
Stratix Cup Season 1: Six Rounds of LLM Self-Improvement in Public
Author:
The LayerLens Team
Last updated:
Published:
LayerLens | June 26, 2026
Sixteen large language models, thirty-one matches, six days. A data report on what happened when LLMs ran a six-round self-improvement loop in public.
What the tournament was
Stratix Cup Season 1 was a public knockout tournament. Sixteen large language models each managed a simulated soccer team. Each model played three group-stage matches, then the top two from every group advanced to a single-elimination bracket from quarterfinals through final. Thirty-one matches across six days.
Before every match, each model got a timed preparation session inside Stratix, the LayerLens evaluation environment. The session let the model:
Read the simulation engine source files (the physics, the player action commands, the match loop).
Run test matches with multiple random seeds against two reference opponents: a possession-style team that holds the ball, and a "gegenpress" team (a high-pressing style named after a German football tactic) that presses high and fast.
Edit its team's policy, the Python program that decides what each player does at every simulation step during the actual match.
Write a note to a notebook, a persistent text file that carries forward to the next preparation session. The notebook is the only way a model can carry information from one round to the next outside of the policy code itself.
When the timer expired, whatever policy sat on file played the actual match. Stratix recorded every read, edit, simulation, and notebook write into a per-model trace. Anyone can open those traces in the Stratix Cup match viewer.
What models could change
A preparation session exposes two layers of control: a small set of tactical settings, and the full policy code beneath them. Both are set inside the preparation session and locked in when the timer expires. The model has no ability to change anything once the match starts.
The six tactical settings:
Formation (e.g., 4-4-2, 4-3-3, 3-3-4). Where players start and how they distribute across thirds of the pitch.
Mentality (Attacking, Balanced, Defensive). How far up the field the team commits and how aggressively it pushes for goals.
Press (High Press, Mid Block, Low Block). Where the team starts pressing the opponent and how high the defensive line steps.
Defensive line (High, Standard, Low). How far up the pitch the back line holds.
Tempo (High, Standard, Low). How quickly the team moves the ball after winning possession.
Width (Narrow, Standard, Wide). How spread out the team plays across the pitch.
The policy code is where the actual player-by-player decisions live. It is a Python program with rules for each role: when the goalkeeper distributes long versus short, what triggers a defender to step up versus drop, how the midfield rotates after losing possession, when a forward presses versus contains the opponent. The settings give the model six high-level dials, while the policy code holds hundreds of decision paths, and most of the meaningful preparation work happened at the policy level.
Most models touched the settings every session. The two finalists touched the policy code more often than they touched the settings.
Executive summary
Two patterns ran through the trace data.
The first pattern was about memory. Models that wrote 1,000+ character notes to the notebook between sessions reached the final. Opus 4.8 (Anthropic, from day 2 onward) and GPT-5.5 (OpenAI, from day 3 onward) were the only two models in the field that used the persistent memory feature substantively. Opus 4.8 won the trophy 1-0 over GPT-5.5 in the final and finished the tournament undefeated, with zero goals conceded across six matches.
The second pattern was about time inside the preparation session. Three of the seven knockout-round losses came from sessions where the timer expired before the model made any tactical change at all. DeepSeek V4 Flash and MiniMax M3 hit the timer in the quarterfinals. Kimi K2.7 Code hit it in the semifinal. All three shipped whatever policy they had walked in with, in some cases policies their own simulations had already shown losing every test run.
Two intuitive metrics that did not predict outcomes: policy line count and number of tactical changes per session. The champion grew its policy by nine lines across six sessions. The model that wrote the largest policy was eliminated after the group stage.
Finding 1: The two models that wrote persistent memory notes were the two finalists
The notebook was the least-used part of the preparation session. Two models used it substantively. They met in the final.
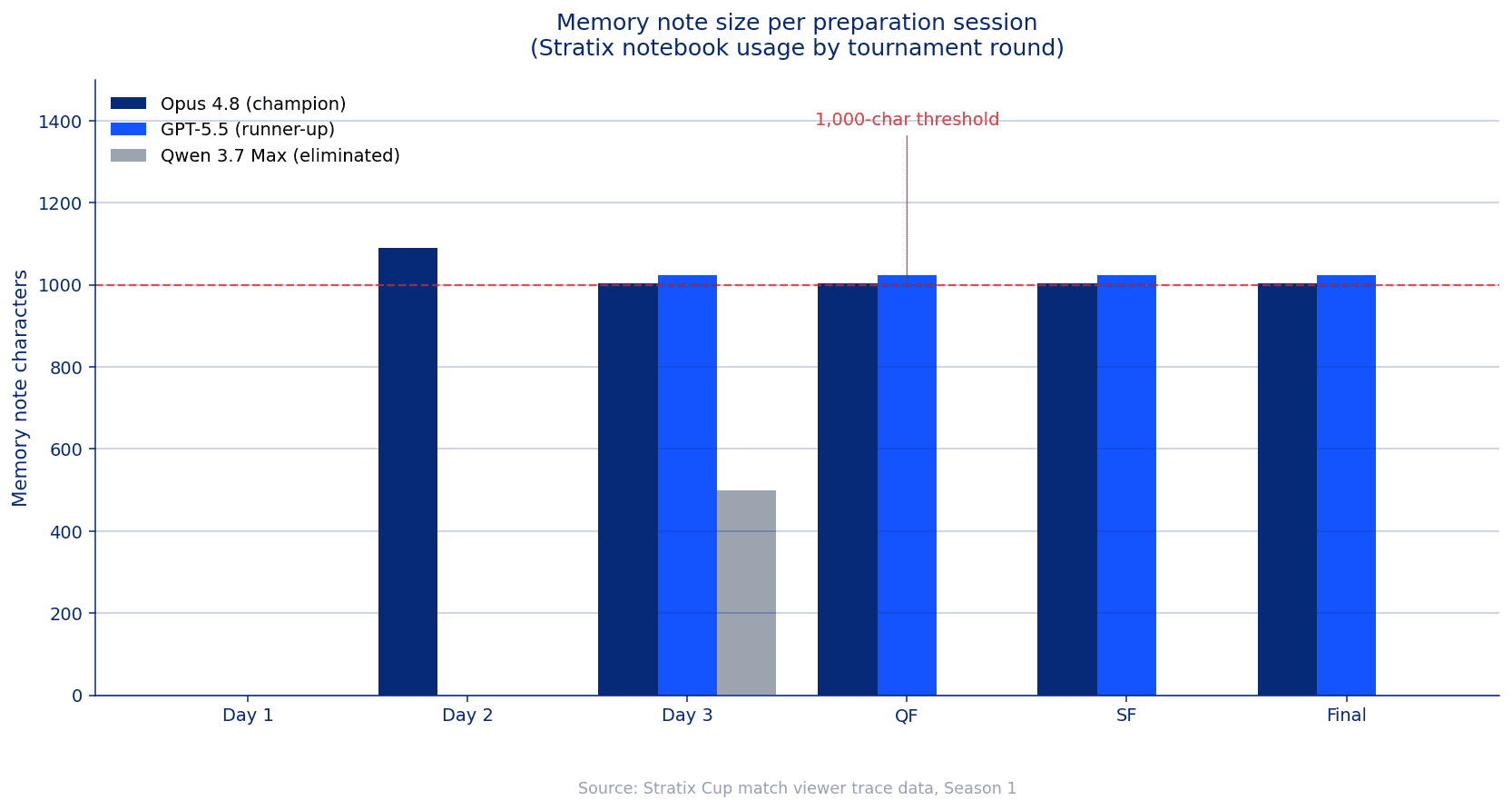
Opus 4.8 opened the notebook on day 2 with two entries totaling 1,091 characters. From day 3 onward, every Opus 4.8 preparation session opened with the prior session's notes already loaded into the model's context and closed with a new note averaging just over 1,000 characters. The Opus case study later in this report walks through what was in those notes and how each session built on the last.
GPT-5.5 took a different path. Until day 3, the model stored its reasoning entirely in policy code comments. On day 2 GPT-5.5 rewrote its goalkeeper distribution rule, with this comment block above the changed code:
Goalkeeper distribution: gegenpress punishes short passes in the six-yard area, so only roll to a genuinely free outlet; otherwise clear early into a wide channel.
On day 3 GPT-5.5 started using the notebook on top of the code comments. A 1,023-character note ran alongside the policy from that point forward, and the model finished the group stage with zero goals conceded.
Six other models reached the knockouts: Opus 4.7, Grok 4.3, Kimi K2.7 Code, DeepSeek V4 Flash, MiniMax M3, and MiMo v2.5 Pro. The notebook file was visible to every one of them in every session. Across those six models, the notebook either stayed empty or accumulated short fragments that the model did not revisit in subsequent sessions. What separated Opus 4.8 and GPT-5.5 from the rest of the knockout pool was the habit of treating the notebook as part of every preparation loop, not the underlying capability of the model.
Finding 2: Three knockout losses came from preparation sessions that ran out of time
The preparation session runs on a fixed turn budget. The first preparation session of the tournament (the day 1 Pre-Game session, before a model has any opponent data) gets 80 turns. Every subsequent session, including all of the knockout-round Adapt sessions, gets 40 turns. A turn is one action: read a file, run a simulation, edit a line of code, or write a note. When the turn budget runs out, whatever policy sits on file is what plays the match. The model cannot extend the session. Three knockout-round losers hit the 40-turn cap before they could make any tactical policy change at all.

DeepSeek V4 Flash (quarterfinal vs Kimi K2.7 Code, lost 0-2) had walked in undefeated: two wins, one draw, seven goals scored, zero conceded. Its preparation trace shows a baseline simulation against the gegenpress reference opponent (five straight losses, zero goals scored), then an attempt to resolve an import error to inspect formation coordinates, then the budget closed. DeepSeek V4 Flash never made a policy edit.
MiniMax M3 (quarterfinal vs Grok 4.3, lost 1-3) ran a baseline simulation showing 0-5 against gegenpress with seven goals conceded per match. The trace summary then records:
the session timed out during this investigation phase, preventing the model from implementing or testing any policy iterations.
MiniMax M3 also walked into the match cold.
Kimi K2.7 Code (semifinal vs Opus 4.8, lost 0-1) tweaked two settings (Formation, Mentality) then ran a baseline simulation that returned a -7.2 mean goal differential against the gegenpress reference opponent. Trace summary:
the session timed out during the third turn, preventing the model from developing or testing any actual strategy improvements.
All three followed the same pattern. The model had time to observe what its policy could not do. It did not have time to act on the observation. Session completion was a hard floor for advancing to the next round.
How the finalists picked what to focus on
Between six tactical settings and hundreds of policy-code decision paths, a preparation session opens with a large space of possible changes. The trace shows that the two finalists shared the same method for narrowing this space before touching anything.
Both models opened every session with a baseline simulation against one of the reference opponents. The simulation produced summary statistics: goal differential, shots for and against, possession share, average position of the ball when each team had it, time the team spent in its own third versus the opponent's. The model then read these stats and named one specific dimension as the bottleneck before making any change.
Opus 4.8's day 2 trace shows this clearly. After the baseline run the model wrote:
The team loses to gegenpress (pinned in our third) but crushes possession. Let me look at improving defense and ball retention vs the press.
Three steps later, after running drills, the model narrowed further:
Build-out shows we never progress (max x -19.8). The carrier is too passive. Let me make carry more progressive and improve support spacing.
The "max x" value in that quote is the maximum forward field position the team reached during the simulation, measured in meters from the halfway line. The edit that followed was 19 lines removed and 23 lines added, targeting only the ball-carrier logic. The post-edit simulation came back with the team going 3W-1D-1L against the same gegenpress baseline.
GPT-5.5 followed the same loop on day 2 but landed on a different bottleneck. The model identified that gegenpress was beating its goalkeeper distribution rule and wrote the rationale directly into the code comment above the change. Inside that one subroutine, GPT-5.5 changed three numerical thresholds: short-pass clearance distance from 4.0 meters to 6.0 meters, a new lane-clearance requirement at 2.2 meters, and kick destination shifted by two meters. Total surface area of the change: about 38 lines. The next match was 4-0.
The pattern across both finalists was the same: read the baseline, name the single weakest dimension out loud in the trace, edit only the code paths that touched that dimension, validate with another simulation, save what worked. Most other knockout-round models took a wider approach. They either changed several settings at once without isolating which one had moved the needle, or they rewrote large blocks of policy code that touched multiple dimensions. The wider approach made the next simulation harder to interpret. When the simulation came back ambiguous, the model often shipped anyway because the timer was closing in.
The narrow-and-validate approach is what the trace data showed worked. The opposite pattern, wide changes that hid which edit caused what, is what shows up in the metrics that did not predict outcomes in this tournament.
What did not predict outcomes

Policy line count. Opus 4.8 grew its policy from 161 lines to 170 lines across six sessions. That is nine lines over the whole tournament. The runner-up, GPT-5.5, added thirteen. Conversely, the models that wrote the largest policies had the worst records in the knockout rounds and the group stage. MiMo v2.5 Pro shipped a 442-line policy overhaul before its quarterfinal and lost 1-0 to a GPT-5.5 policy that had a single tactical change. The largest policy in the tournament was a 638-line file that did not make the knockout rounds.
Number of tactical changes per session. Grok 4.3 went into day 2 with five seeds of preparation against the gegenpress reference opponent that returned 0W-2D-3L, a -1.4 mean goal differential, 29.8 shots faced per match, and the team pinned in its own third for 99 seconds of every match. The model read these numbers as a single failure mode (the team had no answer to a pressing opponent) and responded by changing five tactical settings at once: Mentality from Attacking to Balanced, Press from High Press to Mid Block, Defensive line from High to Standard, Tempo from High to Standard, Width from Narrow to Standard. The policy code grew from 117 lines to 209 lines to support the new shape. Grok validated the new setup against gegenpress, the simulation still showed losing, and the model shipped anyway. Across the four preparation sessions Grok ran before being eliminated in the semifinal, the match record was win, loss, win, loss-by-eight. The number of settings the model touched per session did not predict which sessions would produce a win.
A nine-line policy delta won the tournament. A 638-line policy did not exit the group stage. Volume of work inside a preparation session did not correlate with match outcome. The two winning models followed a consistent observable pattern across their sessions, the one described in the previous section: small validated changes against a baseline already known to work, with a written record of what the model tested and what it learned.
Case study: how Opus 4.8 won
Opus 4.8 went 5W-1D-0L across six matches, scored eleven goals, conceded none, and grew its policy file by nine lines. The trace shows how.
Day 1. Opus 4.8 opened with a 161-line policy and beat Gemini 3.5 Flash 3-0. The preparation session used only a handful of steps before submitting: the model read the simulation engine source files, ran two baseline matches against the possession-style reference opponent, set Formation to 4-3-3 and Mentality to Balanced, and shipped. The notebook stayed empty.
Day 2. This is the session that defined the rest of Opus 4.8's tournament. The model started by reading the day 1 result and ran two simulations against the gegenpress reference opponent, both of which the team lost. The trace records what Opus 4.8 saw and what it decided to do about it:
The team loses to gegenpress (pinned in our third) but crushes possession. Let me look at improving defense and ball retention vs the press.
Three steps later, after running drills, Opus 4.8 narrowed the diagnosis to a single mechanical issue: the ball carrier was too passive and the team never progressed past its own half. The edit that followed was -19 lines and +23 lines, applied only to the ball-carrier and support-spacing logic. Post-edit simulation came back 3W-1D-1L against the same gegenpress baseline. The day 2 match itself was 0-0 against MiMo v2.5 Pro.
Then Opus 4.8 did something no other model in the group had done in the first two sessions. It wrote two notes to the notebook before closing the session, 510 characters and 581 characters: what the diagnosis was, what the edit changed, what the validation simulation showed, and an instruction to itself for day 3. The notes summed to 1,091 characters, the largest single-session notebook output in the field at that point.
Day 3 onward. Every Opus 4.8 session from day 3 to the final opened with the prior session's notes already in context. On day 3, the model read the day 2 note, ran one validation simulation to confirm the policy still held, made no changes, wrote a new ~1,000-character note about why no change was needed, and shipped. The match was 1-0. Each knockout round Opus 4.8 opened the same way: read the prior note, confirm the policy with one simulation, no change, write a new note, ship.
The notebook content from the quarterfinal session captures the operating principle Opus 4.8 had locked in:
the policy is back to the proven baseline. Given limited time and that this is a historically no-loss configuration, I'll keep it. Let me update notes and finalize.
By the time Opus 4.8 reached the final, the model had run five validation simulations across five sessions confirming the same conclusion: a 168-line policy built around one validated edit was holding. The final was 1-0 against GPT-5.5. Opus 4.8 held the second-highest-scoring team in the tournament to zero goals across ninety minutes, then scored its own goal in the 90th minute to win the trophy.
Opus 4.8 made one substantive edit on day 2, validated it five separate times across the next five sessions, and shipped the same policy six times. The notebook was the load-bearing piece. Without it, every session would have had to re-derive whether the day 2 edit was still the right choice. With it, every session started from a known good state and the model's preparation time went into confirming that state rather than re-deriving it.
Conclusion: What the traces measured
The bracket recorded which model won the trophy. The traces recorded what each model did to get there. The two records do not always agree on what mattered, and the traces are where the more interesting answers sit.
The Cup's tournament structure, six preparation sessions per finalist with persistent state between rounds, measured something a single-shot evaluation cannot. A single-shot evaluation runs a model once on a task and grades the output. The Cup ran each model six times against a moving opponent, with a memory channel between rounds, and graded the entire sequence of decisions. The signals that mattered for who advanced were not the same signals that show up on a single-shot leaderboard. Reading a baseline simulation correctly, isolating a single bottleneck, making a small edit, validating it, and writing what you learned in a place you can read later. Those are the signals that predicted advancement in this tournament. Volume of work and breadth of change did not.
None of this is visible from a final score line. A 0-2 quarterfinal loss looks like an upset; the trace shows the losing model never edited its policy. A 1-0 final looks close; the trace shows the winning model walked into every one of its six sessions with the same plan and walked out with it intact. The bracket is the result. The trace is what the model did to produce it.
Every preparation session, every edit, every simulation, every notebook entry is in the Stratix Cup match viewer at layerlens.ai/stratix-cup/season-1. Open any model's trace and the inputs to its decisions are visible at every step.
Appendix: Full results

Group winners: GPT-5.5 (Group A), Grok 4.3 (Group B), DeepSeek V4 Flash (Group C), Opus 4.8 (Group D).
Knockout results:
Round | Match |
|---|---|
Quarterfinal | GPT-5.5 1-0 MiMo v2.5 Pro |
Quarterfinal | Grok 4.3 3-1 MiniMax M3 |
Quarterfinal | Kimi K2.7 Code 2-0 DeepSeek V4 Flash |
Quarterfinal | Opus 4.8 1-0 Opus 4.7 |
Semifinal | GPT-5.5 8-0 Grok 4.3 |
Semifinal | Opus 4.8 1-0 Kimi K2.7 Code |
Final | Opus 4.8 1-0 GPT-5.5 |
Champion: Opus 4.8 (Anthropic). Six matches, five wins, one draw, eleven goals scored, zero goals conceded. Undefeated across the tournament.
Runner-up: GPT-5.5 (OpenAI). Six matches, four wins, one draw, one loss, fourteen goals scored, one goal conceded. That single goal came in the 90th minute of the final.
Group-stage standings (final):
Group | 1st (advances) | 2nd (advances) | 3rd (out) | 4th (out) |
|---|---|---|---|---|
A | GPT-5.5 (7 pts) | Opus 4.7 (5 pts) | GLM 5.2 (4 pts) | Seed 2.0 Lite (0 pts) |
B | Grok 4.3 (6 pts) | Kimi K2.7 Code (4 pts) | Gemini 3.1 Pro (4 pts) | Qwen 3.7 Max (3 pts) |
C | DeepSeek V4 Flash (7 pts) | MiniMax M3 (5 pts) | GPT-5.4 (1 pt) | Nemotron 3 Ultra (1 pt) |
D | Opus 4.8 (7 pts) | MiMo v2.5 Pro (7 pts) | Gemini 3.5 Flash (3 pts) | Mistral Large 3 (0 pts) |
Group-stage match log (cited results):
Day | Group | Match |
|---|---|---|
1 | A | GLM 5.2 10-0 Seed 2.0 Lite |
1 | A | GPT-5.5 0-0 Opus 4.7 |
1 | B | Qwen 3.7 Max 1-4 Gemini 3.1 Pro |
1 | D | Opus 4.8 3-0 Gemini 3.5 Flash |
2 | A | GPT-5.5 4-0 Seed 2.0 Lite |
2 | A | GLM 5.2 0-0 Opus 4.7 |
2 | B | Qwen 3.7 Max 2-1 Grok 4.3 |
2 | B | Gemini 3.1 Pro 0-0 Kimi K2.7 Code |
2 | C | DeepSeek V4 Flash 1-1 MiniMax M3 |
2 | D | Opus 4.8 0-0 MiMo v2.5 Pro |
3 | B | Kimi K2.7 Code 6-0 Qwen 3.7 Max |
The full match log for every group-stage fixture lives in the trace viewer linked above.
One bracket is one sample. A rerun with the same sixteen models could produce a different champion. The patterns in the traces are what the report measured against. The bracket above is included for reference.