May 14, 2025

LayerLens is building a platform to make it easier to evaluate, benchmark, and understand frontier generative AI model performance.
After many months of iteration and building, we are excited to announce Atlas, an open community resource to visualize the performance of the top AI models through independent, transparent evaluations against benchmarks such as MMLU-Pro, Math-500, and more.
Why Atlas
Most AI benchmarks today come from model creators themselves, or from open-source leaderboards.
The AI community needs a resource that has rich data, is independent, and is easy to understand.
Atlas is designed to fill that gap with:
Independent, transparent evaluations.
In-depth summaries, with prompt by prompt results, for individual eval runs
A fast, no-code interface for comparing models and surfacing trade-offs
What You Can Do Today
With the Atlas Leaderboard now live, you can:
View performance data on over 200 models across 50+ evaluation benchmarks
See how models stack up across reasoning, latency, and robustness
Access our Evaluation Spaces, which are fine-grained dashboards that provide analytics about a specific region, vendor, or capability.
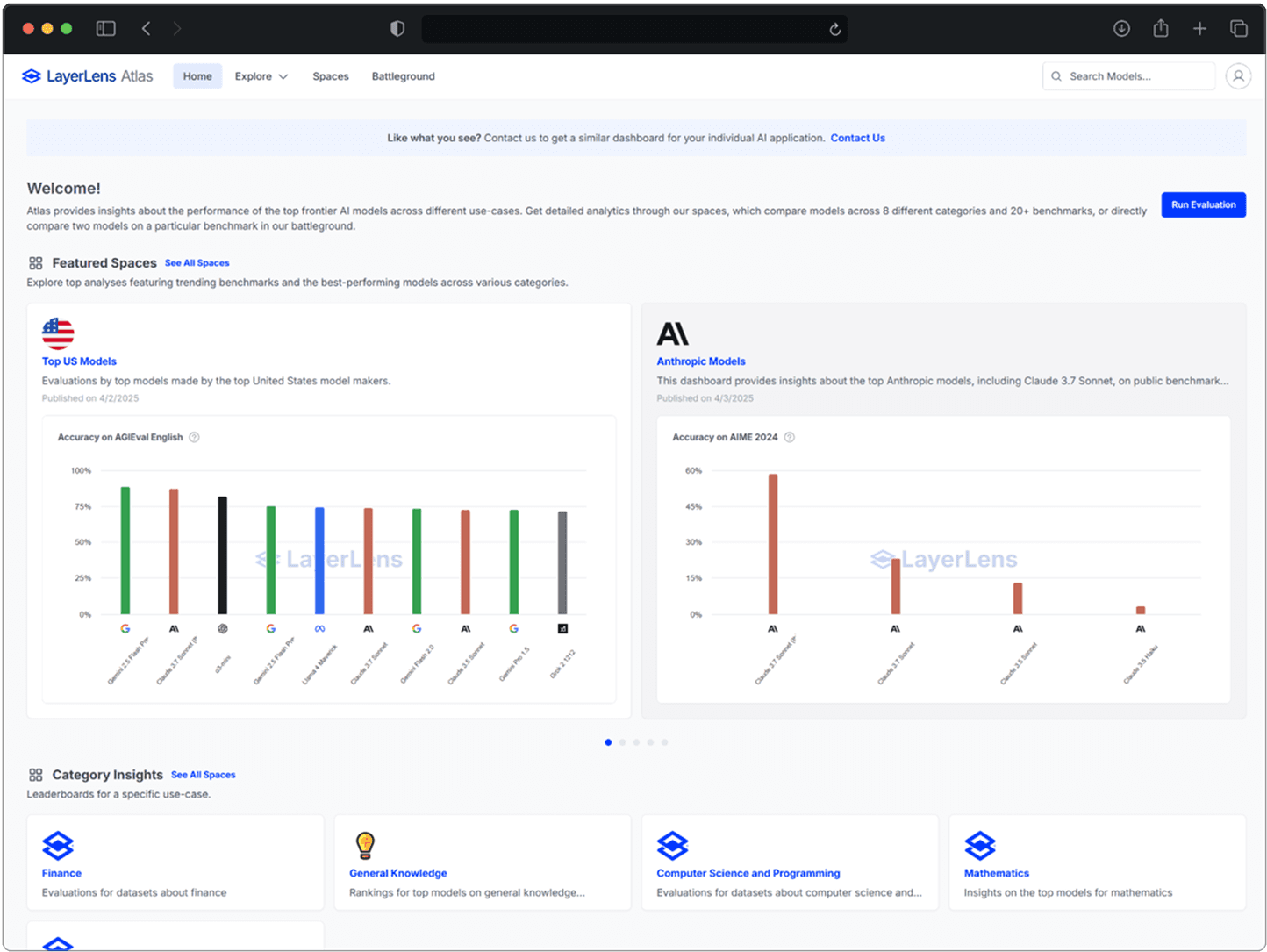
Atlas Leaderboard homepage
All data is free for access to the general public. Some data does require signing up for a free account on our platform.
Who It’s For
The Atlas Leaderboard is designed for:
Developers comparing foundation models for their product workflows
Data science teams deploying LLMs internally
Enterprises assessing vendor performance and AI risk
Researchers interested in frontier model behavior at scale
Explore Atlas Today
The Atlas Leaderboard is now live at app.layerlens.ai.
You can start browsing evaluation results immediately. To unlock deeper insights, model views, and comparison tools, simply sign in—it’s free.
What’s Next
We’re just getting started. LayerLens is building an all in one platform for the evaluation of models, agents, and AI applications.
Stay tuned and follow us for more details on our vision, goals, and updates to Atlas.
We’ll also be announcing a new webinar in the coming days exploring key lessons learned from benchmarking the latest wave of generative models.
Stay tuned—and thank you for helping us raise the standard for AI evaluation.
-The LayerLens Team
EXPLORE MORE ARTICLES
PREVIOUS

NEXT

