May 1, 2025

Generative AI is reshaping finance—but can today’s top models actually handle financial reasoning?
In sectors like banking, investment, and accounting, the promise of generative AI is huge. But as adoption accelerates, one core question remains: how do we know these models can reason through financial data in ways that matter to business?
The Gap Between Hype and Application
Most benchmarks we use today—like MMLU or GPQA—measure general knowledge. Others like MedQA or Mathematics test domain-specific skills. But in finance, where models are increasingly expected to analyze statements, assess risk, or interpret real-time economic events, these academic benchmarks fall short.
What’s needed is a way to evaluate models on practical, high-stakes, finance-specific tasks—not trivia.
Charting Financial Reasoning Performance
We ran a head-to-head benchmark of leading LLMs on Stock BCS, a dataset that tests understanding of the stock market, basic economics, and financial patterns.
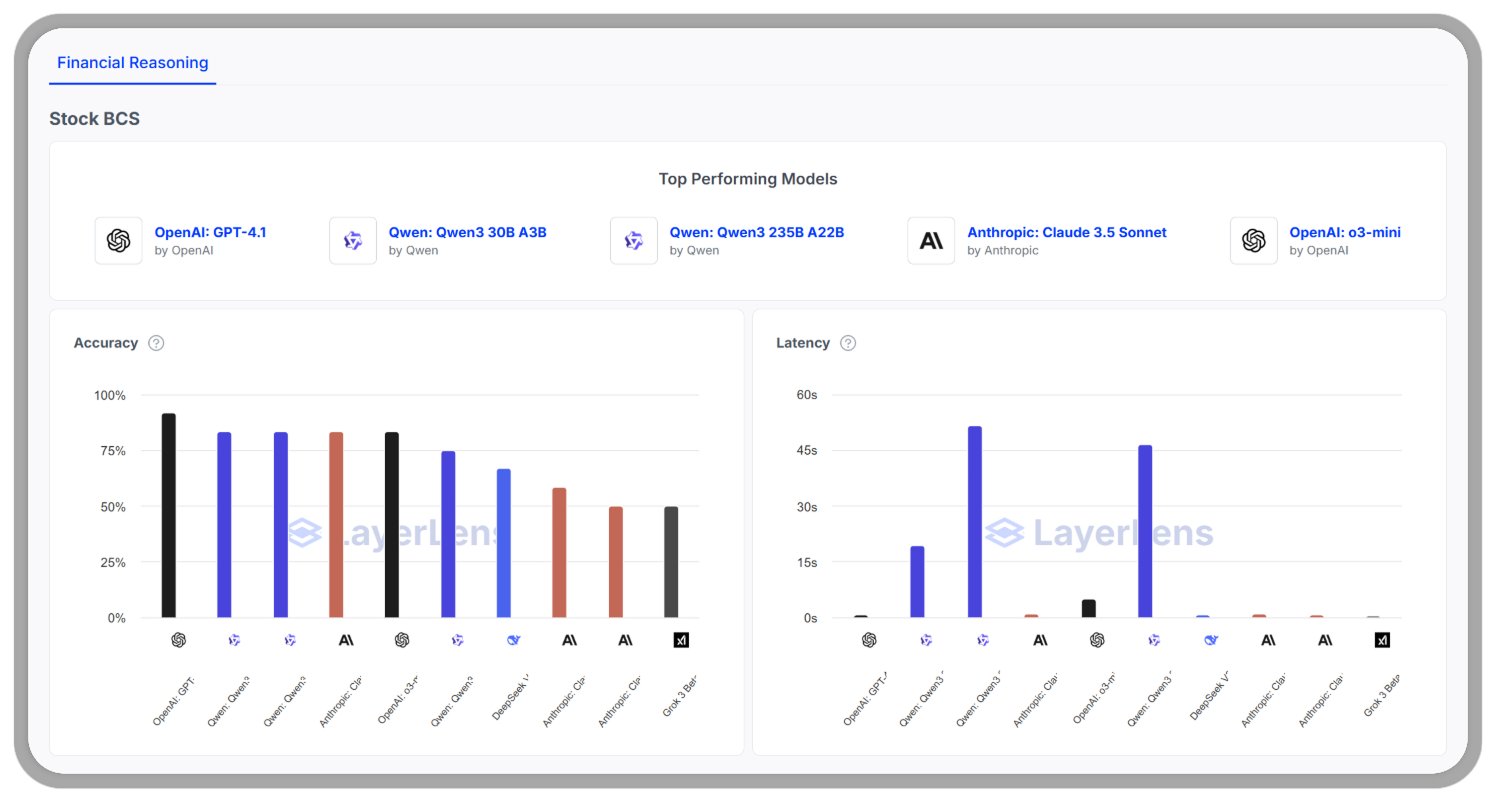
Stock BCS chart
OpenAI GPT-4.1 continued to lead in both accuracy and latency, demonstrating strong reasoning capabilities with efficient response times.
Anthropic Claude 3.5 delivered strong accuracy with slightly slower responses, confirming its reputation for thoughtful, reliable output.
DeepSeek V3 performed competitively, even outperforming some proprietary models on accuracy.
Qwen3 30B and 235B showed impressive accuracy scores, with performance on par with many of the top-tier models. However, latency remains a notable trade-off, particularly for real-time use cases.
OpenAI o3-mini and o4-mini, now added to the Atlas leaderboard, offer an interesting balance: while lighter in design, o3-mini holds its ground on accuracy and leads on latency, making it an appealing option for cost-sensitive or speed-prioritized deployments.
A Broader Look: Accounting Intelligence
We also evaluated models on Accounting Audit, a benchmark testing knowledge of financial documents, audits, and spreadsheet logic.
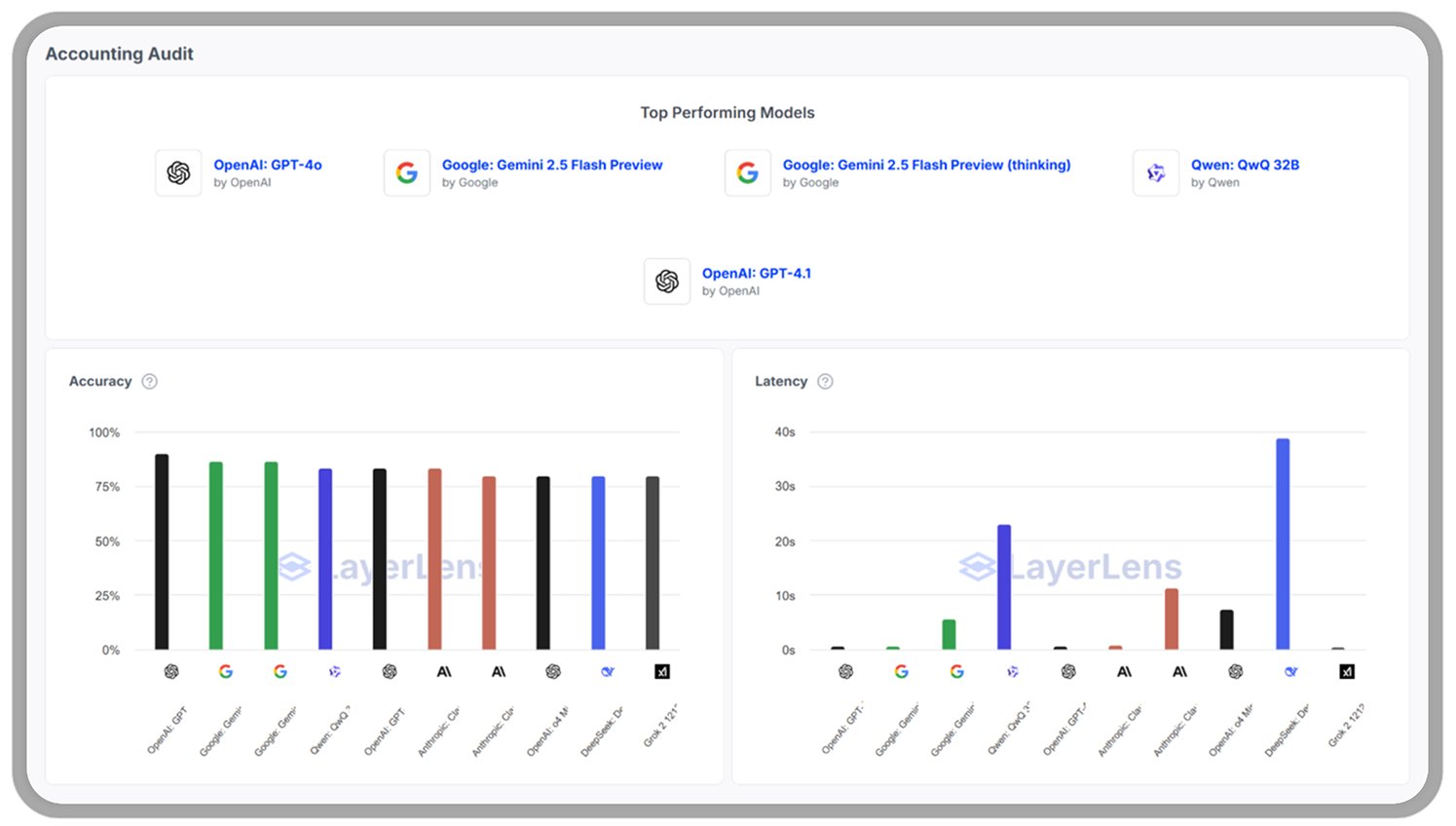
Accounting Audit chart
Google Gemini 2.5 Flash and OpenAI GPT-4o performed best overall—both showed strong accuracy and maintained lower latency, suggesting they’re well-equipped to handle structured, rules-based financial tasks.
Qwen QwQ 32B performed surprisingly well in accuracy but suffered from notably high latency—reinforcing the importance of trade-off analysis in model selection.
This kind of divergence—where a model excels at reasoning but lags in responsiveness—is exactly why targeted benchmarking matters.
Why Finance Needs Better Benchmarks
Financial work is not just about knowledge—it’s about reasoning, precision, and trust. The current lack of comprehensive financial benchmarks makes it hard to:
Choose the right model for industry workflows
Avoid costly implementation errors
Ensure compliance and traceability in model decisions
That’s why at LayerLens, we’re working to close this gap—by publishing detailed performance data on finance tasks, and helping enterprise teams pick the right LLMs with confidence.
Closing Thoughts
As more financial institutions explore generative AI, benchmarking is no longer optional—it’s critical infrastructure.
If you're deploying models in finance, don’t rely on general scores. Look under the hood.
Join our Early Access program to explore these insights firsthand and get full visibility into model performance on real-world financial tasks.
EXPLORE MORE ARTICLES
PREVIOUS

NEXT

