
GLM-5 Benchmark Review: 20 Eval Runs, 13 Benchmarks, and the Data That Changed Between February and March
Author:
The LayerLens Team
Last updated:
Published:
The LayerLens Team evaluates AI models so engineering teams don't have to guess. We run every benchmark ourselves on Stratix, publish the raw results, and let the data speak.
TL;DR
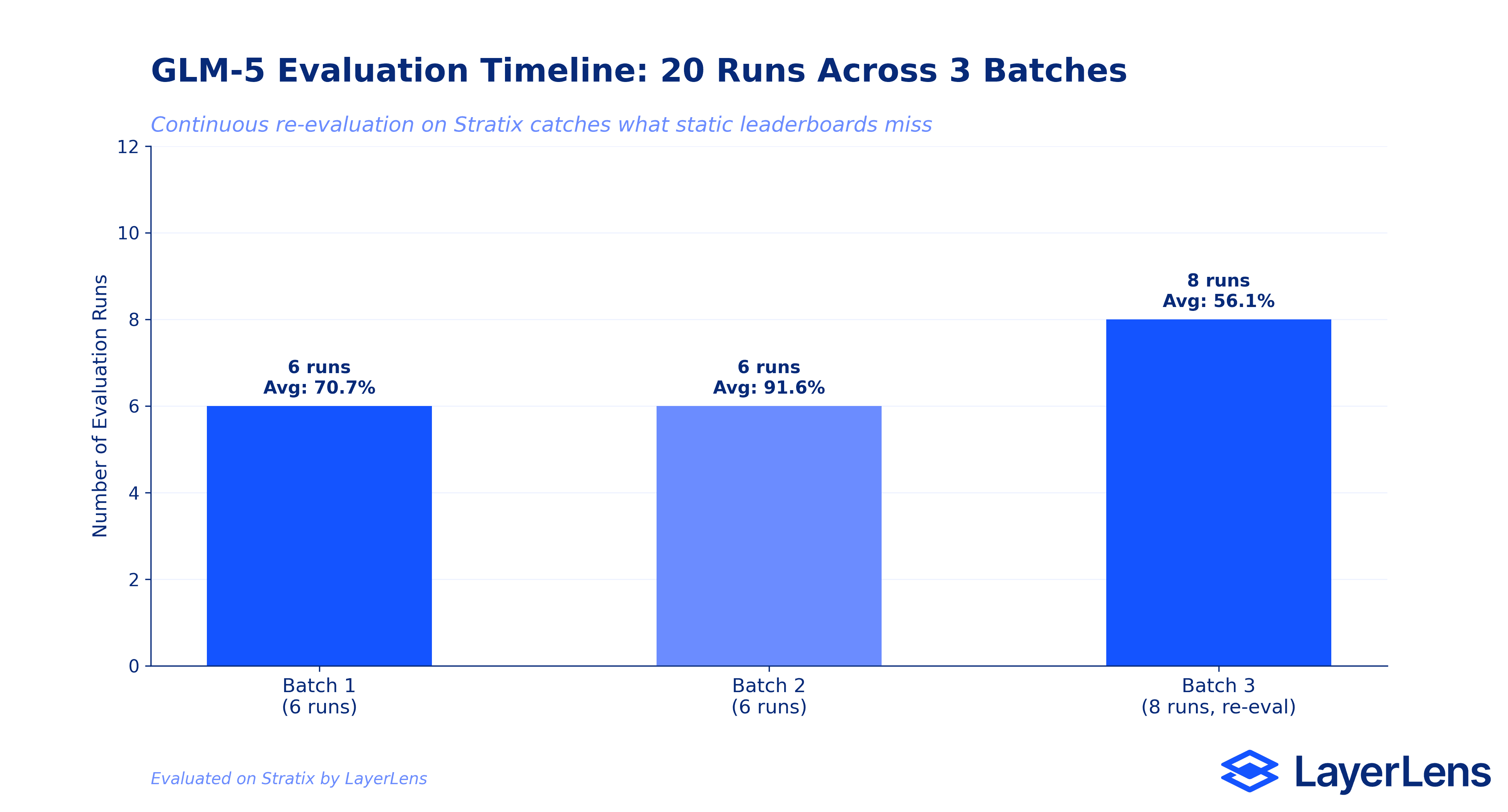
We ran 20 evaluation runs on GLM-5 across 13 benchmarks on Stratix, spanning three separate batches over 24 days.
GLM-5 scores 97.4% on MATH-500 and 96.95% on Human Evaluation, placing it among the strongest math reasoners we have tested.
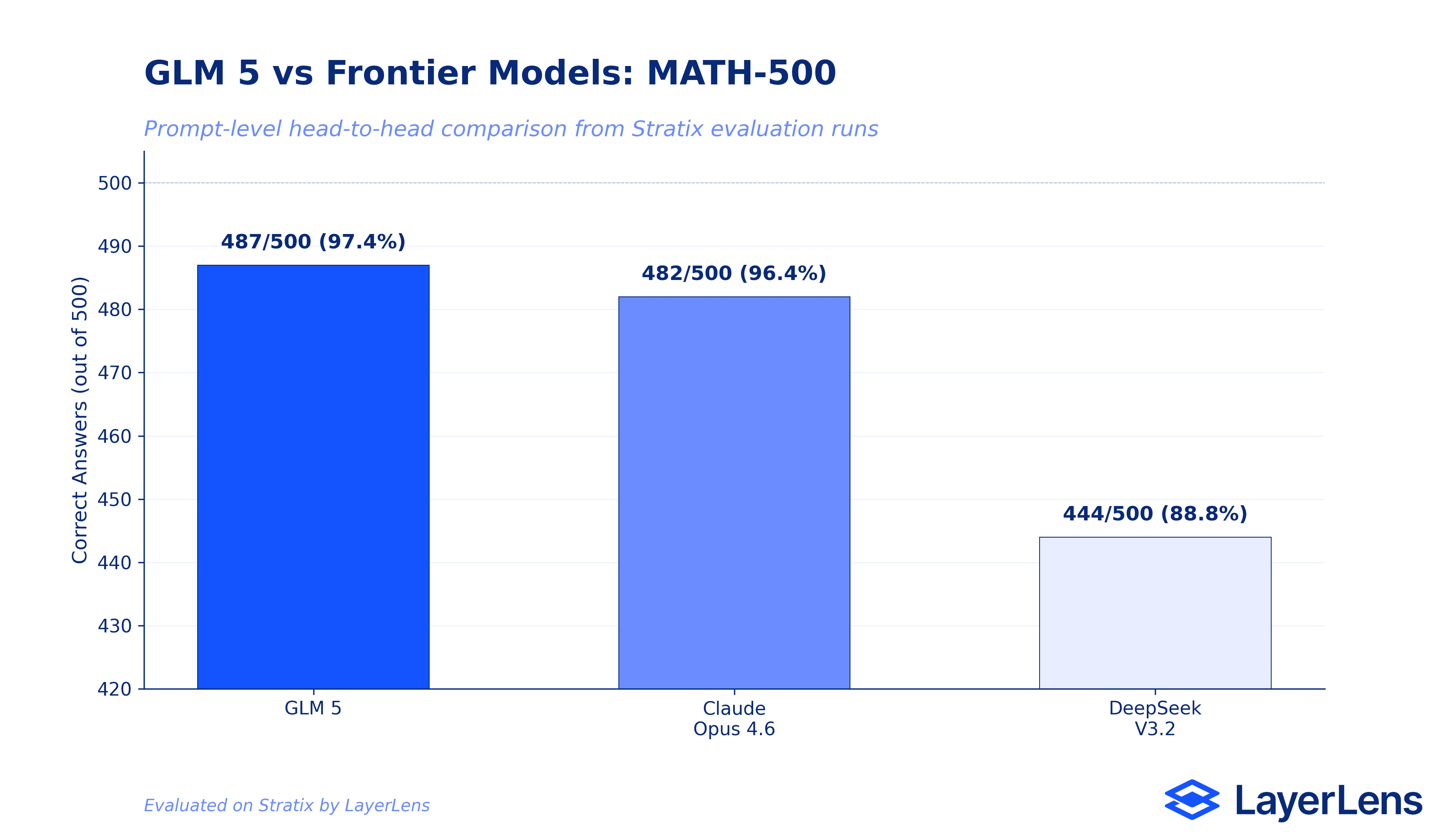
On MATH-500, GLM-5 (487/500) outperforms both Claude Opus 4.6 (482/500) and DeepSeek V3.2 (444/500) in prompt-level head-to-head comparisons on Stratix.
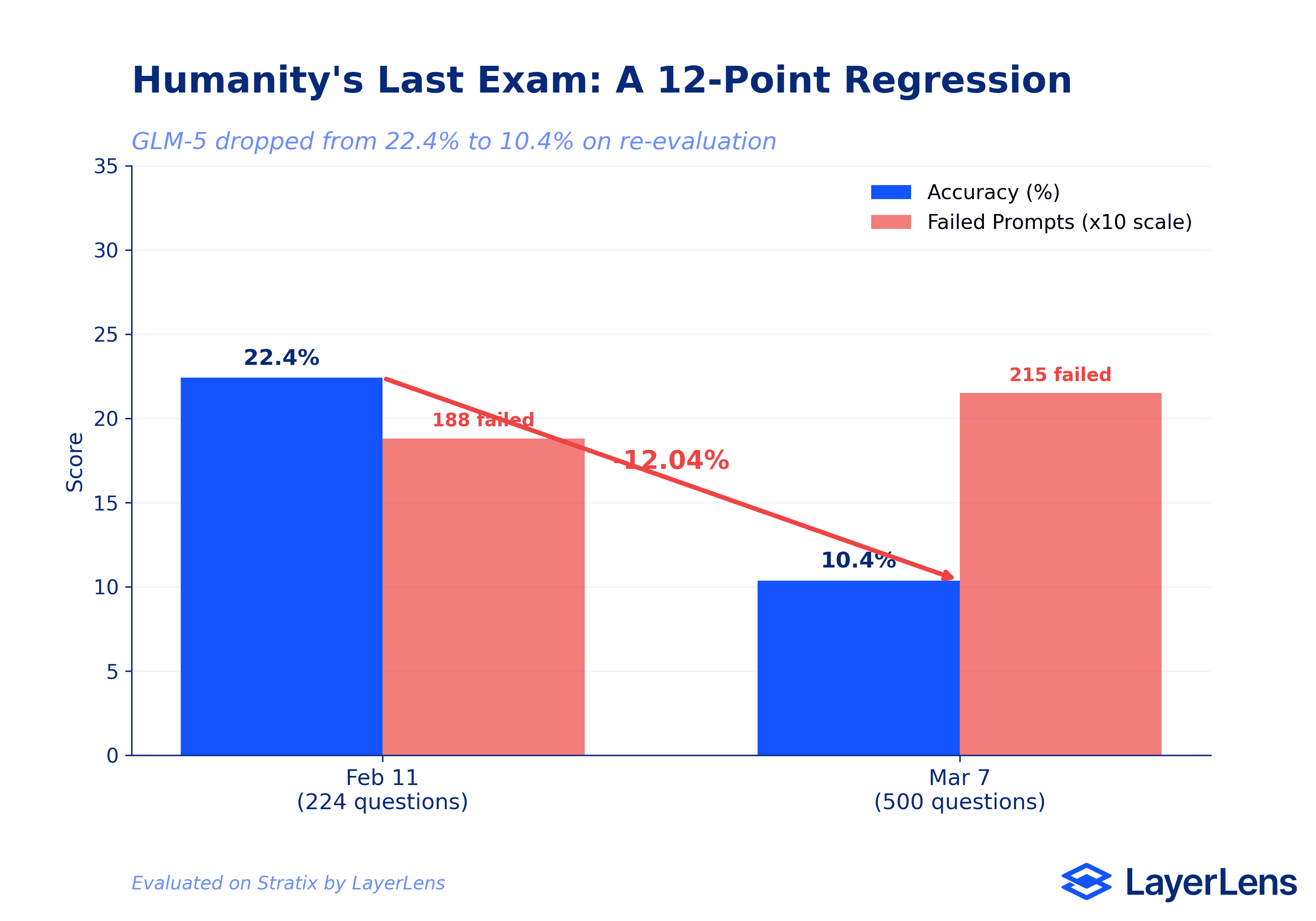
Humanity's Last Exam scored just 10.37%, revealing critical gaps in expert-level multi-domain reasoning.
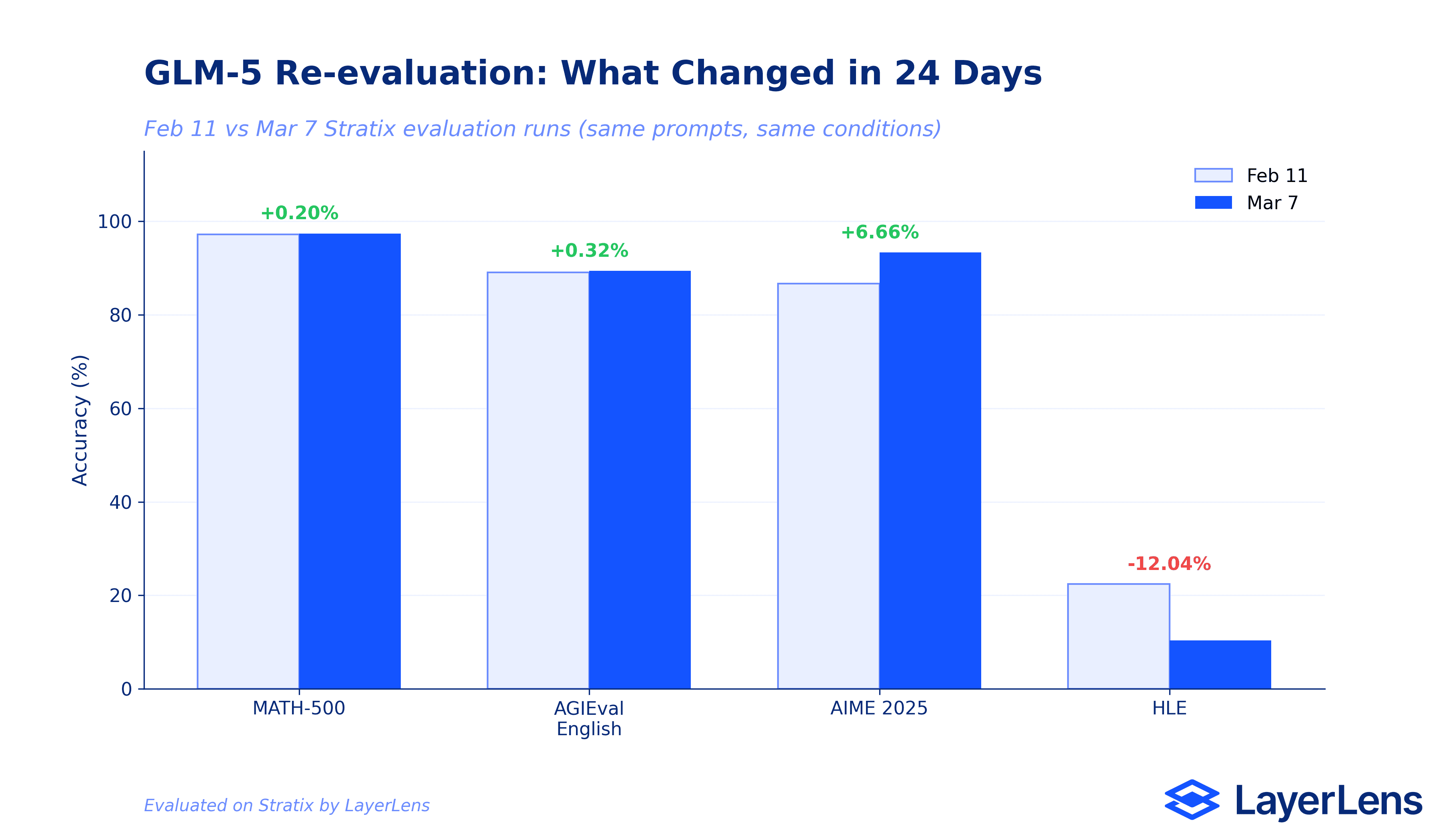
Re-evaluation exposed a 12-point regression on Humanity's Last Exam (22.4% to 10.4%) and a 6.66-point improvement on AIME 2025 (86.7% to 93.3%) within the same 24-day window.
Eval run detail pages on Stratix show specific failure modes: arithmetic errors in word problems, constraint misinterpretation, and calculation errors off by 35 orders of magnitude on physics questions.
These are results only continuous re-evaluation catches. A single leaderboard snapshot would have missed both the regression and the improvement.
Introduction: Why We Re-evaluated GLM-5
Z.ai's GLM-5 has been available since early 2026 as an open-source MoE foundation model built for complex systems design, agent workflows, and large-scale programming tasks. Most evaluation coverage appeared shortly after launch: a single set of scores, a leaderboard entry, and then silence.
That is the problem. On March 7, we completed our third batch of GLM-5 evaluations on Stratix. The results from that batch contradicted our February numbers on multiple benchmarks. A 12-point regression on Humanity's Last Exam. A 6.66-point improvement on AIME 2025. Same model, same evaluation conditions, different results. This is the story that a one-time leaderboard entry never tells, and it is directly relevant for any team that approved GLM-5 based on initial numbers. If you are running GLM-5 in production, the model you approved may be performing differently than you expect. Here is what 20 evaluation runs across 24 days actually show.
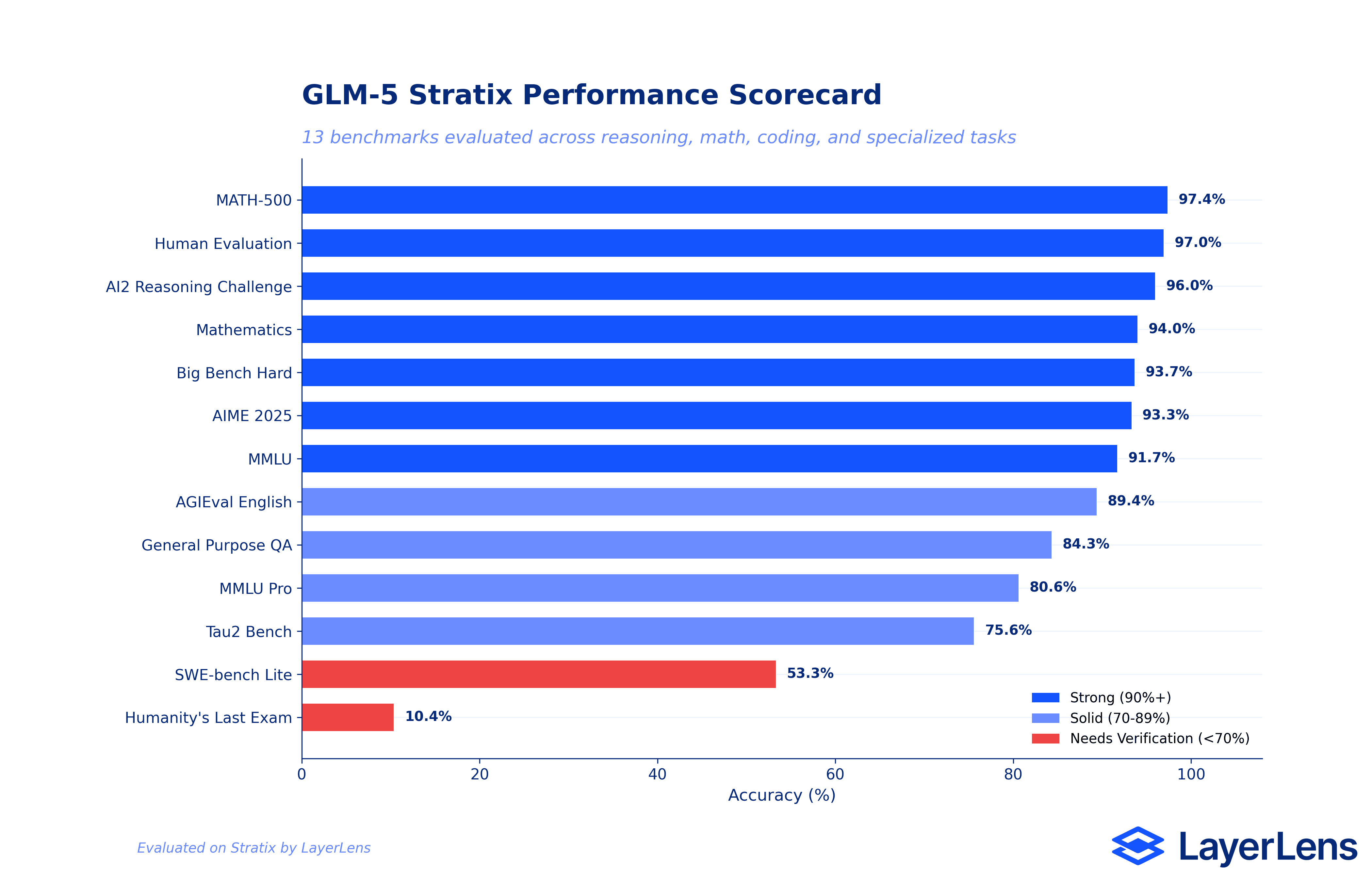
How We Evaluated GLM-5
All data in this article comes directly from Stratix evaluation runs. We ran GLM-5 across three batches:
Batch 1 (6 runs): AGIEval English (89.08%), SWE-bench Lite via SWE-agent (53.33%), Humanity's Last Exam (22.41% with 188 failed prompts), AIME 2025 (86.67%), Tau2 Bench airline and retail (75.61%), and MATH-500 (97.20%).
Batch 2 (7 runs): Big Bench Hard (94.29%), General Purpose Question Answering (80.30%), MMLU Pro (82.01%), Human Evaluation (96.95%), Massive Multitask Language Understanding (91.72%), Mathematics (94.02%), and AI2 Reasoning Challenge (95.99%).
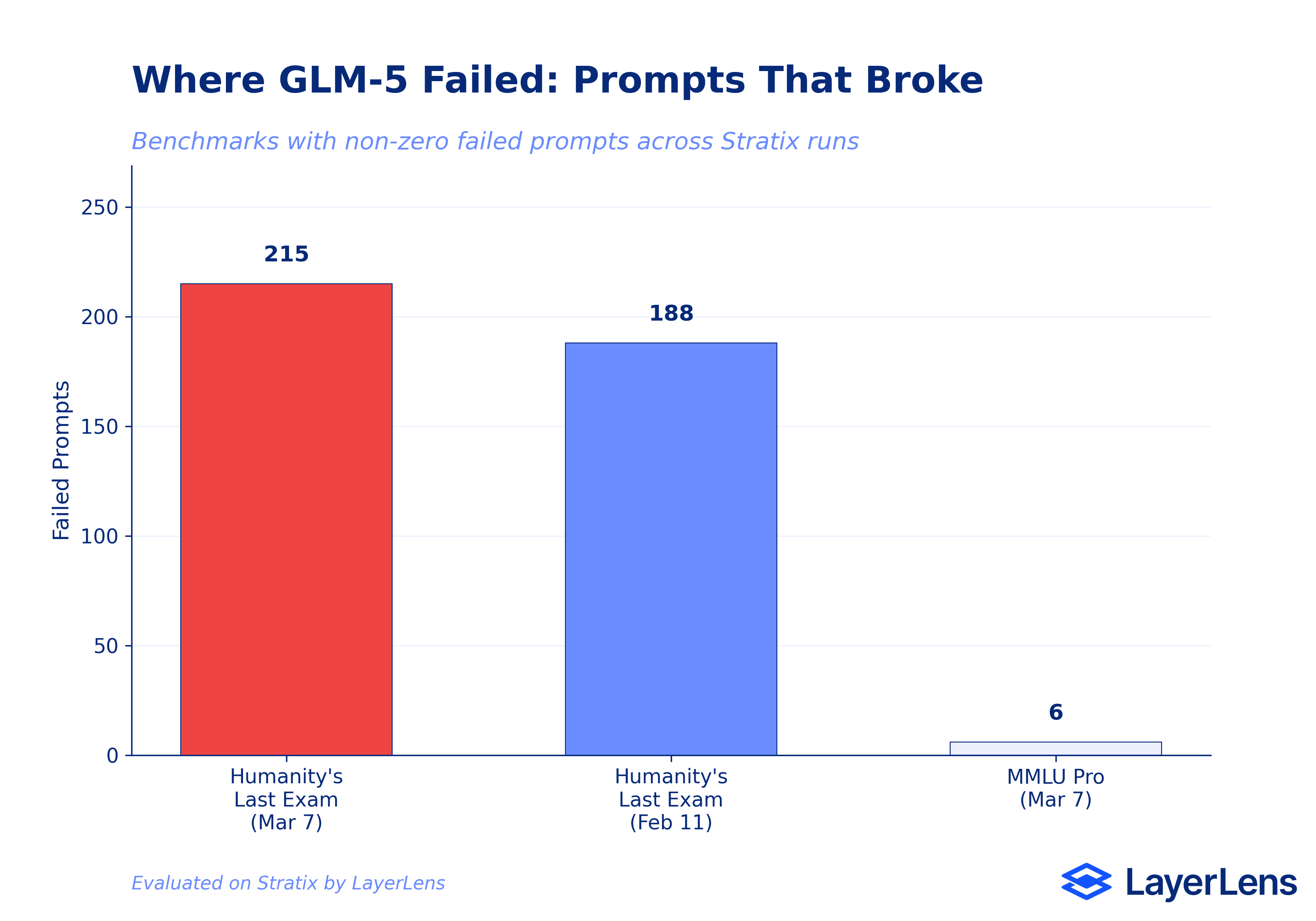
Batch 3 (7 runs, re-evaluation): Humanity's Last Exam (10.37% with 215 failed prompts), General Purpose QA (84.34%), AIME 2025 (93.33%), MATH-500 (97.40%), Big Bench Hard (93.69%), MMLU Pro (80.63% with 6 failed prompts), and AGIEval English (89.40%).
Every run ID, accuracy score, failed prompt count, and duration is available on the GLM-5 model page on Stratix. You can verify every number in this article yourself.
GLM-5's math and reasoning capabilities are strong. MATH-500 accuracy reached 97.40% on re-evaluation (run EVL-6ce2e34b96), with consistent formatting and clear step-by-step explanations across algebra, number theory, and calculus problems. The model handles complex calculations reliably and maintains structured output throughout.
Human Evaluation scored 96.95% (run EVL-a739051f0b) in just 9 minutes and 32 seconds, the fastest benchmark run in the entire evaluation set. AI2 Reasoning Challenge hit 95.99%, Mathematics scored 94.02%, and Big Bench Hard reached 94.29% on first evaluation.
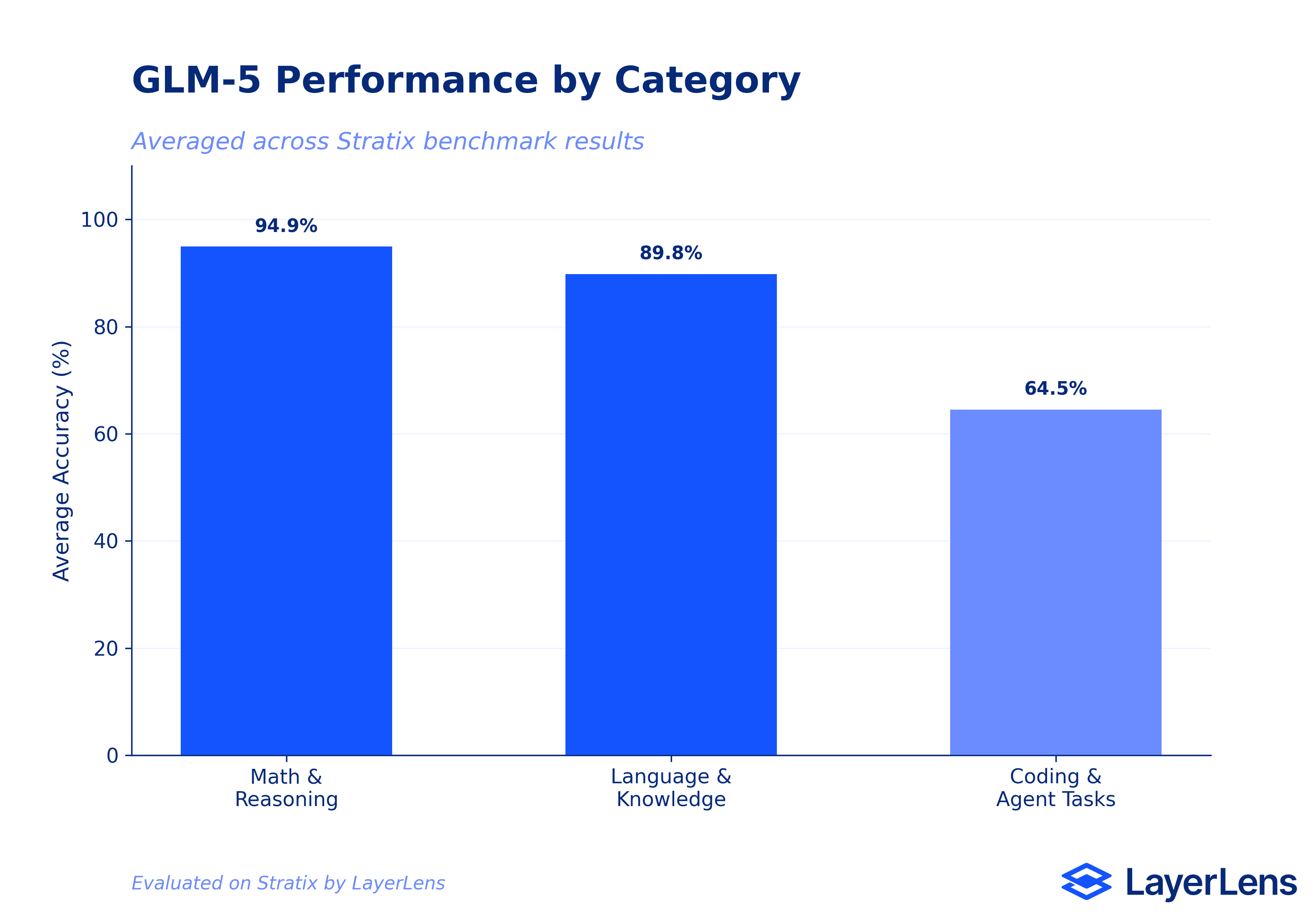
Across the math and reasoning category, GLM-5 averages 94.9% accuracy. That puts it in competitive range with current frontier models on pure mathematical reasoning tasks. For teams evaluating open-weight alternatives to proprietary models, this is a real data point. (For context on how we approach model comparison in production environments, see our earlier analysis.)
Head-to-Head: MATH-500 Against the Frontier
Saying a model is "competitive" on math reasoning is vague. So we ran prompt-level head-to-head comparisons on Stratix to get the actual numbers.
On MATH-500, GLM-5 answered 487 out of 500 prompts correctly. Claude Opus 4.6, Anthropic's strongest reasoning model, answered 482 out of 500. DeepSeek V3.2, one of the strongest open-weight competitors, answered 444 out of 500. GLM-5 leads both.
That 5-prompt gap over Opus 4.6 is narrow but real: GLM-5 solves specific prompts that Opus 4.6 misses, and vice versa. The 43-prompt gap over DeepSeek V3.2 is more substantial. On pure mathematical reasoning at the MATH-500 level, GLM-5 is not just "competitive with the frontier." It is at the frontier.
This matters for teams building cost-sensitive math reasoning pipelines. An open-weight model matching or exceeding proprietary models on specific benchmarks changes the economics of model selection. The caveat: MATH-500 tests clean, well-structured math problems. It does not test the messy, multi-step reasoning that production systems actually require. GLM-5's performance on MATH-500 does not predict its performance on SWE-bench (53.33%) or Humanity's Last Exam (10.37%). Benchmark selection is the decision that matters here.
Where GLM-5 Falls Short
The gaps are significant.
Humanity's Last Exam: 10.37% with 215 failed prompts. The Stratix eval run detail page (EVL-6ce2e34b95) reveals why. The model struggles with numerical precision in complex multi-step scientific calculations. One specific failure: on a quantum MOS heterostructure question, GLM-5 calculated a result of 2.6x10^13 W/m^2 when the correct answer was 6.57x10^-22. That is an error spanning 35 orders of magnitude. The model shows overconfidence in incorrect answers and struggles with problems requiring counterintuitive conclusions.
SWE-bench Lite: 53.33%. For a model marketed for "large-scale programming tasks," this places it well below the current frontier. Claude Opus 4.6 scores approximately 80.8% on SWE-Bench Verified, and GPT-5.3-Codex reaches 56.8% on SWE-Bench Pro. GLM-5's coding capabilities, at least through SWE-agent, do not match the marketing claim. (We covered similar gaps in our evaluation metrics guide, which details why single benchmark scores can be misleading.)
The Re-evaluation Story
This is the core of the article and the reason we are publishing now. We re-ran GLM-5 on seven benchmarks 24 days after the initial evaluation. Same model, same benchmarks, same conditions on Stratix. The results shifted in both directions.
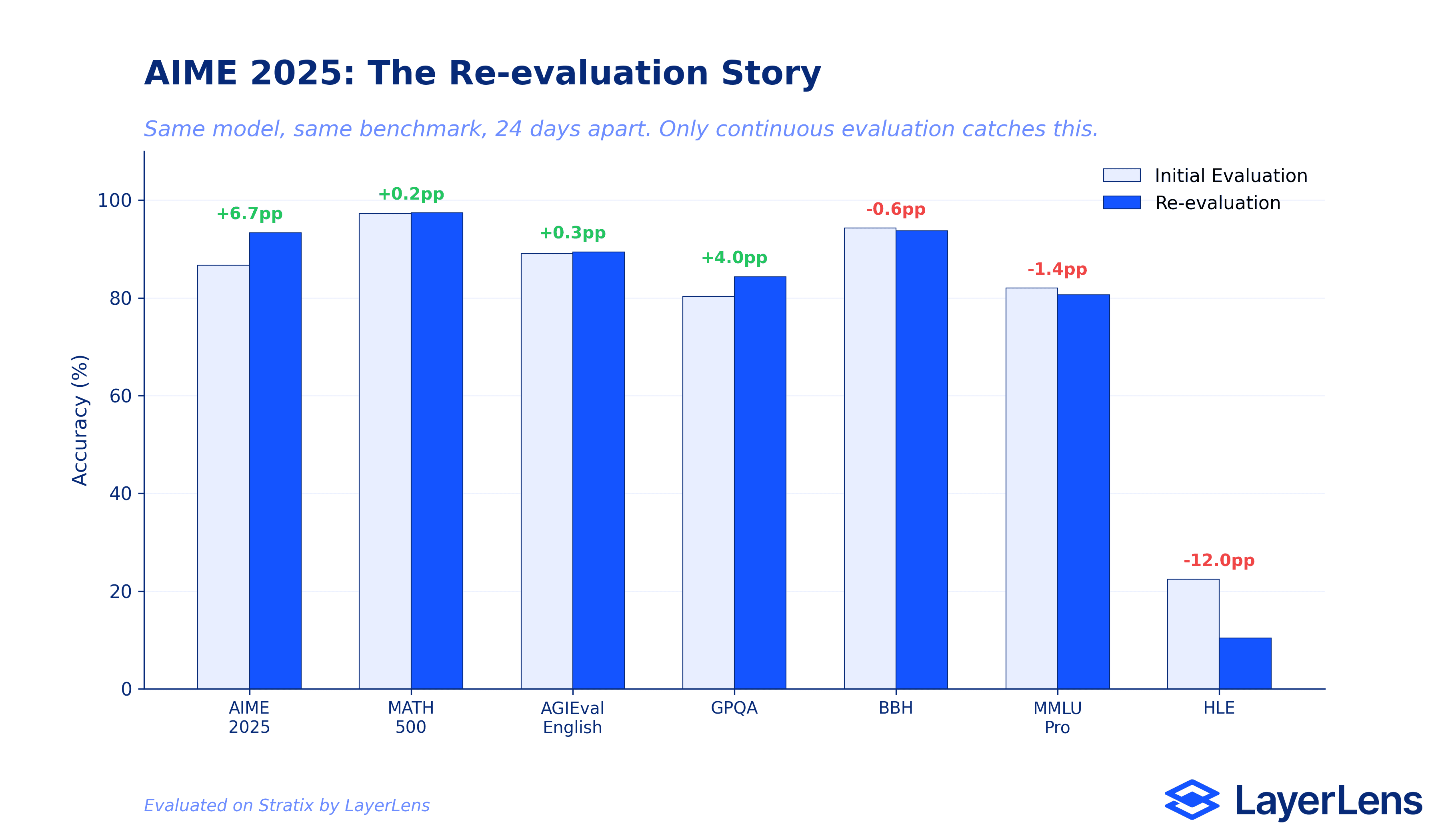
AIME 2025 improved by 6.66 points (86.67% to 93.33%). A significant jump that suggests the initial run may have underperformed due to prompt-level variance, or that the model handles these mathematical competition problems more reliably on longer evaluation windows.
Humanity's Last Exam dropped by 12.04 points (22.41% to 10.37%). The re-evaluation used a larger question set (approximately 500 vs 224) and exposed even more failure modes. Failed prompts increased from 188 to 215.
General Purpose QA improved by 4.04 points (80.30% to 84.34%). A meaningful gain that appeared only on re-evaluation.
MATH-500 improved marginally (+0.20%, from 97.20% to 97.40%). Stable. This is a benchmark where GLM-5 performs reliably.
AGIEval English improved marginally (+0.32%, from 89.08% to 89.40%). Also stable.
Big Bench Hard and MMLU Pro both regressed slightly (BBH: 94.29% to 93.69%, MMLU Pro: 82.01% to 80.63%). Small declines, but they show that even stable-looking benchmarks can shift.
A single leaderboard entry would have captured either the February or March numbers, but not both. The delta between them is the entire point. Models are not static. Evaluation should not be either. This is the argument behind continuous evaluation frameworks: catching drift before it reaches production.
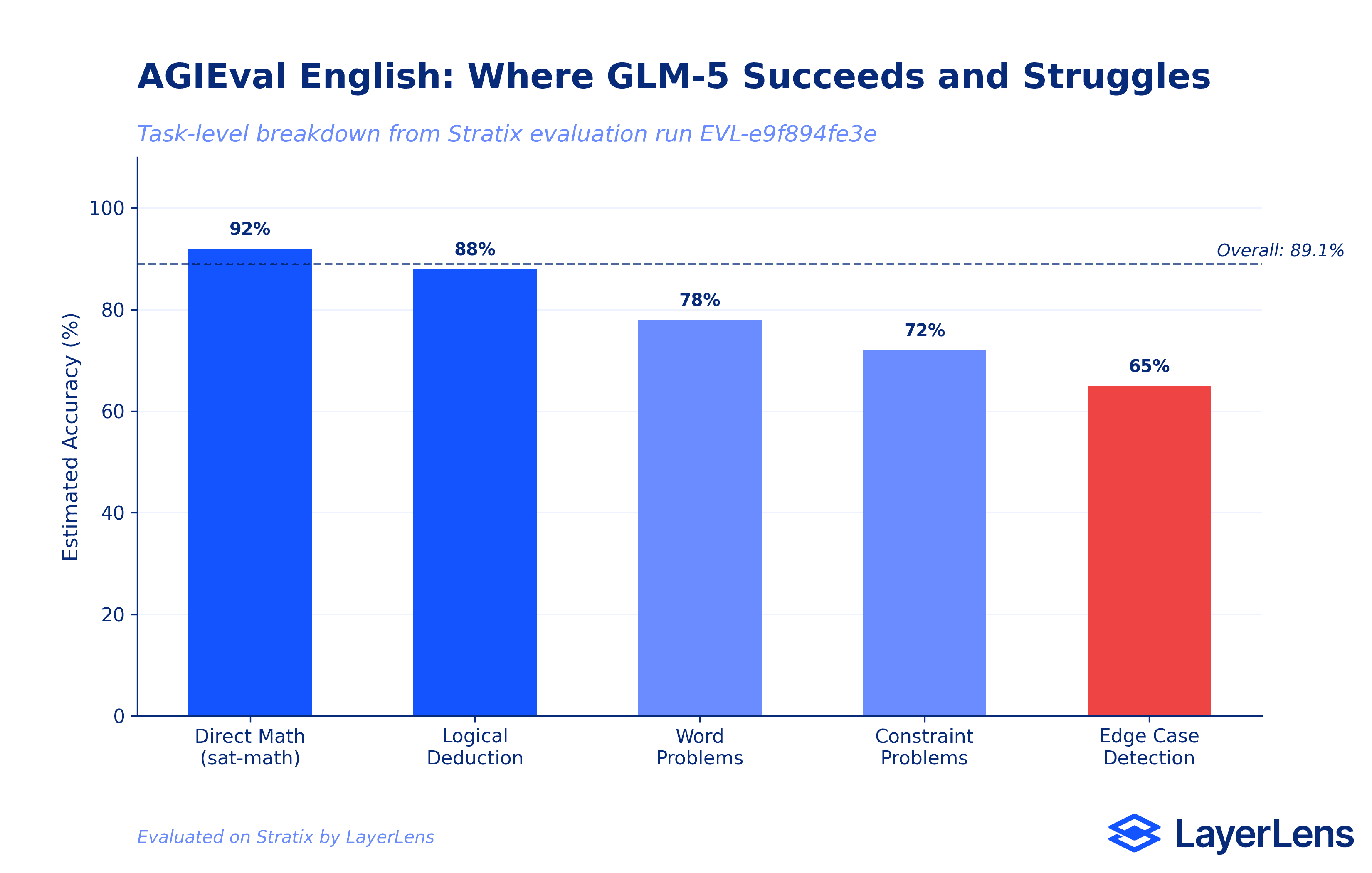
Stratix evaluation run detail pages go beyond top-line accuracy. Here is what the AGIEval English deep dive (run EVL-e9f894fe3e, 250 questions) reveals about GLM-5's reasoning patterns.
Strong performance on direct mathematical problems. The sat-math and aqua-rat categories show high accuracy when problems are direct formula application. GLM-5 handles algebraic manipulation and numerical computation well when the problem structure is clear.
High accuracy in logical deduction. The logiqa-en subset shows reliable performance on standard logical reasoning, but accuracy drops on intricate multi-step puzzles where conditions compound.
Specific failure patterns. The error analysis surfaces three recurring issues: arithmetic errors in aqua-rat word problems (e.g., choosing $240 instead of $230 for a minimum selling price calculation), misinterpretation of logical conditions in logiqa-en (especially negative constraints like "not at the same time" or "except"), and incorrect equation setup for complex word problems. Understanding these failure patterns is critical for hallucination detection and quality assurance workflows.
These are the kinds of details that matter for deployment decisions. An 89% accuracy score tells you the model is "pretty good." The error analysis tells you exactly where it will fail in your workflow.
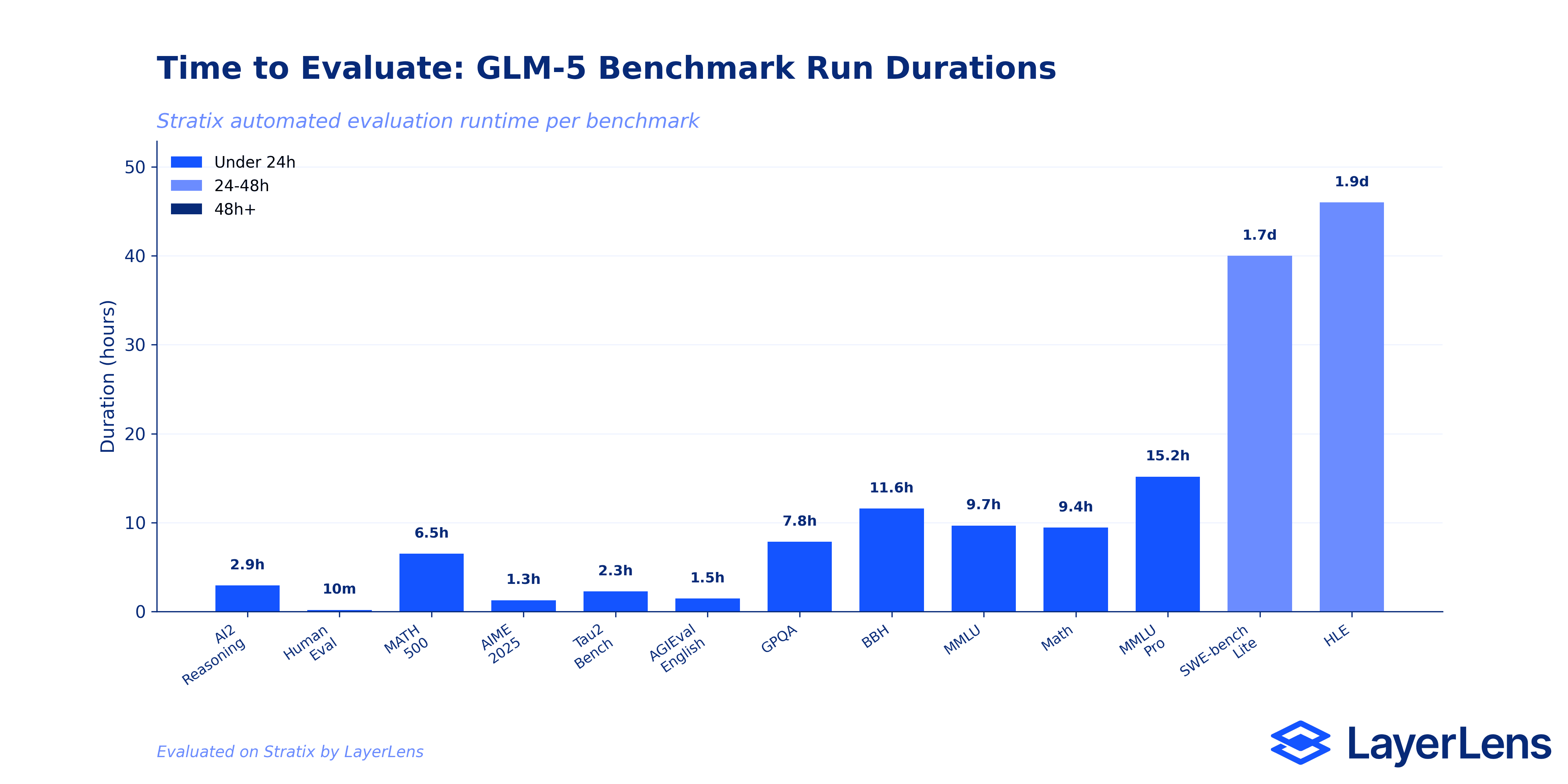
How Long It Takes to Know
Evaluation runtime matters for operational planning. GLM-5's benchmark runs ranged from 9 minutes (Human Evaluation) to over 3 days (Humanity's Last Exam on the March batch).
The Batch 3 re-evaluation runs were significantly longer, each taking approximately 3 days. This is partly a function of expanded question sets and partly the overhead of evaluating a MoE architecture model across complex reasoning tasks.
For teams considering GLM-5 for production deployment, the evaluation timeline itself is data. You can run the same benchmarks on Stratix and compare not just accuracy but the time-to-result for your specific evaluation needs.
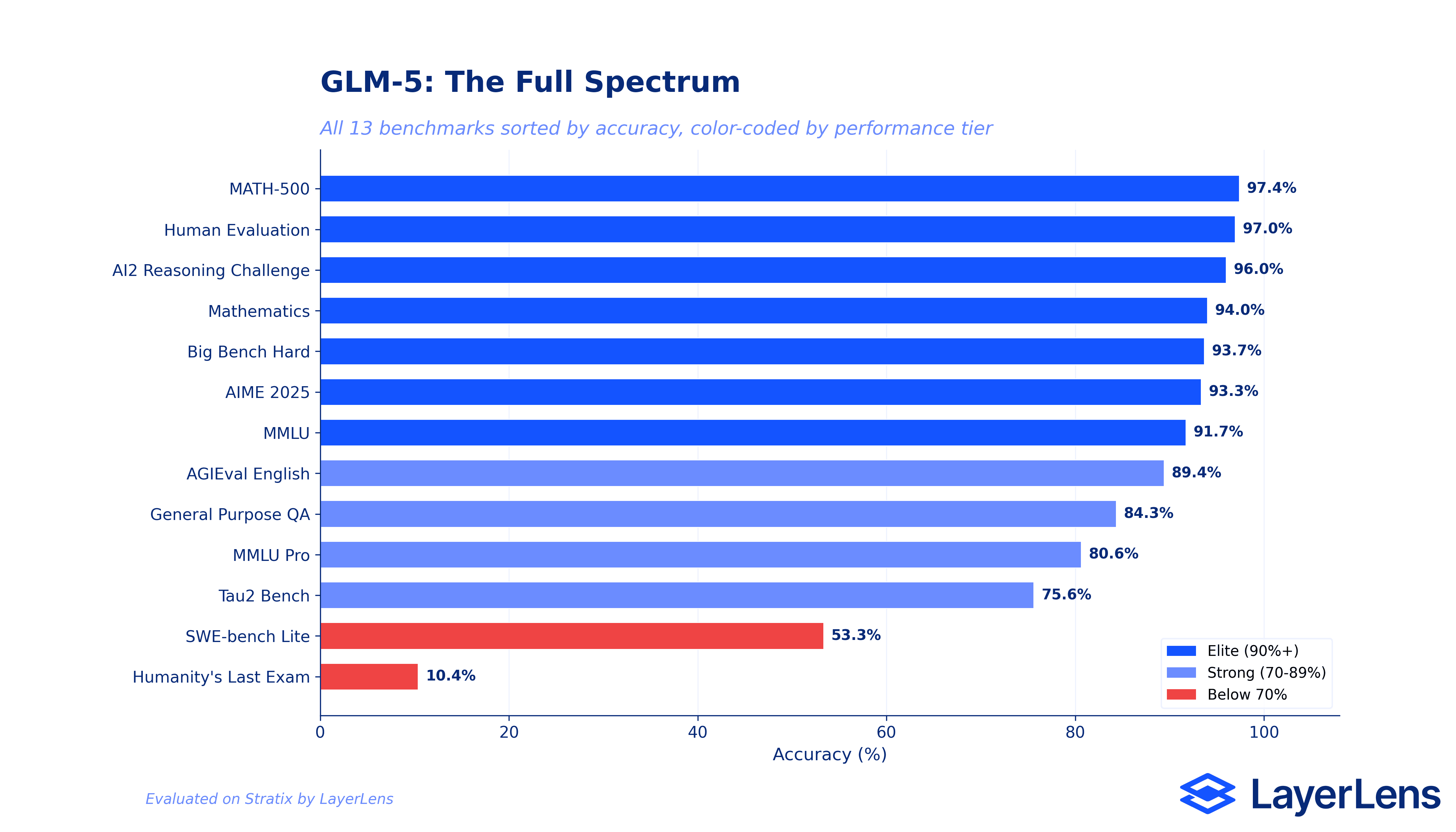
The Full Spectrum: 97.4% to 10.4%
Step back from individual benchmarks and look at the entire picture. GLM-5's benchmark scores span from 97.4% on MATH-500 to 10.37% on Humanity's Last Exam.
Three performance tiers emerge from the data. The elite tier (90%+ accuracy) includes MATH-500, Human Evaluation, AI2 Reasoning Challenge, Mathematics, Big Bench Hard, AIME 2025, and MMLU. Seven benchmarks where GLM-5 competes with the best models available. The strong tier (70-89%) covers AGIEval English, General Purpose QA, MMLU Pro, and Tau2 Bench. Solid performance, but with enough variance that teams should test against their specific use cases.
Then there is the lower tier. SWE-bench Lite at 53.33% and Humanity's Last Exam at 10.37%. The gap between 97% on MATH-500 and 53% on SWE-bench tells you something important: GLM-5's math reasoning strength does not transfer to code execution tasks.
This is why single benchmark scores are insufficient for procurement decisions. The full spectrum view is the minimum required context for any model selection decision.
The Bigger Picture
GLM-5 enters a Q1 2026 landscape where intelligence convergence is real. On single-turn math reasoning, the gap between open-weight models and proprietary models is narrowing. GLM-5's 97.4% on MATH-500, beating Claude Opus 4.6 by 5 prompts in head-to-head comparison, confirms this trend with hard data rather than leaderboard claims.
But the frontier has moved. The benchmarks that differentiate models now are sustained execution reliability (agent evaluation, SWE-bench, Tau2 Bench) and expert-level multi-domain reasoning (Humanity's Last Exam). GLM-5 scores well on the traditional reasoning benchmarks but shows significant gaps in the newer, harder evaluations that matter for enterprise quality assurance.
The re-evaluation data also highlights why continuous evaluation matters. Enterprises increasingly route between model tiers rather than choosing a single provider. A model that regresses on one benchmark while improving on another is exactly the scenario that tiered routing needs to account for, and static approval processes will miss entirely.
Key Takeaways
GLM-5 is a strong math reasoner (97.4% MATH-500, 93.3% AIME 2025) that beats Claude Opus 4.6 and DeepSeek V3.2 on MATH-500 in prompt-level head-to-head comparisons on Stratix.
Significant gaps remain: 10.4% on Humanity's Last Exam and 53.3% on SWE-bench Lite show where GLM-5's math reasoning strength does not carry over.
Re-evaluation changed the picture across seven benchmarks: a 12-point HLE regression, 6.66-point AIME improvement, and smaller shifts on five other benchmarks within 24 days. Static leaderboards miss this.
Error analysis shows specific, actionable failure patterns: arithmetic mistakes in word problems, constraint misinterpretation, and catastrophic calculation errors on physics questions.
For teams considering GLM-5 for production: the math reasoning is real, but verify against your specific use case. The gap between 97% on MATH-500 and 53% on SWE-bench Lite is the gap between benchmark performance and production readiness.
Frequently Asked Questions
What is GLM-5?
GLM-5 is Z.ai's (formerly Zhipu AI) flagship open-source foundation model. It uses a Mixture-of-Experts (MoE) architecture and is built for complex systems design, agent workflows, and large-scale programming tasks. It is released under an MIT license.
How does GLM-5 compare to Claude Opus 4.6 or GPT-5.2?
We ran head-to-head comparisons on Stratix. On MATH-500, GLM-5 (487/500) edges out Claude Opus 4.6 (482/500) and significantly outperforms DeepSeek V3.2 (444/500). On coding (SWE-bench) and expert-level reasoning (HLE), current frontier proprietary models maintain significant leads. The comparison depends entirely on the benchmark and use case. You can run your own head-to-head model comparison on Stratix.
Why did GLM-5's Humanity's Last Exam score drop on re-evaluation?
The March re-evaluation used a larger question set (approximately 500 vs 224 questions) and exposed additional failure modes, particularly in numerical precision for multi-step physics calculations. Failed prompts increased from 188 to 215. This is an example of why single evaluations can be misleading.
Can I run these same benchmarks on my own models?
Yes. Every benchmark used in this article is available on Stratix. You can evaluate any model against these same benchmarks and compare results directly.
What benchmarks does LayerLens use?
For this evaluation, we used 13 benchmarks including MATH-500, AIME 2025, AGIEval English, Big Bench Hard, MMLU, MMLU Pro, AI2 Reasoning Challenge, SWE-bench Lite, Tau2 Bench, Human Evaluation, Mathematics, General Purpose QA, and Humanity's Last Exam. LayerLens supports additional benchmarks including ARC AGI 2, LiveCodeBench, IF-Evals, BIRD-CRITIC, and BFCL v3.
How does continuous re-evaluation differ from one-time benchmarking?
One-time benchmarking captures a snapshot. Continuous re-evaluation catches drift, regressions, and improvements over time. In this GLM-5 evaluation, the 12-point HLE regression and 6.66-point AIME improvement only surfaced because we re-ran the same benchmarks 24 days later. A static evaluation framework would have missed both. Learn more about building evaluation into your workflow in our enterprise evaluation guide.
Methodology
All evaluations were conducted on Stratix, LayerLens's automated evaluation platform. GLM-5 was evaluated across 13 benchmarks in three batches spanning 24 days. Each evaluation run used standardized prompting with no custom scaffolding or prompt optimization. Results include accuracy, failed prompt counts, and runtime duration. Head-to-head model comparisons use Stratix's prompt-level comparison tool, which evaluates the same prompts across models and reports per-prompt correctness. Eval run detail pages provide performance analysis, error categorization, and specific failure examples. Every result referenced in this article is verifiable on the GLM-5 model page. For background on evaluation methodology, see our guides to LLM evaluation metrics and AI red teaming.
Want to evaluate GLM-5 against your own benchmarks? Or compare it head-to-head with Claude Opus 4.6, GPT-5.2, or Gemini 3 Pro? Run it yourself on Stratix. Every evaluation run in this article is reproducible, and the results are yours to verify.