Explore the latest in AI
Benchmarking & Evaluation
Welcome to the LayerLens Blog, where we dive into the latest advancements in AI model evaluation, industry benchmarks, and the ever-evolving landscape of generative AI. Our mission is to provide transparent, data-driven insights that empower enterprises, researchers, and developers to make informed decisions about AI model performance, safety, and real-world applicability.

Why AI Benchmarks Are Misleading (And What to Use Instead)
Published:

Partner Evaluation Spaces: Benchmark Models on Fireworks AI and Nebius Infrastructure
Published:

Introducing Judge Optimization on Stratix Enterprise: Close the Gap Between Automated Scores and Human Judgment
Published:
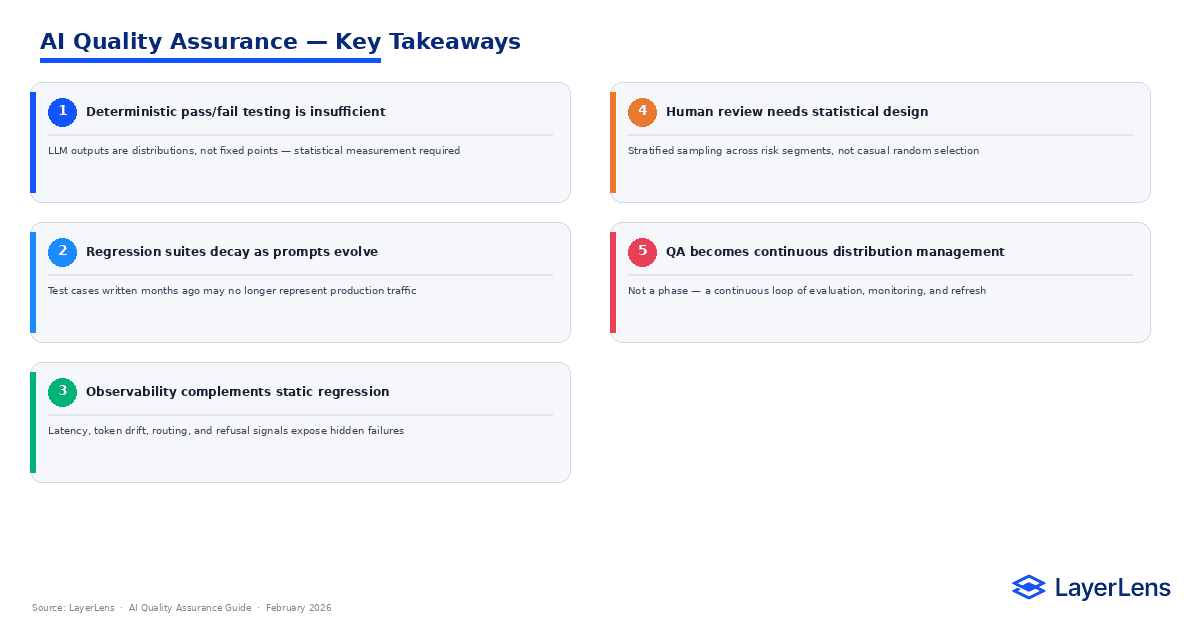
AI Quality Assurance for LLM Systems: Why Traditional QA Breaks
Published:

AI Model Comparison in Production
Published:

RAG Evaluation Framework for Production AI Systems
Published:
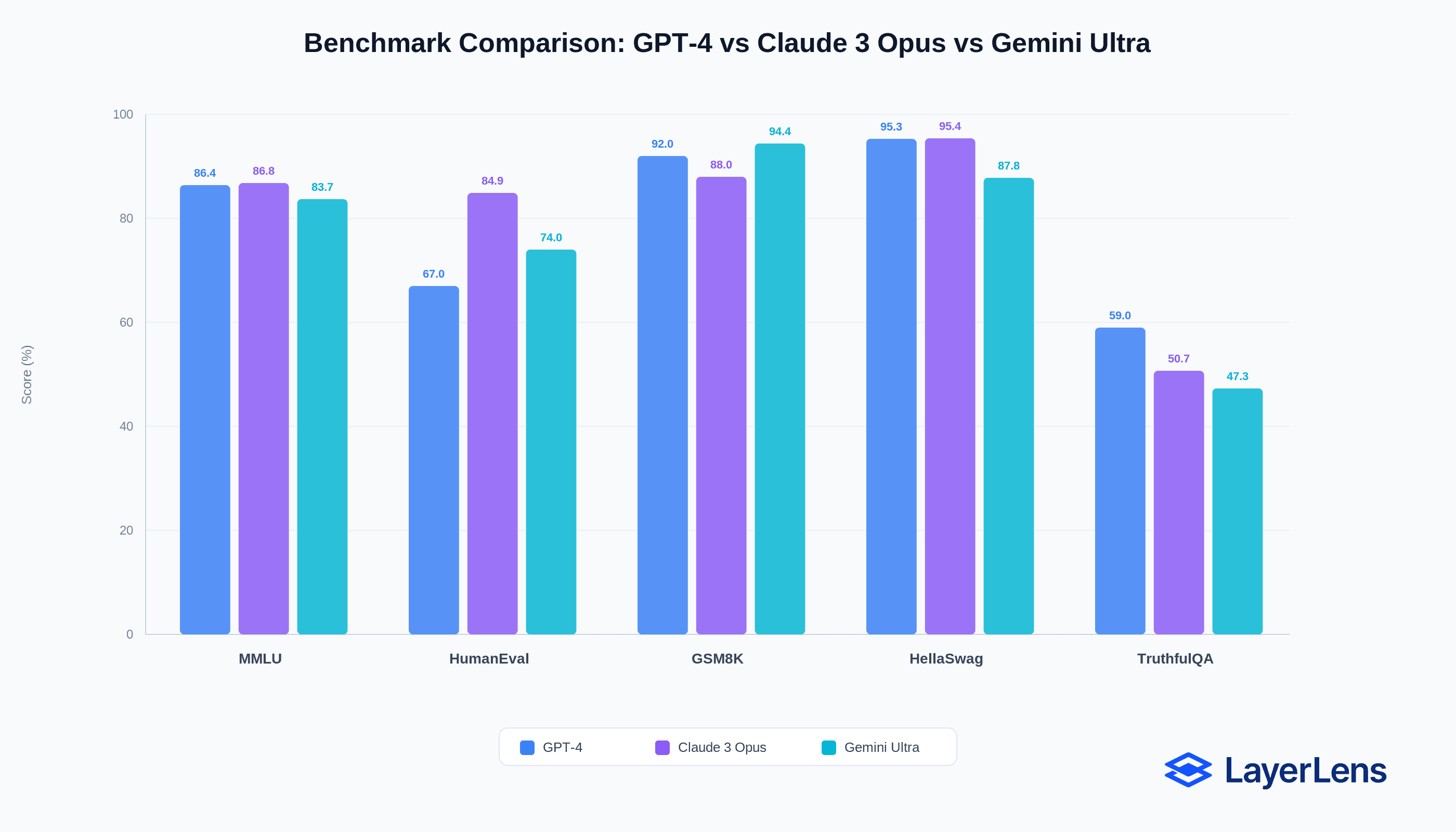
LLM Evaluation Framework for Production
Published:

GPT-5.4 Benchmark Review: What Stratix Data Shows Across the Full Model Family
Published:

GLM-5 Benchmark Review: 20 Eval Runs, 13 Benchmarks, and the Data That Changed Between February and March
Published:

Moltbook Proved That the AI Agent Revolution Has a Governance Problem, Not a Readiness Problem
Published:

Gemini 3.1 Pro Benchmark Review: What 14,549 Tests Actually Reveal
Published:

LLM Observability for Production AI Systems
Published:

LLM Evaluation Framework for Enterprise AI
Published:

How to Evaluate AI Agents: Methods, Metrics, and Real-World Pitfalls
Published:

Gemini 3.1 Flash Lite Benchmark Results vs. GPT-5 Nano, Qwen3.5: Efficiency Model Comparison
Published:

LLM Cost Optimization: What Actually Drives Production Spend
Published:

LLM Hallucination Detection in Production
Published:
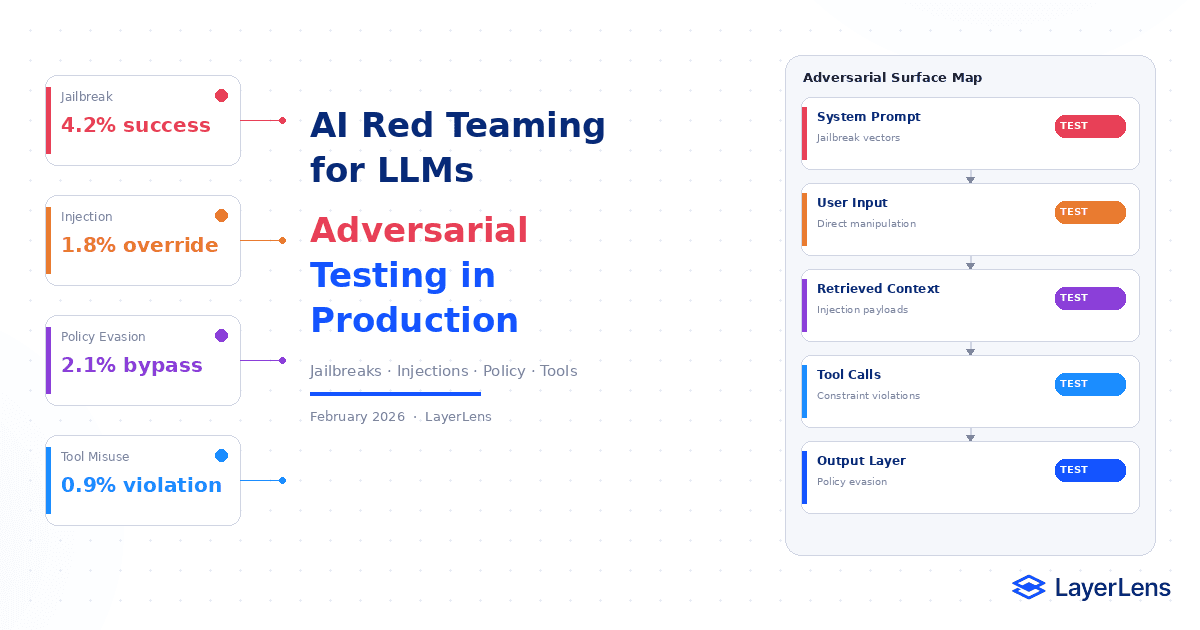
AI Red Teaming for LLMs in Production
Published:
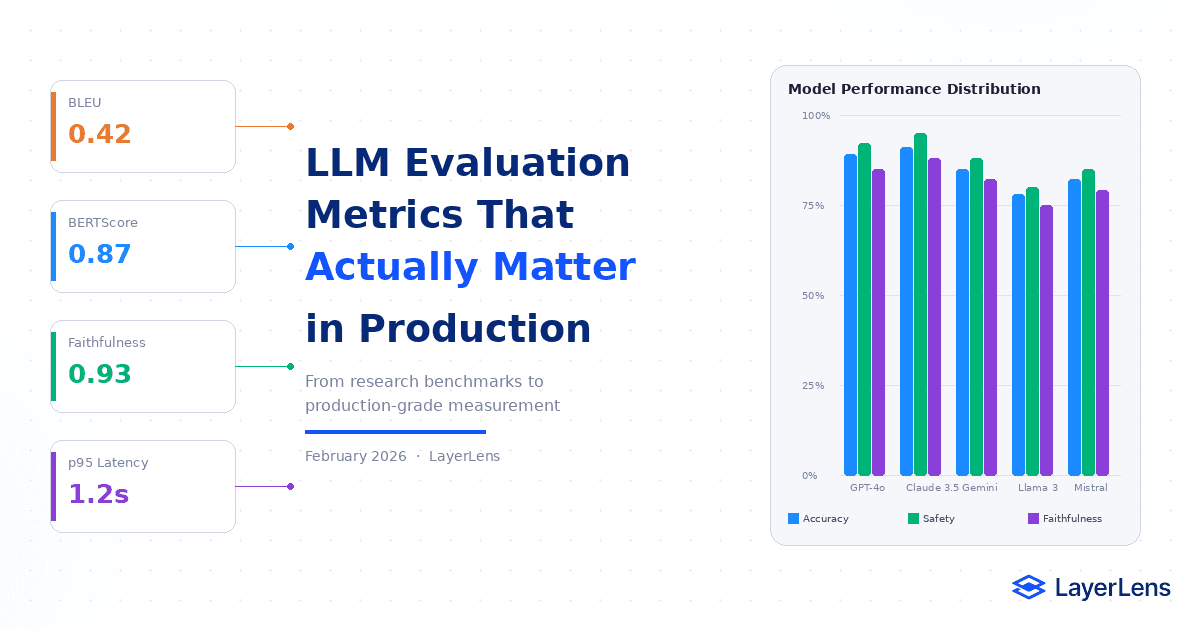
LLM Evaluation Metrics for Production Systems
Published:
Why AI Benchmarks Are Misleading (And What to Use Instead)
Published:
Partner Evaluation Spaces: Benchmark Models on Fireworks AI and Nebius Infrastructure
Published:
Introducing Judge Optimization on Stratix Enterprise: Close the Gap Between Automated Scores and Human Judgment
Published:
AI Quality Assurance for LLM Systems: Why Traditional QA Breaks
Published:
AI Model Comparison in Production
Published:
RAG Evaluation Framework for Production AI Systems
Published:
LLM Evaluation Framework for Production
Published:
GPT-5.4 Benchmark Review: What Stratix Data Shows Across the Full Model Family
Published:
GLM-5 Benchmark Review: 20 Eval Runs, 13 Benchmarks, and the Data That Changed Between February and March
Published:
Moltbook Proved That the AI Agent Revolution Has a Governance Problem, Not a Readiness Problem
Published:
Gemini 3.1 Pro Benchmark Review: What 14,549 Tests Actually Reveal
Published:
LLM Observability for Production AI Systems
Published:
LLM Evaluation Framework for Enterprise AI
Published:
How to Evaluate AI Agents: Methods, Metrics, and Real-World Pitfalls
Published:
Gemini 3.1 Flash Lite Benchmark Results vs. GPT-5 Nano, Qwen3.5: Efficiency Model Comparison
Published:
LLM Cost Optimization: What Actually Drives Production Spend
Published:
LLM Hallucination Detection in Production
Published:
AI Red Teaming for LLMs in Production
Published:
LLM Evaluation Metrics for Production Systems
Published:
Why AI Benchmarks Are Misleading (And What to Use Instead)
Published:
GPT-5.4 Benchmark Review: What Stratix Data Shows Across the Full Model Family
Published:
How to Evaluate AI Agents: Methods, Metrics, and Real-World Pitfalls
Published:
Partner Evaluation Spaces: Benchmark Models on Fireworks AI and Nebius Infrastructure
Published:
GLM-5 Benchmark Review: 20 Eval Runs, 13 Benchmarks, and the Data That Changed Between February and March
Published:
Gemini 3.1 Flash Lite Benchmark Results vs. GPT-5 Nano, Qwen3.5: Efficiency Model Comparison
Published:
Introducing Judge Optimization on Stratix Enterprise: Close the Gap Between Automated Scores and Human Judgment
Published:
Moltbook Proved That the AI Agent Revolution Has a Governance Problem, Not a Readiness Problem
Published:
LLM Cost Optimization: What Actually Drives Production Spend
Published:
AI Quality Assurance for LLM Systems: Why Traditional QA Breaks
Published:
Gemini 3.1 Pro Benchmark Review: What 14,549 Tests Actually Reveal
Published:
LLM Hallucination Detection in Production
Published:
AI Model Comparison in Production
Published:
LLM Observability for Production AI Systems
Published:
AI Red Teaming for LLMs in Production
Published:
RAG Evaluation Framework for Production AI Systems
Published:
LLM Evaluation Framework for Enterprise AI
Published:
LLM Evaluation Metrics for Production Systems
Published:
LLM Evaluation Framework for Production
Published: