Feb 25, 2025

Artificial intelligence is evolving at an unprecedented pace, with tech giants racing to develop models that promise greater speed, accuracy, and reasoning. Yet, behind the flashy announcements and impressive leaderboard scores lies a critical issue: many of the benchmarks used to evaluate AI performance are fundamentally flawed.
The Benchmark Illusion
AI companies frequently promote their models by showcasing high scores on popular benchmarks like MMLU, HellaSwag, and GSM8K. These benchmarks have become industry standards, shaping public perception and investment decisions. But what do these scores actually measure? And are they truly reliable indicators of real-world performance?
The answer is more complex than it appears. Many benchmarks were designed years ago for simpler systems, making them less effective at evaluating today’s advanced models. Worse, some models may have inadvertently been trained on benchmark datasets, skewing results and inflating performance metrics.
Hidden Bias and Data Leakage
One of the most concerning issues with current benchmarks is data leakage. Since AI models are often trained on vast amounts of publicly available data, they may encounter benchmark content during training—giving them an unfair advantage. This contamination undermines the benchmark's reliability, turning what should be a fair test into a flawed measure of true capability.
Additionally, many benchmarks rely on datasets sourced from platforms like Reddit, WikiHow, and Mechanical Turk. While easily accessible, this data often lacks the rigor and nuance required for evaluating AI in high-stakes domains like healthcare, finance, and law. As a result, models that excel on these benchmarks may still struggle with the complexities of real-world tasks.
Benchmark Gaming: When Numbers Don’t Tell the Whole Story
Another issue is the phenomenon of "benchmark gaming," where companies optimize their models specifically to score well on popular tests rather than focusing on broader, real-world performance. This practice creates a misleading impression of a model’s capabilities, as success on a narrow set of benchmarks does not necessarily translate to practical effectiveness.
For example, a model might ace a multiple-choice reasoning test but still fail to provide accurate, nuanced responses in real-world scenarios. This discrepancy highlights the need for benchmarks that better reflect the complexity and unpredictability of real-world environments.
Why Independent Benchmarking Is the Future
To address these challenges, the AI industry must move toward independent, transparent benchmarking conducted by third-party organizations. Independent benchmarks ensure a level playing field, free from the influence of any single company’s training data or optimization strategies.
At LayerLens, we are pioneering a new standard for AI benchmarking. Our platform provides objective, multi-dimensional evaluations that assess models not only for their accuracy and speed but also for their reliability, ethical performance, and real-world applicability. By leveraging proprietary datasets and rigorous testing methodologies, we deliver insights that go beyond traditional benchmarks, helping enterprises choose models that genuinely meet their needs.
Case Study: Humanity’s Last Exam
Earlier this month, the Center for AI Safety, in collaboration with Scale AI, released Humanity’s Last Exam (HLE), a set of hard reasoning questions meant to challenge the premier frontier models. HLE is meant to be a high end reasoning challenge: premier models such as O3 mini, even when equipped with search, score less than 15% on average, with most models scoring less than 10%. HLE has redefined model benchmarking by introducing a new caliber of challenge that tests the limits of even the most advanced AI systems. Unlike traditional benchmarks that focus on narrow capabilities, HLE represents a comprehensive assessment of reasoning across multiple domains including logic, mathematics, and counterfactual thinking.
What makes HLE particularly noteworthy is how it exposes fundamental limitations in current AI architectures. When the highest-performing models struggle to reach even 15% accuracy, it signals that we're far from achieving the robust reasoning capabilities needed for truly reliable AI systems. This gap between current performance and ideal capabilities underscores the need for rigorous, independent evaluation frameworks.
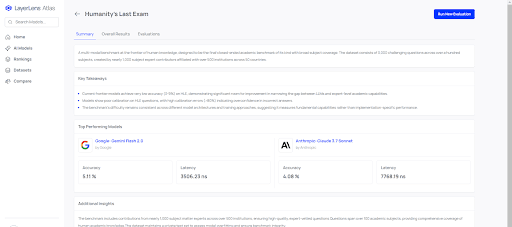
Early results from the Atlas Platform for Claude 3.7, a new reasoning model released by Anthropic
The Road Ahead: Redefining AI Excellence
As AI continues to reshape industries and society, the need for reliable, unbiased performance assessments has never been greater. The current benchmark system, with its outdated datasets and susceptibility to gaming, is no longer sufficient. It’s time for a paradigm shift—one that prioritizes real-world performance, transparency, and accountability.
At LayerLens, we’re leading this shift. By developing innovative benchmarking solutions that provide a more accurate, holistic picture of AI capabilities, we’re empowering businesses to make smarter decisions and drive meaningful progress. Because when it comes to AI, true excellence isn’t about scoring high on a test—it’s about delivering real-world results that matter.
Stay ahead of the curve—explore how LayerLens is redefining AI benchmarking.
EXPLORE MORE ARTICLES
PREVIOUS

NEXT

