Apr 9, 2025

Meta AI’s latest addition to its foundational model lineup, Llama 4, was announced this past Saturday, continuing the momentum of the Llama 3 series. The release includes two new models—Maverick and Scout—along with a preview of a much larger version reportedly featuring 2 trillion active parameters.
Despite their open-source architecture, Maverick and Scout have quickly emerged as serious contenders among frontier models, demonstrating strong early performance across multiple evaluation benchmarks.
We’ve previously covered a number of frontier releases—DeepSeek R1, Kimi 1.5, Claude 3.7 Sonnet, and DeepSeek V3 among them. As this trend map shows, most open-source breakthroughs in recent months have originated from China. With Llama 4, Meta offers the U.S. answer to open-source dominance from the East—and early results suggest it’s more than holding its own.
Below, we explore initial evaluation results for Maverick and Scout, using data directly from the Atlas platform.
Strengths of Maverick and Scout
Both models appear to excel in computational domains like mathematics and programming, outperforming or matching many of their open-source peers.
In a head-to-head comparison of Maverick, Qwen, and DeepSeek V3, Maverick showed comparable mathematical performance to both Qwen and V3:
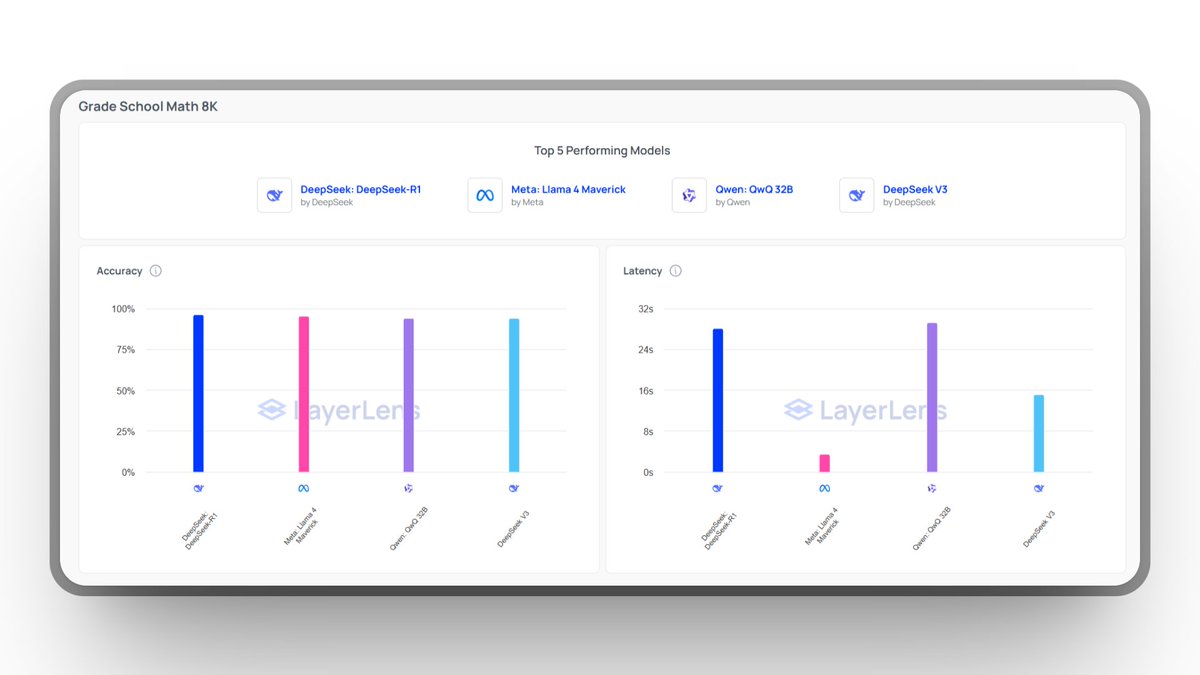
Top open-source models ranked by accuracy and latency on GSM8K.
On reasoning-heavy tasks, Maverick demonstrated even stronger results. In particular, it outperformed DeepSeek V3 on Humanity’s Last Exam, a benchmark designed to test complex academic reasoning across disciplines:
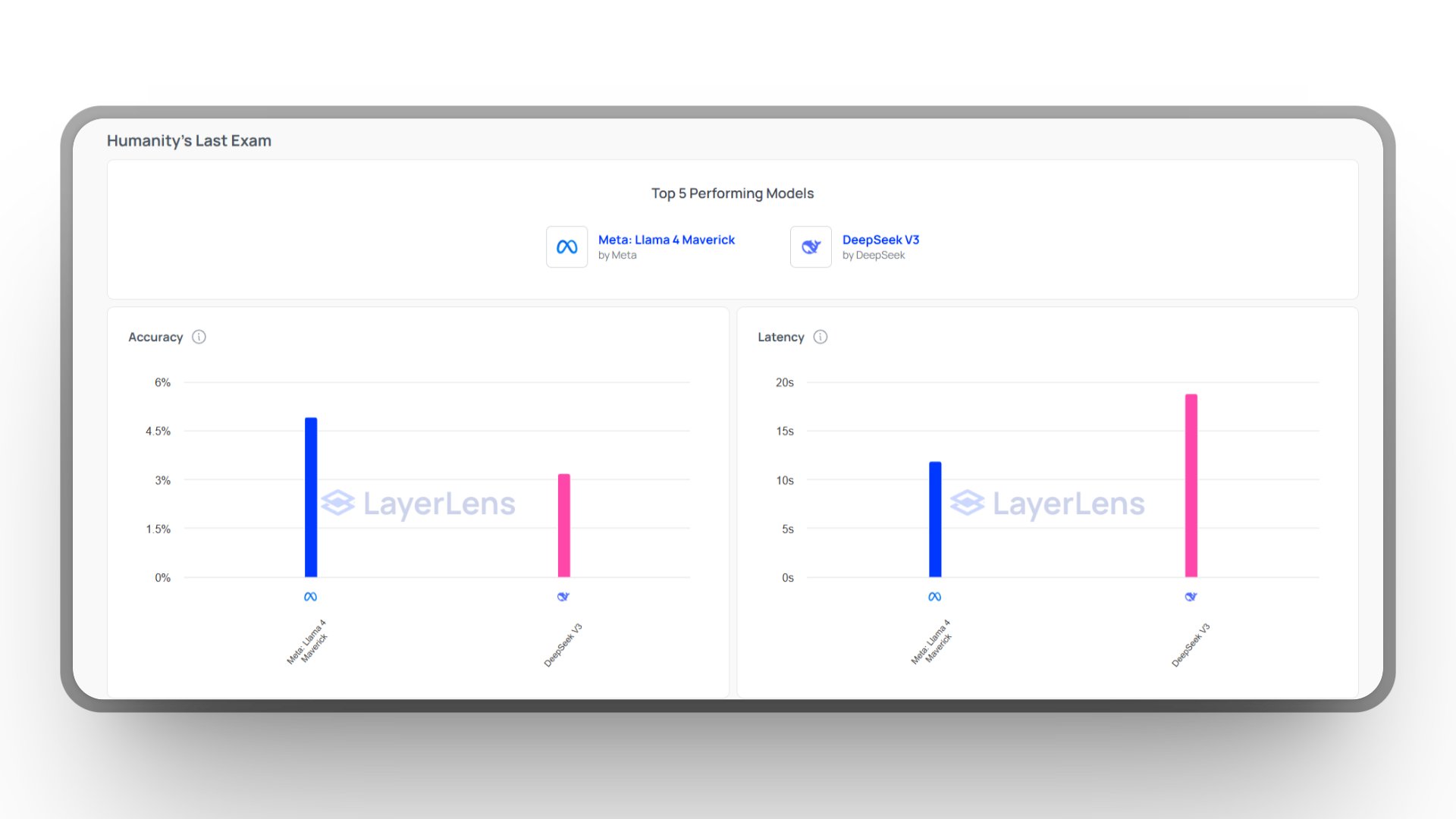
Maverick outperforms V3 on reasoning, with lower latency.
This level of performance highlights two important developments:
U.S.-based open-source development is accelerating, especially from major players like Meta.
There’s a strategic shift underway, with more American tech giants exploring open-source frameworks to stay competitive at the frontier of AI.
What Comes Next?
The current release of Llama 4 includes Maverick and Scout, but a much larger version—rumored to feature 2 trillion parameters—is expected to follow soon.
We’ll continue tracking benchmark performance for the entire Llama 4 lineup, including deeper comparisons with other top-tier U.S. and Chinese models. Follow our coverage on X for real-time updates, leaderboard highlights, and early insights from Atlas.
EXPLORE MORE ARTICLES
PREVIOUS

NEXT

