
Gemini 3.1 Flash Lite Benchmark Results vs. GPT-5 Nano, Qwen3.5: Efficiency Model Comparison
Author:
The LayerLens Team
Last updated:
Published:
Independent evaluation by LayerLens on MMLU Pro, GPQA Diamond, LiveCodeBench, and 9 more benchmarks. All results verified on LayerLens's Stratix platform with prompt-level transparency.
TL;DR
Google released Gemini 3.1 Flash Lite on March 3, 2026. In independent evaluation by LayerLens on Stratix, Flash Lite achieved 83.0% accuracy on MMLU Pro at 1.38 seconds average latency across 12 benchmarks and 21,041 evaluation items. Qwen3.5 27B scores 3.3 points higher but runs 42x slower; GPT-5 Nano scores 57.5% at 12x the latency. Flash Lite is the highest-accuracy efficiency model in this comparison at sub-2-second latency. Every result is verified with full prompt and output transparency on Stratix Public.
What Is Gemini 3.1 Flash Lite?
Google launched Gemini 3.1 Flash Lite Preview as the efficiency tier of their Gemini 3.1 family. The positioning is straightforward: fast inference, low cost, production-ready at scale.
Key specifications:
Pricing: $0.25/1M input tokens, $1.50/1M output tokens
Context window: 1 million tokens
Input modalities: Text, image, speech, video
Output: Text
Output speed: ~362 tokens per second (per Artificial Analysis)
Adjustable thinking levels: Developers can tune reasoning depth vs. speed
Availability: Google AI Studio and Vertex AI (preview)
At one-eighth the cost of Gemini 3 Pro, Flash Lite targets high-volume inference pipelines, classification tasks, content generation at scale, and any workload where per-request cost and latency compound.
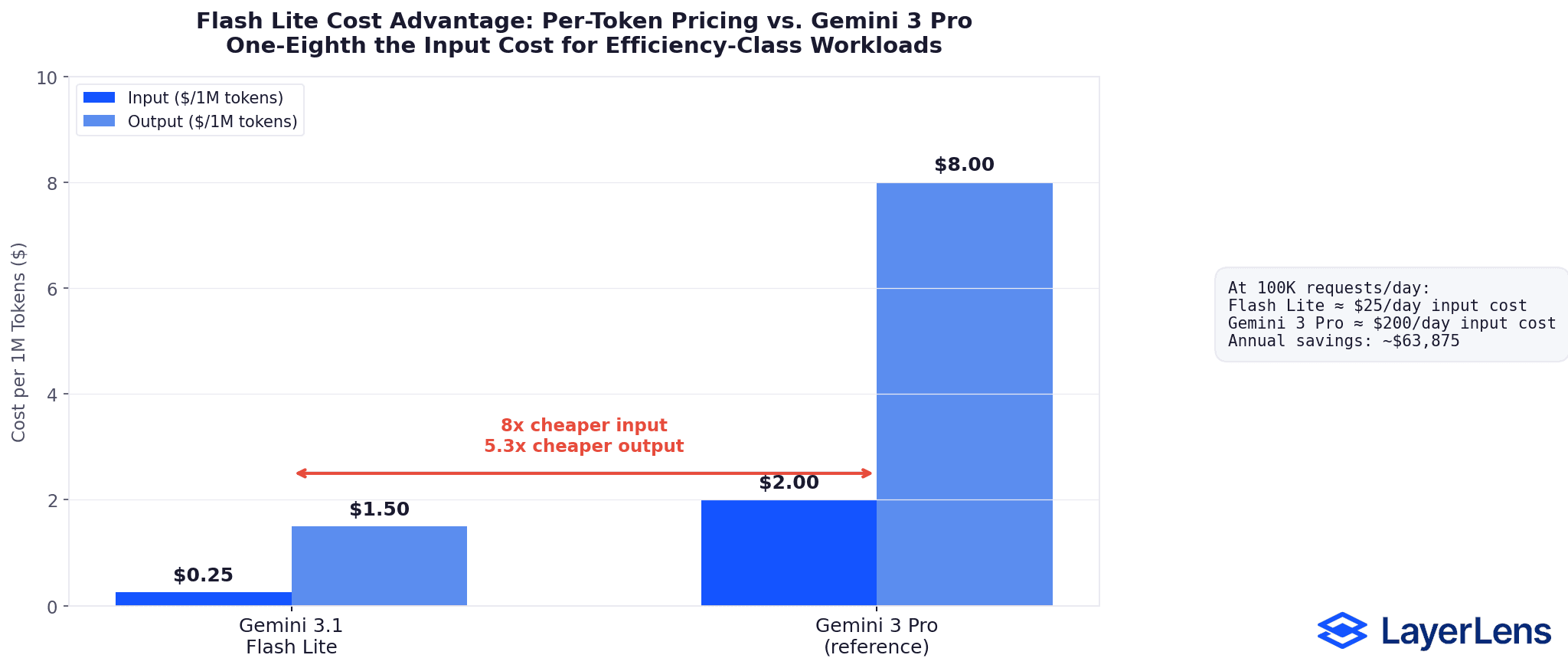
The question isn't whether it's cheap. It's whether cheap comes with tradeoffs that matter for your specific workload.
How We Evaluated Flash Lite
We evaluated Gemini 3.1 Flash Lite Preview on Stratix across 12 benchmarks spanning reasoning, coding, math, knowledge, and instruction following. Every evaluation ran under identical conditions: same benchmark versions, same scoring criteria, same infrastructure.
This matters because benchmark results without controlled conditions are noise. A model scoring 85% on one lab's version of MMLU Pro and 80% on another's tells you nothing about the model. It tells you the labs used different evaluation setups. Stratix eliminates that variable.
Full Benchmark Results
MMLU Pro: 2,000 items evaluated, 83.0% accuracy, 1.38s avg latency
BigBench-Hard: 6,511 items, 87.7% accuracy
MATH-500: 500 items, 85.6% accuracy
BFCL v3 (function calling): 4,441 items, 76.5% accuracy
AGIEval English: 2,546 items, 76.8% accuracy
MMMU (multimodal): 900 items, 73.7% accuracy
GPQA Diamond: 198 items, 72.2% accuracy
LiveCodeBench: 1,055 items, 69.9% accuracy
AIME 2025 (competition math): 30 items, 16.7% accuracy
HLE (hard language): 2,700 items, 8.5% accuracy
Terminal-Bench: 80 items, 17.5% accuracy
Terminal-Bench Terminus-1: 80 items, 17.5% accuracy
Total items evaluated: 21,041
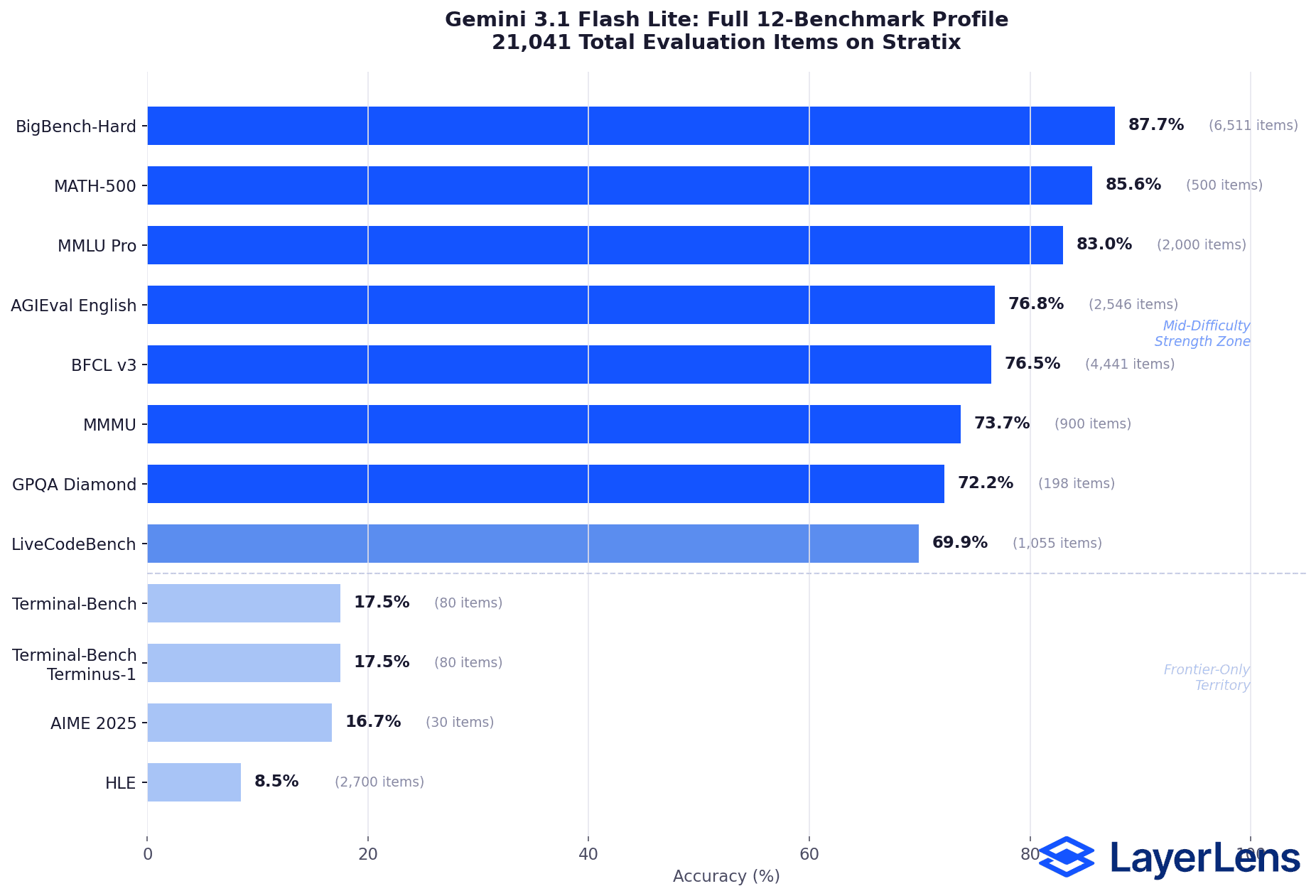
Flash Lite's strength is clear in the mid-difficulty range. 87.7% on BigBench-Hard and 85.6% on MATH-500 place Flash Lite within 5 points of several frontier models on these benchmarks, at one-eighth the cost. On MMLU Pro (2,000 items), 83.0% places it firmly in the high-accuracy tier for efficiency-class models.
The ceiling shows on harder benchmarks. 16.7% on AIME 2025 (competition-level math) and 8.5% on HLE indicate that Flash Lite is not designed to compete with frontier reasoning models on the hardest problems. That's expected. Google positioned it as an efficiency model, not a reasoning model, and the data confirms that positioning.
72.2% on GPQA Diamond (expert-level science questions) and 69.9% on LiveCodeBench fall within the expected range for efficiency-class models on these benchmarks. Function calling at 76.5% on BFCL v3 exceeds the typical 70% viability threshold for production agent workflows that need reliable tool use.
View all Flash Lite benchmark results in Stratix
The Efficiency-Class Comparison: Flash Lite vs. Its Actual Weight Class
Model comparisons are only useful when you're comparing the right things. Evaluating Flash Lite against Claude Opus 4.6 or GPT-5.2 tells you nothing actionable. Those are frontier models at 10 to 40 times the cost.
The real question: how does Flash Lite perform against models that compete for the same workloads? High-volume inference. Cost-sensitive pipelines. Applications where per-request latency and per-token cost are the primary constraints.
We ran head-to-head comparisons on MMLU Pro in Stratix against every efficiency-class model in our catalog. Same benchmark, same scoring, same infrastructure.
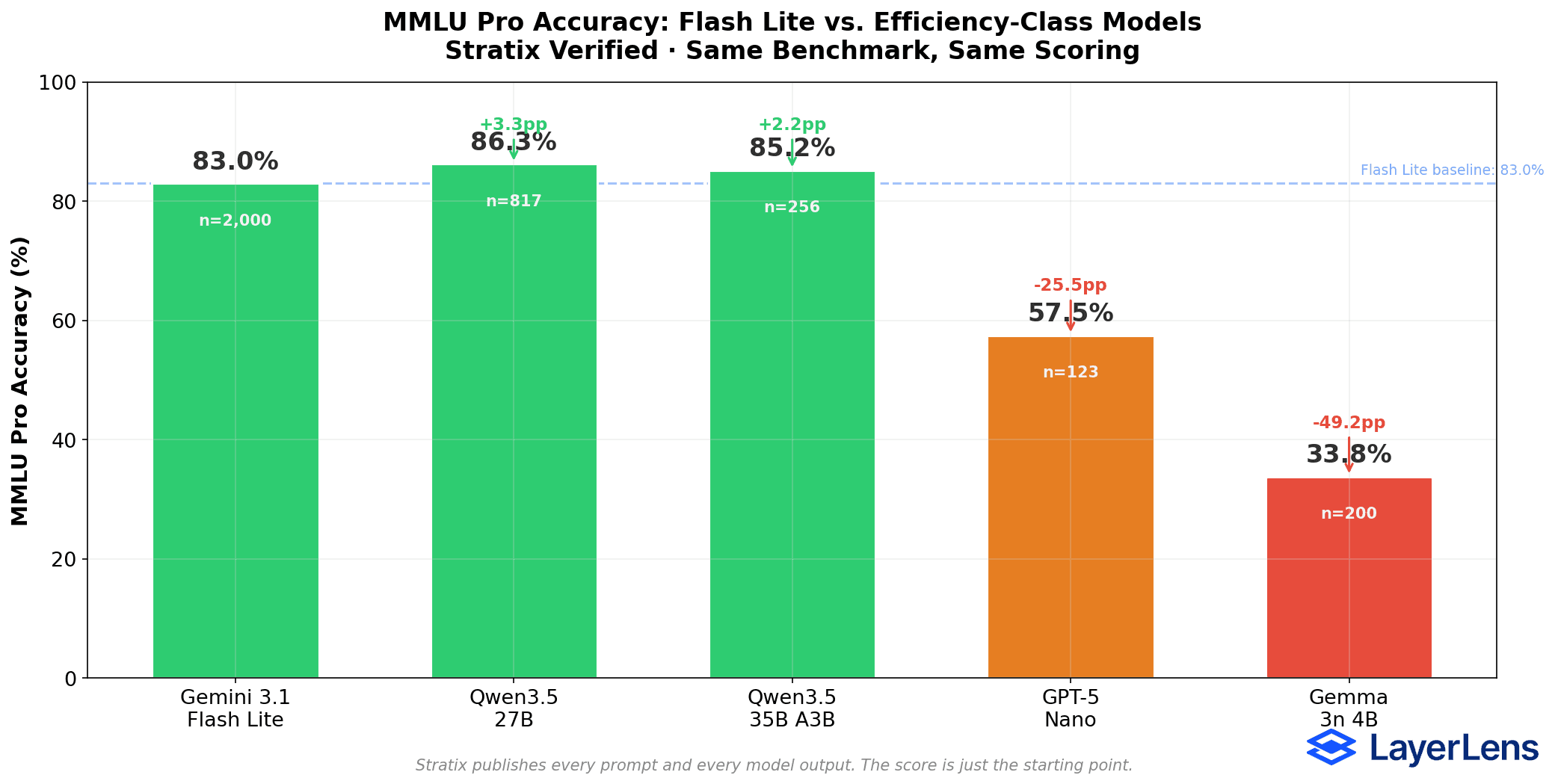
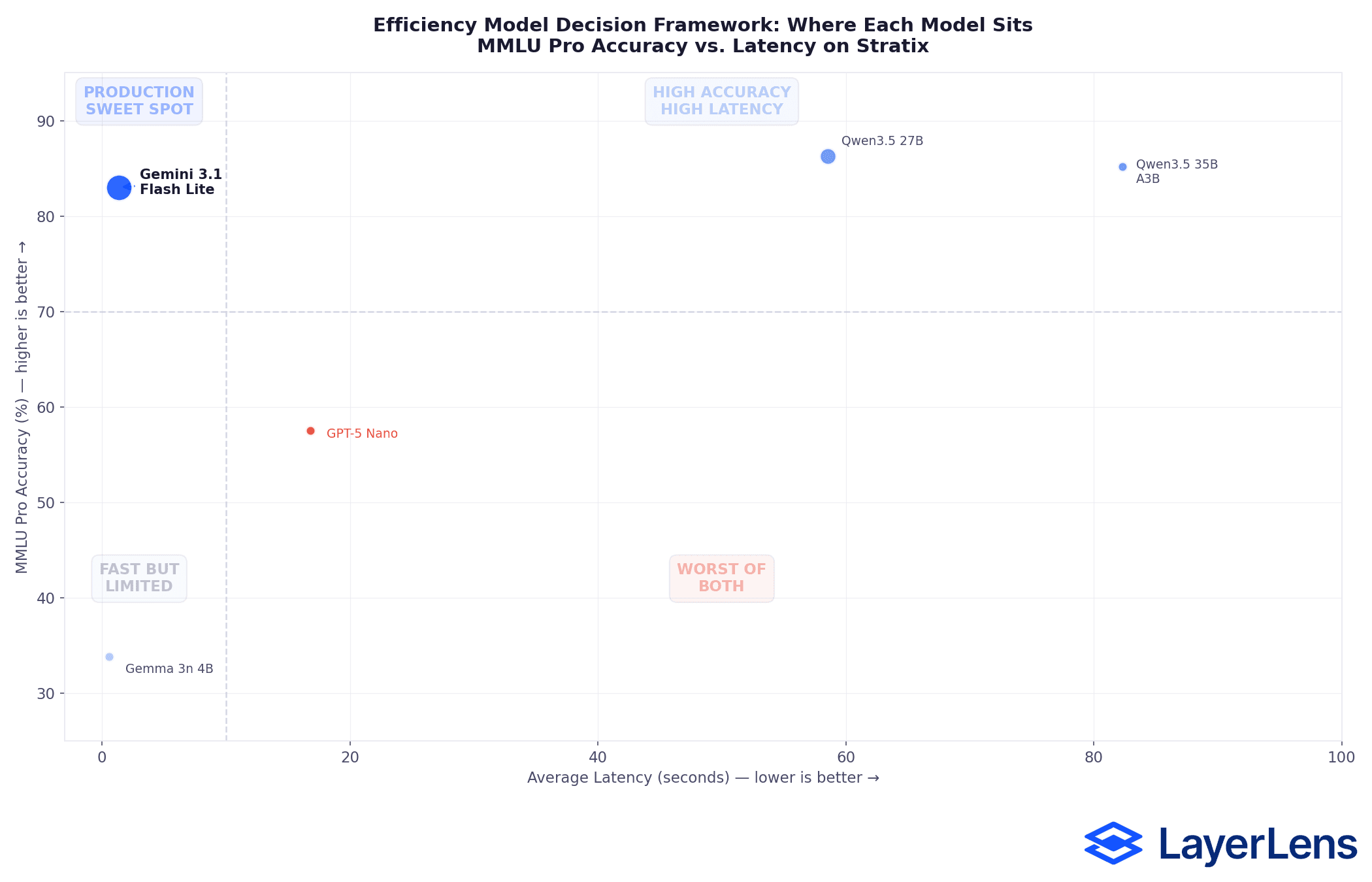
MMLU Pro Head-to-Head Results
Gemini 3.1 Flash Lite: 83.0% accuracy, 1.38s avg latency, 2,000 items
Qwen3.5 27B: 86.3% accuracy, 58.57s avg latency, 817 items
Qwen3.5 35B A3B (MoE, 3B active): 85.2% accuracy, 82.33s avg latency, 256 items
GPT-5 Nano: 57.5% accuracy, 16.79s avg latency, 123 items
Gemma 3n 4B: 33.8% accuracy, 0.58s avg latency, 200 items
All results verified on Stratix under identical benchmark conditions. Sample sizes differ between models.
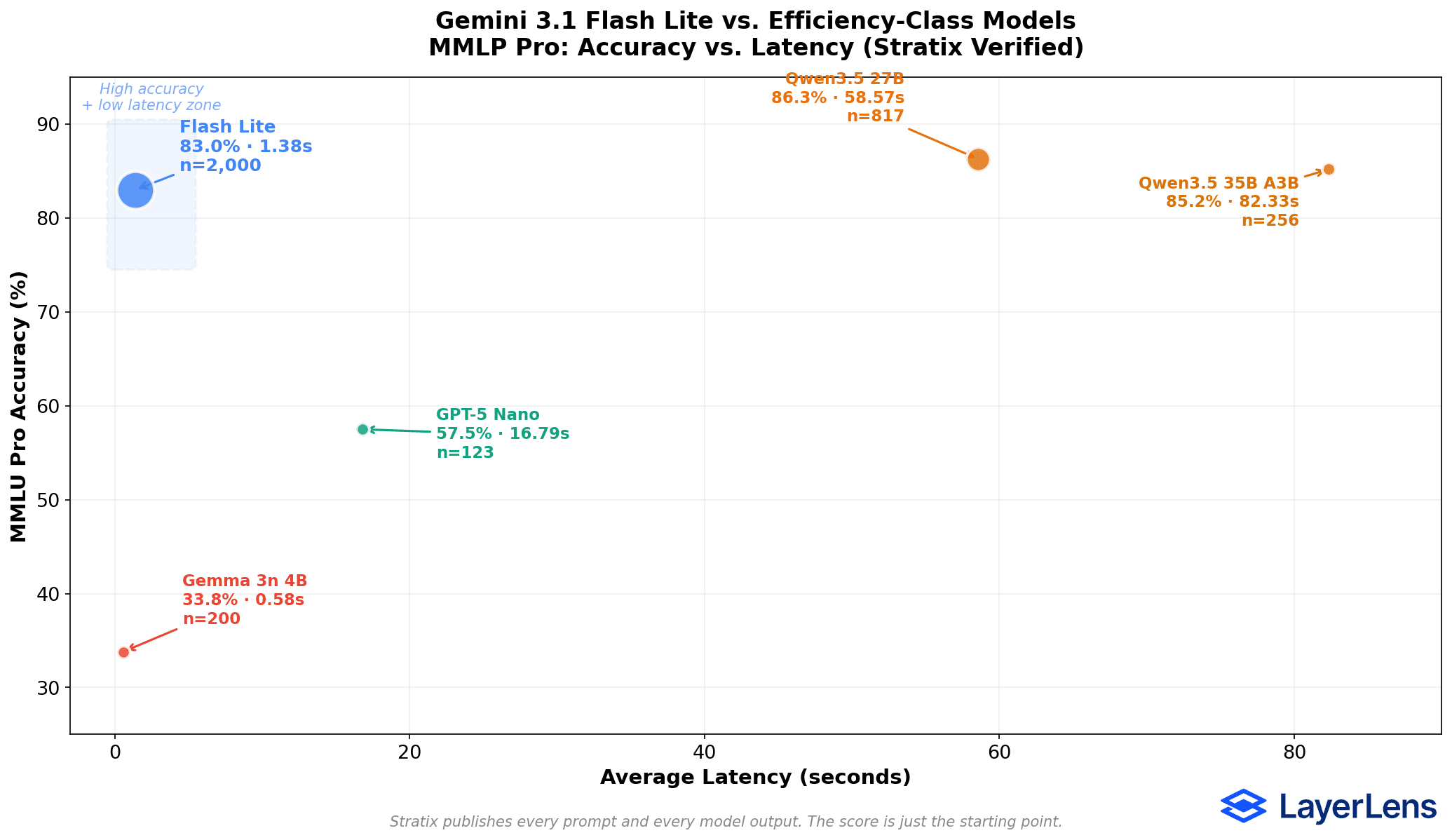
Three Patterns in the Data
1. Flash Lite occupies a distinct position on the speed-accuracy curve.
The Qwen3.5 models beat Flash Lite on raw accuracy. Qwen3.5 27B is 42x slower than Flash Lite (86.3% vs. 83.0% accuracy, 58.57s vs. 1.38s latency). Qwen3.5 35B A3B is 60x slower (85.2% vs. 83.0%, 82.33s vs. 1.38s).
For a single academic benchmark run, that latency difference is irrelevant. For a production pipeline processing thousands of requests per hour, it changes the economics entirely.
2. GPT-5 Nano, OpenAI's efficiency competitor, trails significantly.
GPT-5 Nano scores 57.5% on MMLU Pro with 16.79s average latency. That's 25.5 percentage points below Flash Lite while running 12x slower. The sample size caveat applies (123 items vs. 2,000), but the gap is wide enough that additional evaluation items are unlikely to close it.
For teams choosing between Google and OpenAI's efficiency tiers, the 25.5 percentage point difference on MMLU Pro directly impacts production feasibility: Flash Lite crosses the 80% accuracy threshold while GPT-5 Nano does not.
3. On-device models operate in a different category entirely.
Gemma 3n 4B scores 33.8% on MMLU Pro at 0.58 seconds. It's faster than Flash Lite, and it shows. 33.8% accuracy on a general knowledge benchmark limits use cases to narrow, pre-defined tasks where the model handles a constrained set of inputs. This is on-device territory, not API territory.
The Speed-Accuracy Tradeoff: What the Numbers Actually Mean
The efficiency-class model market is not a single race. It's a map with multiple viable positions, and each position serves different workloads.
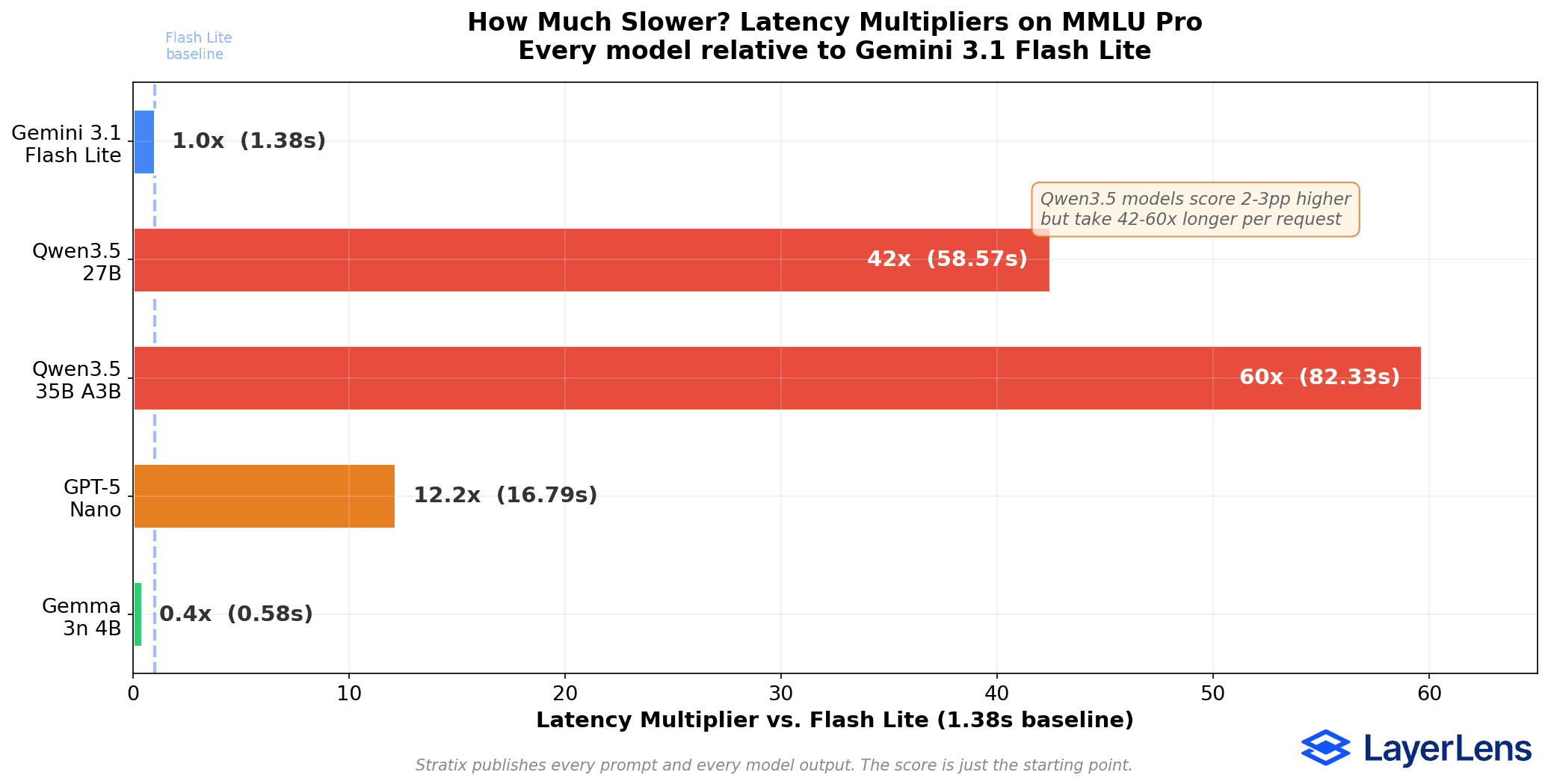
Latency Multipliers vs. Flash Lite (1.38s baseline)
Gemma 3n 4B: 0.4x (faster), 0.58s
Gemini 3.1 Flash Lite: 1.0x (baseline), 1.38s
GPT-5 Nano: 12.2x slower, 16.79s
Qwen3.5 27B: 42.4x slower, 58.57s
Qwen3.5 35B A3B: 59.7x slower, 82.33s
For teams evaluating efficiency-class models, the decision framework looks like this:
If accuracy is the only metric that matters and latency is irrelevant, Qwen3.5 27B offers the highest score at 86.3%. But latency is rarely irrelevant in production.
If you need high accuracy at production-viable latency, Flash Lite is the only model above 80% accuracy with sub-2-second response times.
If per-request latency is the primary constraint, Gemma 3n 4B at 0.58 seconds is the fastest option. But 33.8% accuracy limits viable use cases.
If you're evaluating OpenAI's efficiency tier specifically, GPT-5 Nano's 57.5% on MMLU Pro at 16.79s latency positions it well below Flash Lite on both axes.
Sample Size Transparency
Different models have different evaluation depths in our catalog, and we believe in being upfront about what that means for statistical confidence.
Flash Lite was evaluated on 2,000 MMLU Pro items. At that sample size, the 95% confidence interval is approximately +/- 1.6 percentage points. Qwen3.5 27B was evaluated on 817 items (CI: +/- 2.4pp). GPT-5 Nano was evaluated on 123 items (CI: +/- 8.8pp).
The Flash Lite vs. Qwen accuracy difference (3.3 percentage points) is close enough that it could narrow with additional evaluation data. The Flash Lite vs. GPT-5 Nano difference (25.5 percentage points) is large enough to be robust even with the smaller sample.
We report sample sizes because the industry standard of citing a single accuracy number without context does readers a disservice. A score based on 2,000 items and a score based on 123 items carry different levels of statistical weight.
Where Flash Lite Fits in the Broader Model Landscape
Flash Lite is not a frontier model. It does not compete with Claude Opus 4.6, GPT-5.2, or Gemini 3 Pro on reasoning, creativity, or complex multi-step problem solving. Its benchmark results on the hardest evaluations (16.7% on AIME 2025, 8.5% on HLE) confirm this.
What Flash Lite does is occupy a specific position on the speed-accuracy curve: above 80% on MMLU Pro at sub-2-second latency. For production workloads that need general knowledge, function calling, classification, or content generation at scale, that combination of accuracy and speed is worth evaluating against your specific requirements.
The harder question is whether that position holds over time. Model behavior shifts between versions, between providers, between updates. The numbers in this article reflect Flash Lite in preview. Google's production release may perform differently.
This is where intelligent evaluation infrastructure matters. Benchmarks are the foundation. They tell you where a model stands on standardized tasks under controlled conditions. But benchmarks alone don't tell you how a model performs on your customer support tickets, your compliance workflows, or your agent pipelines. The evaluation layer needs to generate the right tests for your use case, judge results with AI-powered scoring that calibrates against your standards, and re-evaluate when providers push updates.
Scale and Cost Implications
For teams operating at scale, the latency difference is an infrastructure constraint, not an optimization detail. A 60x latency multiplier at 100,000 daily requests moves from manageable to significant compute overhead. The cost-per-token advantage compounds similarly: at one-eighth the price of Gemini 3 Pro, Flash Lite reduces inference costs for high-volume classification, content generation, and retrieval-augmented pipelines where per-request margins are thin.
The tradeoff calculus changes at enterprise volume. Running Qwen3.5 27B at 58.57 seconds per request across 100K daily calls requires fundamentally different infrastructure than Flash Lite at 1.38 seconds. Whether the 3.3-point accuracy gap justifies that infrastructure investment depends on your error tolerance, your SLA requirements, and what downstream decisions depend on model outputs.
Frequently Asked Questions About Gemini 3.1 Flash Lite
Q: When was Gemini 3.1 Flash Lite released?
A: Google released Gemini 3.1 Flash Lite Preview on March 3, 2026. It is available in Google AI Studio and Vertex AI.
Q: What is the pricing for Gemini 3.1 Flash Lite?
A: $0.25 per million input tokens and $1.50 per million output tokens. This makes it one-eighth the cost of Gemini 3 Pro.
Q: What is Flash Lite's context window?
A: 1 million tokens, supporting text, image, speech, and video inputs.
Q: How fast is Gemini 3.1 Flash Lite?
A: Average latency is 1.38 seconds on MMLU Pro (2,000 items). Output speed is approximately 362 tokens per second per Artificial Analysis.
Q: How accurate is Flash Lite on benchmarks?
A: Flash Lite scores 83.0% on MMLU Pro, 87.7% on BigBench-Hard, 85.6% on MATH-500, and 76.5% on BFCL v3 (function calling). See the full benchmark table above for all 12 results.
Q: How does Flash Lite compare to GPT-5 Nano?
A: On MMLU Pro, Flash Lite scores 83.0% vs. GPT-5 Nano's 57.5%, a 25.5 percentage point difference. Flash Lite is also 12x faster (1.38s vs. 16.79s latency).
Q: How does Flash Lite compare to Qwen3.5 models?
A: Qwen3.5 27B scores 3.3 percentage points higher (86.3% vs. 83.0%) but runs 42x slower (58.57s vs. 1.38s). Qwen3.5 35B A3B scores 2.2 points higher but runs 60x slower.
Q: Is Flash Lite good for production workloads?
A: At 1.38s latency with 83% accuracy on general knowledge tasks, Flash Lite is viable for high-volume production pipelines including classification, content generation, and retrieval-augmented workflows. The preview status means Google may optimize further before general availability.
Q: What does Flash Lite struggle with?
A: Hard reasoning benchmarks: 16.7% on AIME 2025 (competition math) and 8.5% on HLE (hard language). Flash Lite is designed for efficiency, not frontier reasoning.
Q: What does "adjustable thinking levels" mean?
A: Developers can tune the tradeoff between reasoning depth and inference speed, optimizing for their specific use case. This allows cost-accuracy optimization at the request level.
Q: How does Flash Lite fit in Google's model lineup?
A: It is the efficiency tier. Gemini 3 Pro is the general-purpose frontier model; Gemini 3.1 Flash Lite is optimized for cost-sensitive, high-volume workloads at one-eighth the price.
Q: Where can I see the full evaluation data?
A: All results are available with prompt-level transparency on Stratix Public by LayerLens. You can inspect every input, output, and scoring decision.
Methodology
All evaluations were conducted on Stratix by LayerLens. Stratix is intelligent evaluation infrastructure for AI that provides independent, cross-vendor model comparison with prompt-level transparency. It generates tests, judges results with AI-powered scoring, and works across ecosystems.
Evaluation conditions:
All models evaluated under identical benchmark conditions on MMLU Pro
Automated scoring with deterministic evaluation criteria
Full prompt and output transparency for every evaluation item
No cherry-picking: all items in each benchmark run are included in aggregate scores
Latency measured as wall-clock time per request including model inference and API overhead
Reproducibility:
Every evaluation result referenced in this article can be inspected at the prompt level in Stratix Public. You can see the exact input, model output, expected answer, and scoring logic for every single item.
View Flash Lite evaluation results | Run your own comparisons
Key Takeaways
Gemini 3.1 Flash Lite is Google's play for the high-volume, cost-sensitive tier of the API market. At $0.25 per million input tokens with 1M token context and adjustable thinking levels, the positioning is clear.
The evaluation data maps clear tradeoffs: Flash Lite delivers 83.0% accuracy on MMLU Pro at 1.38 seconds. The two models that outscore it in this weight class take 42 to 60 times longer. OpenAI's efficiency-tier entry scores 57.5%. Each model makes a different bet on the speed-accuracy curve.
For teams selecting an efficiency-class model for production workloads, the tradeoff isn't accuracy vs. cost. It's where your workload falls on the speed-accuracy curve, whether that position matches your requirements, and whether it holds as the model evolves. Public benchmarks give you the foundation. Evaluating on your own data, with your own scoring criteria, gives you the answer.
Benchmark the models that matter for your use case. Start a free evaluation in Stratix.
All evaluation data in this article is independently generated by LayerLens on Stratix. LayerLens has no commercial relationship with Google, OpenAI, Alibaba, or Meta. We evaluate every provider under identical conditions because cross-vendor neutrality is how intelligent evaluation infrastructure should work.
Want to go beyond public benchmarks? Stratix Premium lets you upload your own datasets, define scoring criteria in plain English with Natural Language Judges, and run private evaluations that answer questions specific to your business.