
Partner Evaluation Spaces: Benchmark Models on Fireworks AI and Nebius Infrastructure
Author:
The LayerLens Team
Last updated:
Published:
Author Bio
Jake Meany is a digital marketing leader who has built and scaled marketing programs across B2B, Web3, and emerging tech. He holds an M.S. in Digital Social Media from USC Annenberg and leads marketing at LayerLens.
TL;DR
LayerLens Stratix now supports dedicated partner evaluation spaces for inference providers, starting with Fireworks AI and Nebius.
Each partner space benchmarks models as they are actually served on the provider's infrastructure, preserving provider-specific performance characteristics that aggregated views hide.
Fireworks currently tracks 11 models across 8 benchmarks (88 evaluations). Nebius tracks 25 models across the same 8 benchmarks (200 evaluations).
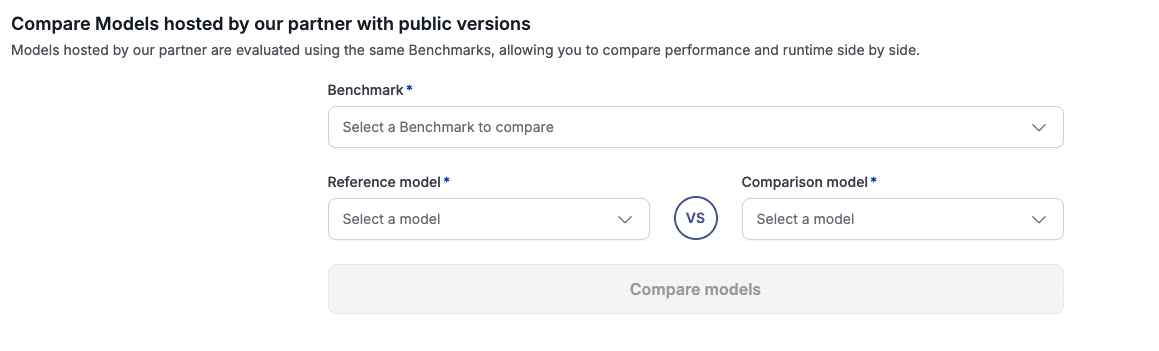
A built-in comparison tool lets you evaluate partner-hosted model versions against public versions of the same model, same benchmark, side by side (accuracy and runtime).
Stratix Premium users can now select Fireworks or Nebius as providers when running individual evaluations, matching their eval environment to their production stack.
Introduction
Evaluation Spaces on LayerLens Stratix are dashboards built to do one thing well: give you a structured way to compare models on public benchmarks, sliced by region, vendor, or size and specialty. Until now, the infrastructure behind all of those evaluations ran exclusively through a single default provider. That changes today.
We are introducing dedicated partner evaluation spaces for inference providers, starting with Fireworks AI and Nebius. Each provider now has its own Space on Stratix, meaning you can browse and compare the full catalog of open-source models each provider supports, with benchmark analytics scoped to that specific provider rather than collapsed into a single aggregated view.
This post explains what partner evaluation spaces are, what data they contain, and why the distinction between a provider-scoped Space and an aggregated default view matters for teams making deployment decisions.
What Are Partner Evaluation Spaces?
A partner evaluation space is a dedicated section on Stratix where every model hosted by a specific inference provider is independently benchmarked by LayerLens. The models run on the provider's actual infrastructure, not in a sandbox or simulated environment. The benchmarks, prompts, and scoring methodology are the same ones LayerLens applies across all 200+ models on Stratix.
Each partner space includes three layers of data:
Benchmark scores for every model on the provider's infrastructure. A full performance table showing accuracy across all benchmarks, color-coded by relative performance within each benchmark. Green indicates top performance within that benchmark, even if absolute scores differ across columns.
Latency data per model, per benchmark. Every evaluation tracks not just accuracy but runtime. You can see which models are fastest on each benchmark as served on the provider's infrastructure, measured in milliseconds.
A comparison tool for partner-hosted vs. public model versions. Select a benchmark, pick a reference model, and compare it against another model (or the public version of the same model). Performance and runtime, side by side.
That third piece is where the real utility lives. If you want to know whether DeepSeek V3.2 on Fireworks performs the same as the public version, whether it is faster or slower, whether accuracy shifts at all, you can check it directly.
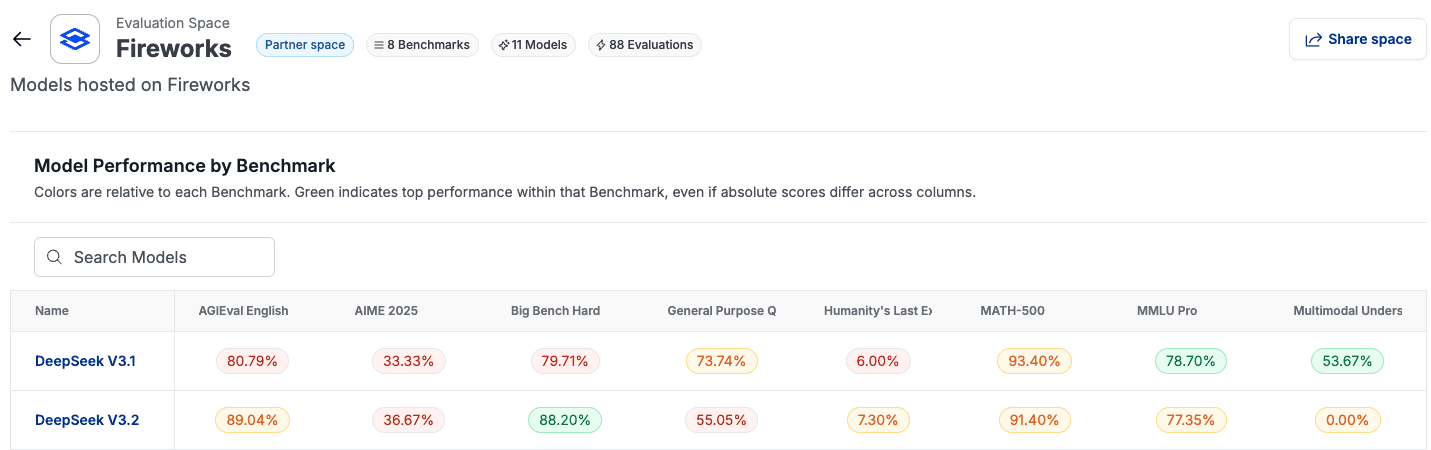
Fireworks AI: 11 Models, 8 Benchmarks
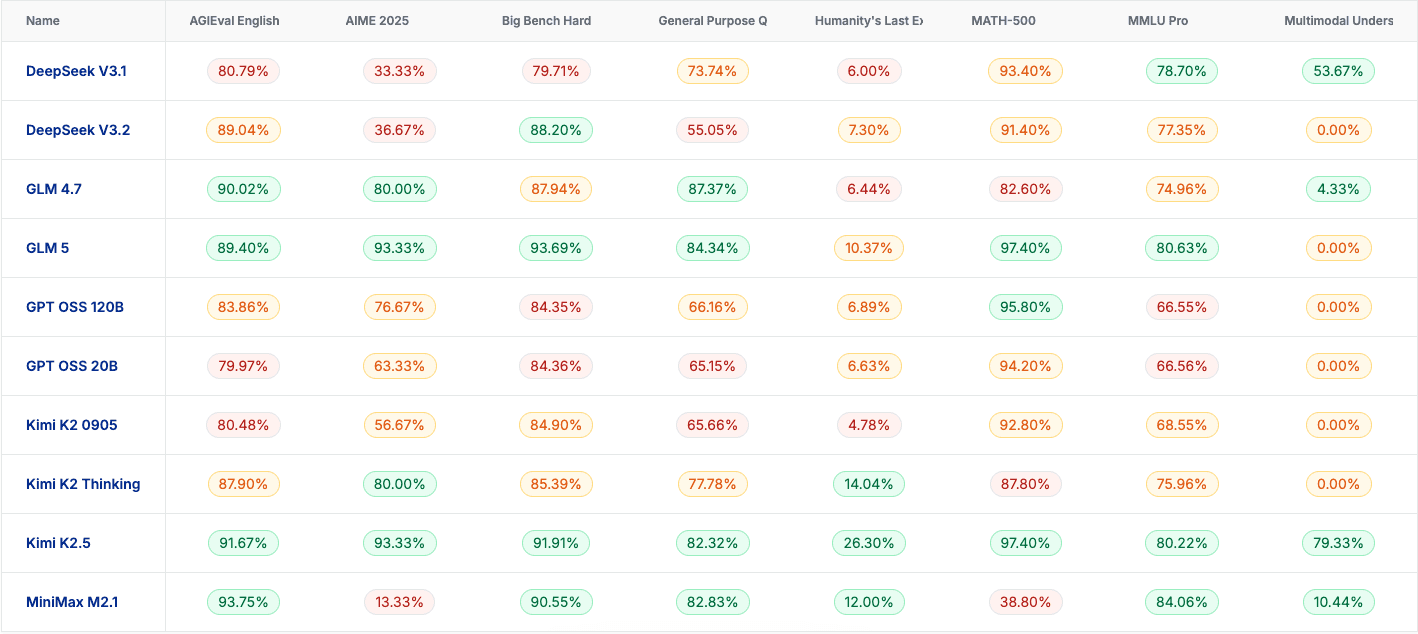
The Fireworks evaluation space currently tracks 11 models across 8 benchmarks, totaling 88 individual evaluations. The model lineup includes DeepSeek V3.1, DeepSeek V3.2, GLM 4.7, GLM 5, GPT OSS 120B, GPT OSS 20B, Kimi K2 0905, Kimi K2 Thinking, Kimi K2.5, MiniMax M2.1, and MiniMax M2.5.
On AGIEval English (one of the 8 benchmarks), the accuracy spread runs from MiniMax M2.1 at 93.75% down to GPT OSS 20B at 79.97%. On the latency side, DeepSeek V3.1 is the fastest at 6,212ms, while Kimi K2 Thinking is the slowest at 390,762ms on the same benchmark. That is a 63x difference in response time between the fastest and slowest model on a single benchmark, all on the same provider's infrastructure.
The benchmarks covered include AGIEval English, AIME 2025, Big Bench Hard, General Purpose QA, Humanity's Last Exam, MATH-500, MMLU Pro, and Multimodal Understanding.
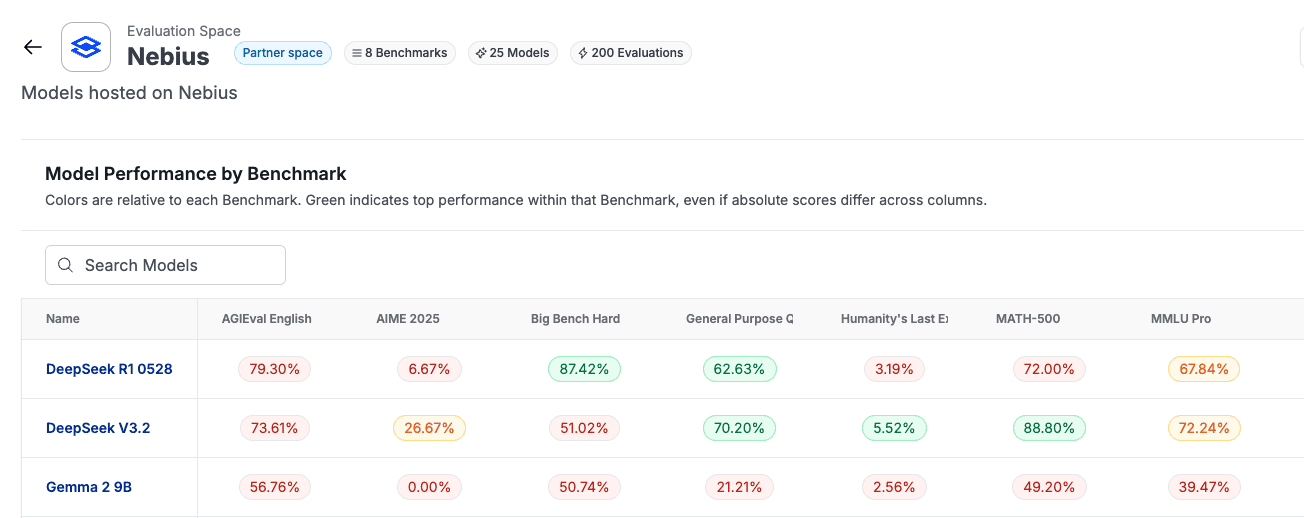
Nebius: 25 Models, 8 Benchmarks
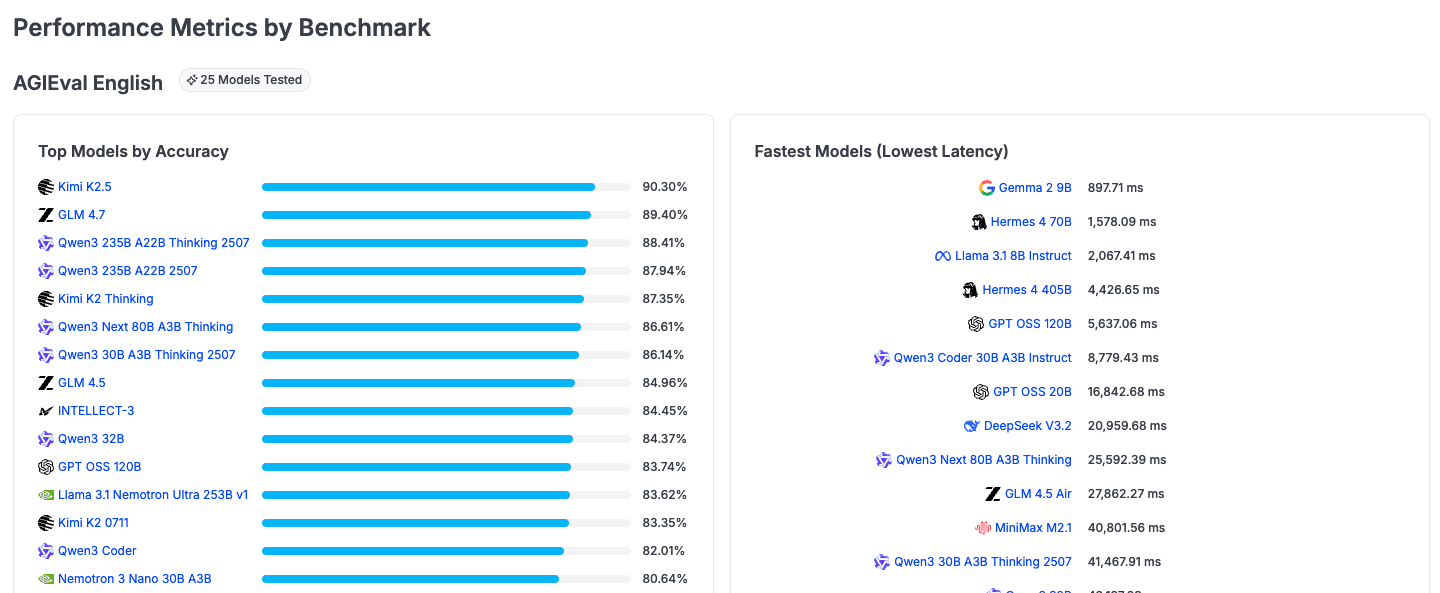
The Nebius evaluation space is broader, tracking 25 models across the same 8 benchmarks for a total of 200 evaluations. The model catalog includes DeepSeek R1 0528, DeepSeek V3.2, Gemma 2 9B, GLM 4.5, GLM 4.5 Air, GLM 4.7, Hermes 4 70B, Hermes 4 405B, INTELLECT-3, Kimi K2 0711, Kimi K2.5, Llama 3.1 8B Instruct, Llama 3.1 Nemotron Ultra 253B v1, MiniMax M2.1, Nemotron 3 Nano 30B A3B, GPT OSS 120B, GPT OSS 20B, Qwen3 32B, Qwen3 235B A22B 2507, Qwen3 235B A22B Thinking 2507, Qwen3 30B A3B Thinking 2507, Qwen3 Coder, Qwen3 Coder 30B A3B Instruct, and Qwen3 Next 80B A3B Thinking.
Nebius shows a wider performance and latency spread because it hosts a broader range of model sizes and architectures. On AGIEval English, accuracy runs from Kimi K2.5 at 90.30% down to smaller models in the 50-60% range. The latency range is even more striking: Gemma 2 9B responds in 897ms, while GLM 4.7 takes 54,095ms. Having a 9B parameter model available alongside 405B parameter models on the same infrastructure gives teams a real option set for cost-performance tradeoffs.
Why Provider-Scoped Evaluation Matters
The distinction between a provider Space and an aggregated default provider view is not cosmetic. The default provider view on Stratix is useful precisely because it abstracts over providers. It gives you the broadest model surface area and the simplest comparison. But that abstraction means you lose visibility into provider-specific performance characteristics.
A dedicated Fireworks Space or Nebius Space preserves that signal. You are evaluating models as they are actually served on that provider's stack, not as they exist in the abstract. Two copies of the same open-source model, served by different providers, can produce different latency profiles and, in some cases, different accuracy results depending on quantization, serving framework, and infrastructure configuration.
For teams whose production stack runs on Fireworks or Nebius, this means your evaluation environment can now match your deployment environment. That is not a minor detail. Evaluation data collected on one provider's infrastructure and applied to deployment decisions on another provider's infrastructure introduces a gap that is easy to overlook and hard to quantify after the fact. For procurement teams signing annual inference contracts, this gap means approval decisions based on performance data that may not reflect production conditions.
Running Evaluations Through Partner Providers
For Stratix Premium users, Fireworks and Nebius are now available as selectable providers when running individual evaluations. Instead of routing all evaluations through the default provider backend, you can choose to run your evaluation through Fireworks or Nebius directly.
This matters in two scenarios. First, when you are doing cost and quality comparisons across providers serving the same underlying model. If you want to know whether DeepSeek V3.2 performs differently on Fireworks than on Nebius, you can now run the same benchmark on both and compare. Second, when your production stack already runs on one of these providers and you want your evaluation data to reflect production conditions rather than a neutral third-party environment.
What Comes Next
The default provider is not going anywhere. It remains the default and covers the widest model catalog on Stratix. Fireworks and Nebius are the first entries in what will be an expanding set of partner Spaces. Additional providers will be onboarded as the program grows.
Each new partner Space follows the same structure: full model catalog, benchmark scores, latency data, and the comparison tool for partner-hosted vs. public model versions. The goal is to give teams a provider-aware evaluation layer that sits between benchmark data and deployment decisions.
Key Takeaways
Partner evaluation spaces give inference providers dedicated, independently benchmarked Spaces on Stratix where models are tested on the provider's actual infrastructure.
Fireworks AI (11 models, 88 evaluations) and Nebius (25 models, 200 evaluations) are the first two partner spaces, with more providers coming.
Latency data is tracked per model, per benchmark, on the provider's infrastructure. On Fireworks, the gap between fastest and slowest model on AGIEval English is 63x. On Nebius, Gemma 2 9B responds in under 900ms.
The built-in comparison tool lets you check a partner-hosted model against its public version on the same benchmark, covering both accuracy and runtime.
Stratix Premium users can now select Fireworks or Nebius as evaluation providers, matching their eval environment to their production stack.
Frequently Asked Questions
What are partner evaluation spaces on LayerLens Stratix?
Partner evaluation spaces are dedicated sections on Stratix where every model hosted by a specific inference provider is independently benchmarked by LayerLens, using the same methodology applied across all 200+ models on the platform.
Which providers have partner evaluation spaces?
Fireworks AI and Nebius are the first two providers with dedicated evaluation spaces. Additional providers will be onboarded as the program expands.
How many models are tracked in each partner space?
The Fireworks space tracks 11 models across 8 benchmarks (88 evaluations). The Nebius space tracks 25 models across 8 benchmarks (200 evaluations).
What benchmarks are used in partner evaluation spaces?
Both spaces use the same 8 benchmarks: AGIEval English, AIME 2025, Big Bench Hard, General Purpose QA, Humanity's Last Exam, MATH-500, MMLU Pro, and Multimodal Understanding.
Can I compare a partner-hosted model against the public version?
Yes. Each partner space includes a comparison tool where you select a benchmark, a reference model, and a comparison model. You can compare accuracy and runtime between a model hosted by the partner and any other model, including the public version.
Do partner spaces track latency in addition to accuracy?
Yes. Every evaluation tracks both accuracy and runtime (latency in milliseconds). Each benchmark section shows "Top Models by Accuracy" and "Fastest Models (Lowest Latency)" side by side.
Methodology
All evaluations in partner spaces were conducted on LayerLens Stratix using standardized benchmark configurations. Models are evaluated as served on the partner's infrastructure, using the same prompts, scoring rubrics, and test cases applied across all models on Stratix. Benchmark results reflect the model's performance on the provider's actual serving stack.
Full evaluation data for both partner spaces is available on Stratix. You can explore the Fireworks evaluation space at app.layerlens.ai/evaluation-space/fireworks and the Nebius evaluation space at app.layerlens.ai/evaluation-space/nebius. Stratix Premium users can run their own evaluations through Fireworks or Nebius directly from the evaluation interface.