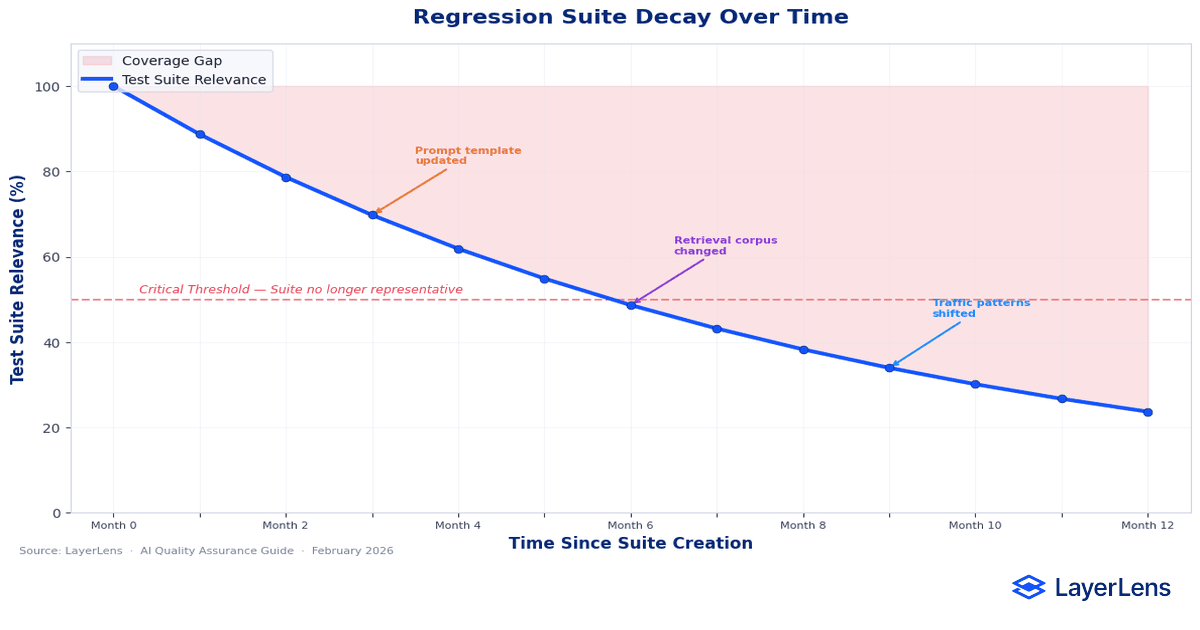
Regression testing for traditional software grows stronger as test cases accumulate.
Regression testing for LLM systems decays.
Prompt templates evolve. Compliance instructions expand. Retrieval corpora update. Product features introduce new query shapes. Real-world traffic shifts in tone and complexity. Research on distribution shift shows that input distributions evolve independently from training data (see distribution shift research).
A regression suite built three months ago may still pass while production performance degrades.
Effective LLM regression testing requires:
Periodic sampling of live traffic
Weighting recent traffic more heavily
Retiring stale or low-signal test cases
Adding newly observed edge-case clusters
For retrieval-specific regression risks, see RAG evaluation in production.
Version-aware benchmarking helps track drift across releases (see LayerLens benchmark tracking).
Regression datasets are not static assets. They must evolve with the system.
Why Passing a Test Suite Does Not Guarantee Stability
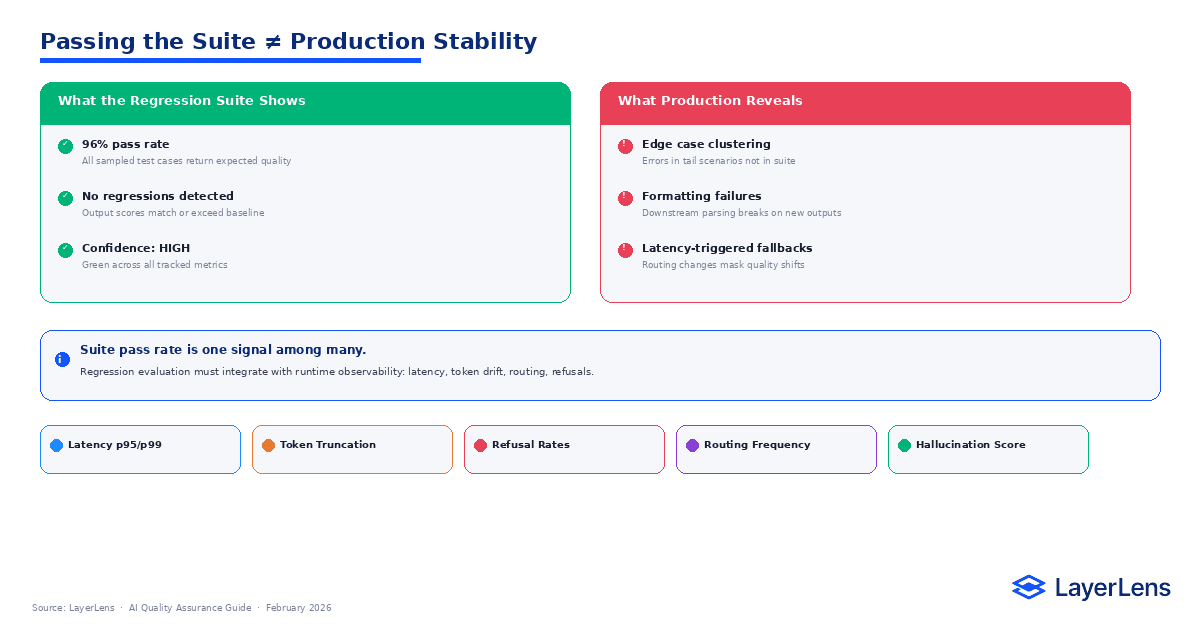
A model passes 95% of regression tests. Deployment proceeds.
In production, error reports cluster around scenarios underrepresented in the suite. Latency tails increase under concurrency. Token usage drifts upward after a prompt revision. Routing fallback frequency rises.
Regression suites sample. Production exposes distribution tails.
Runtime observability surfaces signals that static regression cannot detect. Latency percentiles, routing changes, token drift, and refusal rate shifts reveal systemic changes early (see LLM observability and runtime monitoring).
Deployment gating should integrate evaluation metrics and runtime signals (see LLM evaluation framework).
Passing tests indicates bounded correctness under sampled conditions. Stability requires monitoring distributional behavior.
Human Review in AI Quality Assurance
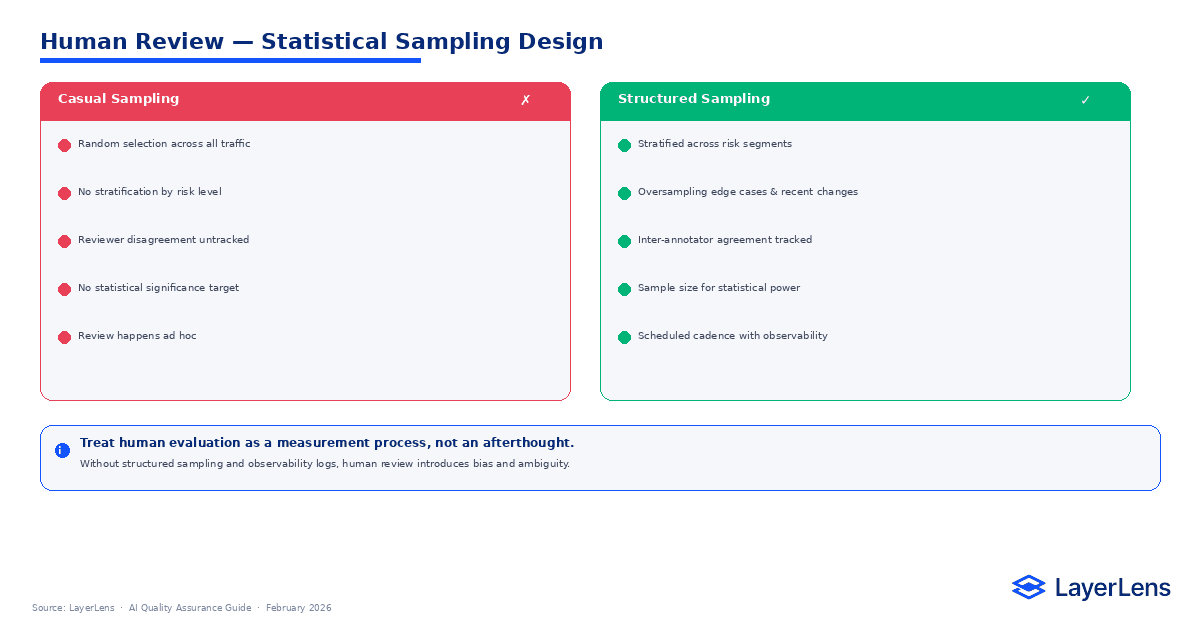
Human review is not optional in LLM QA. It must be structured.
Random sampling across all traffic dilutes signal. Stratified sampling produces higher diagnostic value.
Sampling should focus on:
High-risk domains (legal, medical, financial)
Newly updated prompt templates
Recent model version changes
High-confidence outputs for calibration analysis
Inter-annotator agreement should be measured to detect reviewer drift. Without calibration, human feedback becomes inconsistent.
For adversarial sampling strategies, see AI red teaming for LLMs.
Human QA in LLM systems is a measurement process, not an anecdotal review layer.
LLM Release Management and Threshold Gating
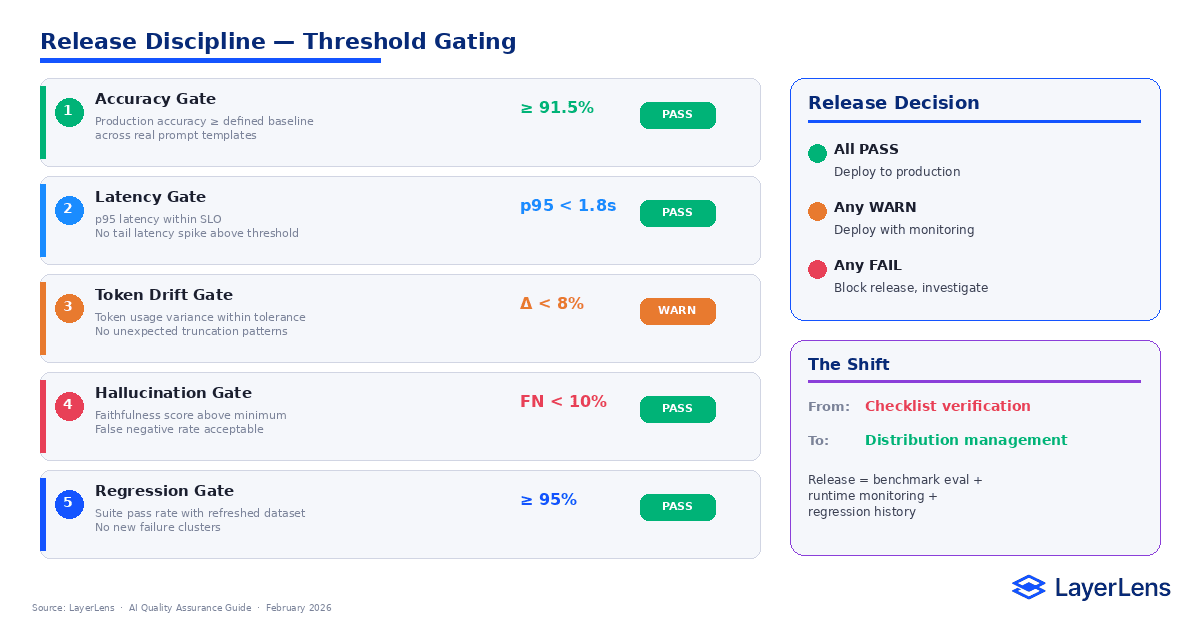
Traditional release cycles ship once tests pass.
LLM release management relies on threshold gating.
Before deploying a new model version, teams should evaluate:
Accuracy under real prompt templates
p95 and p99 latency stability
Token usage drift
Hallucination risk metrics (see LLM hallucination detection)
Routing fallback frequency
Model switching decisions should also incorporate structured comparative analysis, as outlined in AI model comparison in production, to avoid regression introduced by surface-level benchmark deltas.
Release criteria should define acceptable tolerance bands rather than strict pass/fail rules.
Continuous Monitoring as QA Discipline
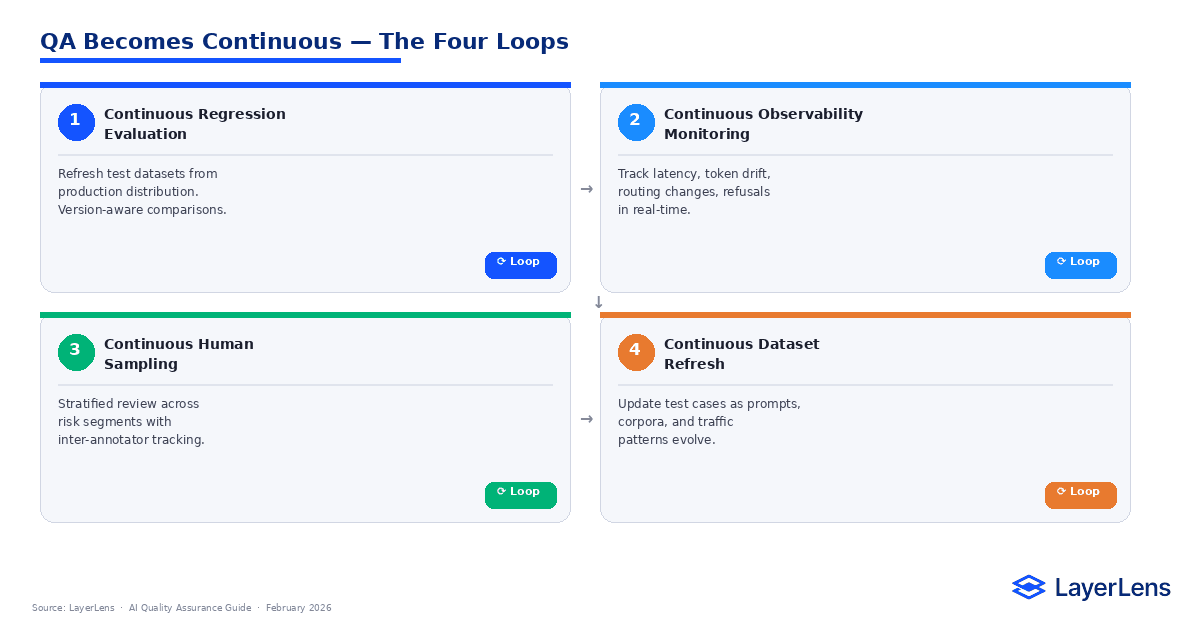
AI quality assurance is not a phase. It is a loop.
Regression evaluation, runtime observability, and deployment gating must operate continuously.
Prompt changes alter token distribution. New features shift latency behavior. Vendor updates modify internal model weights.
Continuous monitoring combines:
Refreshed regression datasets
Latency and routing alerts
Token usage monitoring
Regression history tracking
LayerLens evaluation dashboards integrate these signals across releases (see LayerLens evaluation dashboards).
QA for LLM systems becomes distribution management over time.
Tools Supporting LLM Testing in Production
LLM testing requires tooling that integrates benchmarking, observability, and governance.
A complete system should provide:
Benchmark evaluation across tasks
Latency percentile visibility
Token cost and cost-per-request analysis
Version-aware regression tracking
Deployment gating dashboards
LayerLens Stratix Premium integrates private benchmarks, regression history, and governance thresholds for enterprise environments (see Stratix Premium monitoring suite).
LLM testing is operational only when supported by instrumentation.
Conclusion
Traditional QA assumes repeatability. LLM systems introduce variability.
Deterministic assertions do not capture distributional behavior. Regression suites decay as traffic evolves. Passing tests does not guarantee stability.
AI quality assurance for LLM systems requires statistical evaluation, runtime observability, structured human sampling, and threshold-based release management.
LLM testing is not about eliminating variance. It is about bounding variance within acceptable operational limits.
That shift defines modern QA for probabilistic systems.
Key Takeaways
LLM testing requires tolerance-based evaluation rather than deterministic equality checks.
Regression suites must refresh against live production distributions.
Observability complements regression evaluation.
Human review must be stratified and calibrated.
Release management depends on threshold gating rather than binary validation.
Frequently Asked Questions
What is LLM testing?
LLM testing evaluates probabilistic model outputs under real prompt templates using statistical metrics rather than deterministic equality checks.
Why does traditional QA break for LLM systems?
Traditional QA assumes identical input produces identical output. LLM systems generate distributions of outputs that require tolerance-based evaluation and continuous monitoring.
How should LLM regression testing work?
LLM regression testing should refresh datasets from live traffic, measure distributional metrics, and integrate runtime observability signals.
What is the difference between LLM testing and traditional software testing?
Traditional software testing relies on deterministic assertions. LLM testing requires statistical evaluation, calibration analysis, and continuous regression monitoring.
How does release management change for LLM systems?
Release management uses threshold-based gating across accuracy, latency, token drift, hallucination risk, and routing stability rather than binary pass/fail validation.