Feb 27, 2025

The past month has revealed a defining trend in generative AI: reasoning-driven models are shaping the next phase of AI interaction. The movement began with OpenAI’s O1-Preview, signaling a shift toward models that prioritize extended reasoning over sheer scale. More recently, DeepSeek R1 accelerated this trend, and now Anthropic’s Claude 3.7 Sonnet has entered the race with an updated model that further strengthens agentic AI capabilities.
Claude 3.7 Sonnet introduces significant improvements in reasoning, decision-making, and task execution, making it one of the most advanced models released to date. The model demonstrates sharper analytical skills, better real-world application performance, and the ability to engage in interactive environments.
Sharper Performance on Practical Tasks
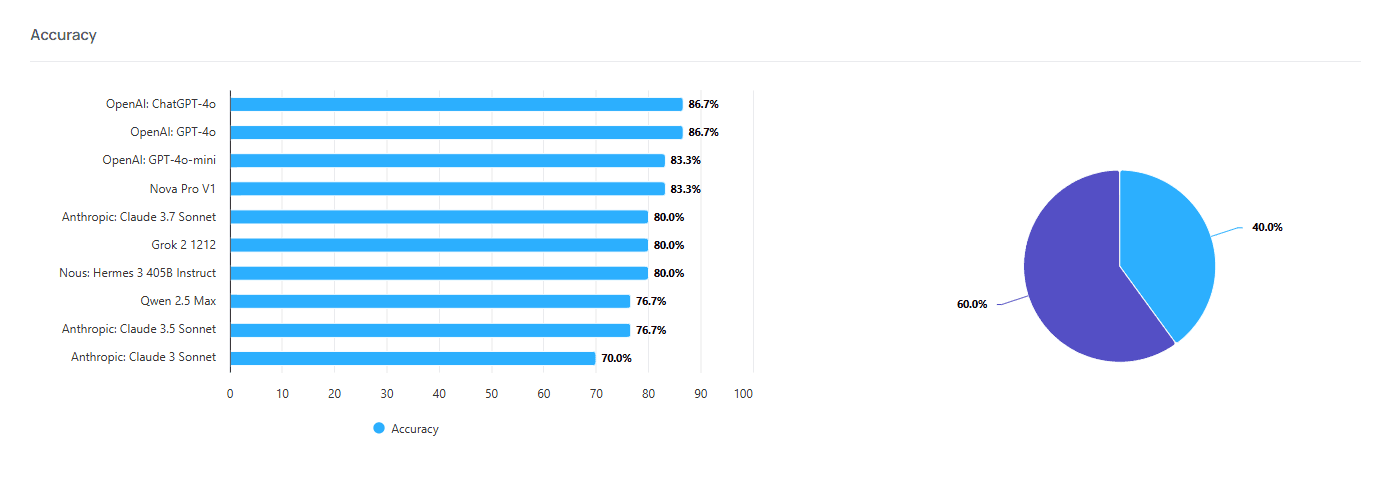
Claude 3.7 Sonnet refines its ability to tackle real-world, analytical challenges. In the Accounting Audit benchmark, which tests a model’s ability to answer financial and accounting-related queries, Claude 3.7 Sonnet not only outperformed its predecessor but also matched the performance of top-tier AI models in the field.
This improvement signals more than just theoretical gains—it highlights the model's growing ability to handle complex, structured tasks with real-world implications. As generative AI extends into enterprise workflows, models that excel in structured reasoning will become increasingly critical for industries requiring precision, such as finance, legal analysis, and scientific research.
AI as a Decision-Maker: Playing Pokémon in Real Time
Beyond traditional benchmarks, Claude 3.7 Sonnet is demonstrating its ability to engage with dynamic, real-time decision-making environments. Anthropic’s latest model is now being tested in a highly interactive setting—as a Pokémon trainer on Twitch.
On the channel Claude Plays Pokémon, the model navigates the classic Pokémon Red game, making strategic decisions, planning moves, and explaining its reasoning in real time. This experiment serves as more than just an entertaining display—it illustrates how AI can translate analytical thinking into agentic decision-making, applying structured reasoning to real-time, dynamic environments.
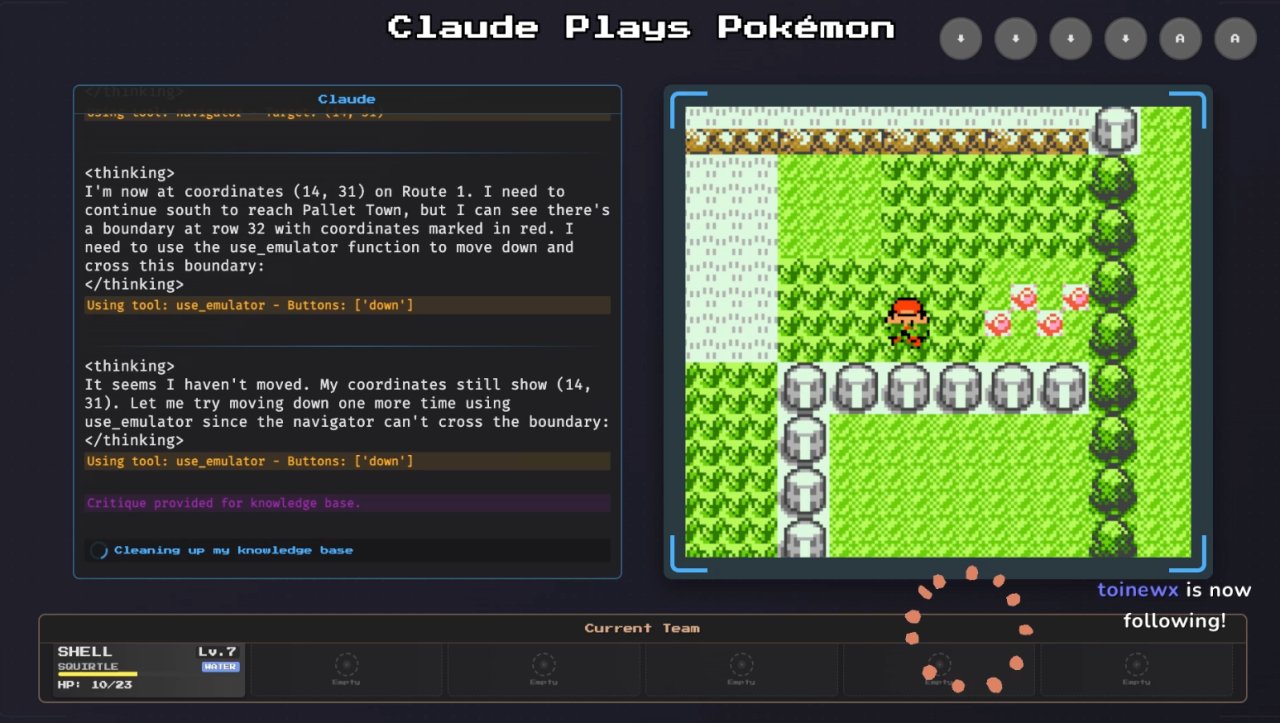
Image from TechCrunch on Claude playing Pokemon
Agentic Goals
AI models are evolving from static tools into reasoning-driven, agentic systems capable of engaging with real-world environments in real time. This shift represents a fundamental transformation in AI research—one that moves beyond passive data processing toward autonomous, adaptive decision-making.
Claude 3.7 Sonnet exemplifies this agentic transition. Its performance in live Twitch gameplay not only highlights its strategic reasoning but also demonstrates how models can translate abstract decision-making into real-time, interactive problem-solving. Meanwhile, its stronger performance on structured, practical tasks such as accounting audits signals progress toward real-world analytical applications.
This agentic shift opens the door to AI models that actively engage with dynamic environments, allowing them to adapt, learn, and make autonomous decisions in high-stakes domains such as autonomous robotics, adaptive logistics, and real-time decision support systems. By incorporating complex environmental feedback, these models move closer to fully autonomous AI systems—ones that not only process information but act on it with precision, insight, and adaptability.
LayerLens Atlas: Bringing Independent AI Validation
At LayerLens, our mission is to validate foundational models independently and transparently—whether through rigorous benchmarking or real-world evaluations. As reasoning models become more agentic, the need for robust, scenario-based evaluations grows stronger.
We are actively working to expand our benchmarking datasets and evaluation frameworks to better reflect how models perform in practical, real-world settings. Expect more updates from us soon as we continue peeling back the layers of generative AI.
Want to see independent benchmarking in action? Learn more here.
EXPLORE MORE ARTICLES
PREVIOUS

NEXT

