Apr 1, 2025

Not all top-performing AI models are built for real-world complexity—here’s how to see past the leaderboard.
When a new LLM breaks a benchmark record, it makes headlines. But for developers and decision-makers building in the real world, one question keeps surfacing: Does this actually mean the model performs well in practice?
The truth is, most benchmarks only scratch the surface. They tell us how well a model remembers facts, not how well it reasons, adapts, or avoids failure in unfamiliar territory. And for enterprises investing in AI systems—where accuracy, latency, safety, and explainability all matter—those shallow wins won’t cut it.
That’s where true benchmarking comes in.
Beyond the Leaderboard: What You’re Not Being Told
Take GPT-4o, Claude 3.7 Sonnet, or Qwen 32B. Each of these models performs brilliantly on paper. But when we push them through reasoning-heavy benchmarks like Big Bench Extra Hard (BBH), a very different story begins to emerge.
Some models fall back on memorization. Others slow to a crawl under cognitive load. A few—very few—prove they can handle logic, pressure, and nuance all at once.
Benchmark Spotlight: BBH Extra Hard – Accuracy vs. Latency
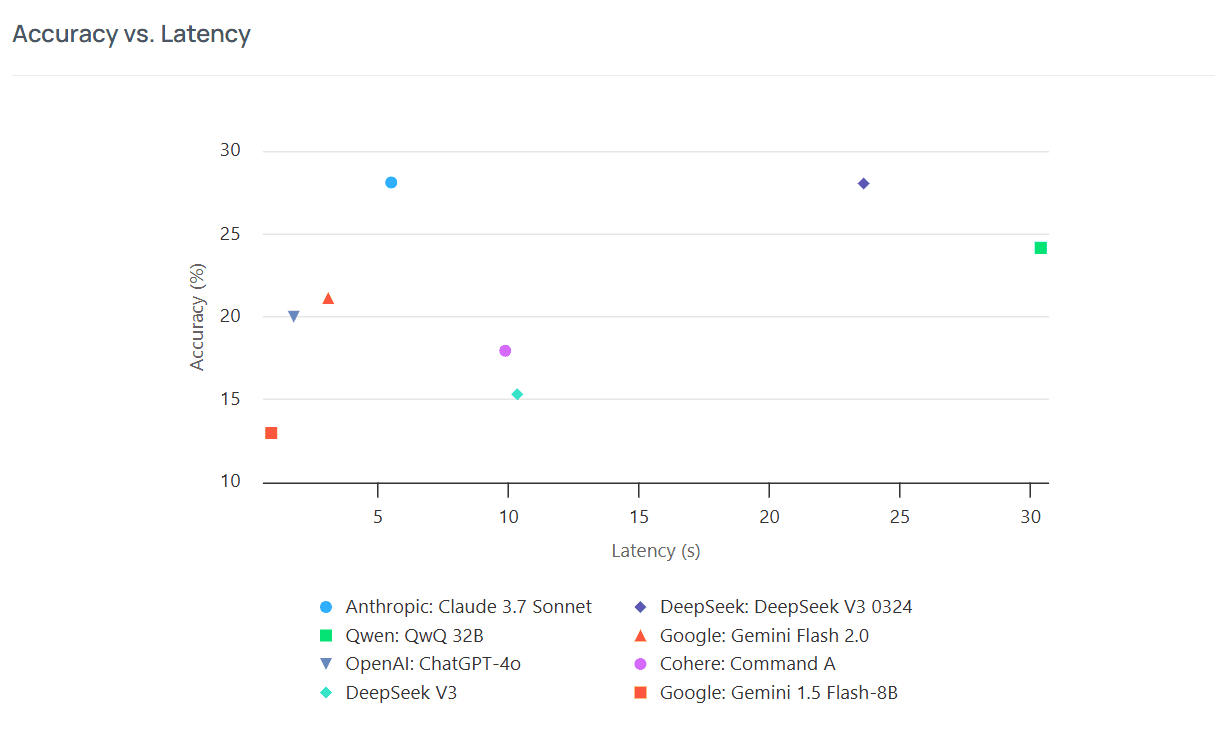
Big Bench Extra Hard: Frontier Model Performance on Accuracy vs. Latency (via LayerLens Atlas)
This chart captures what most benchmarks miss.
Claude 3.7 Sonnet leads with both top-tier accuracy and low latency—rare in high-performing models
Qwen 32B performs well in reasoning but at the cost of speed
Other models, including some household names, reveal limitations that wouldn’t be obvious on basic benchmarks
These aren’t just stats—they’re strategic signals for builders and buyers alike.
Why This Matters for Developers and Enterprises
Whether you're integrating LLMs into customer service flows, automating document processing, or building intelligent agents, you’re not just picking a model—you’re making a call on performance, cost, and risk.
And that means understanding the trade-offs:
Speed vs. reasoning
Cost vs. reliability
Accuracy vs. adaptability
Our platform doesn’t just rank models—it reveals how those trade-offs play out in the real world.
Join Our Early Release Program
We’re opening early access to our benchmarking platform: dashboards, leaderboards, customizable evals—designed to give developers and AI teams total clarity before they build.
Final Thought
We’re not here to crown a winner. We’re here to map the territory—so you can make better choices in the era of generative AI.
Because at LayerLens, we’re not just tracking scores. We’re building trust.
EXPLORE MORE ARTICLES
PREVIOUS

NEXT

