Jun 3, 2025
When comes to frontier models, leaderboards have become the de facto metric for progress. Systems like Chatbot Arena—designed to crowdsource comparative evaluations—offer a seemingly objective lens through which model performance is judged. But recent scrutiny, led by the paper "The Leaderboard Illusion," suggests these leaderboards may obscure more than they reveal. The research, complemented by TheSequence's in-depth analysis, lays bare the systemic imbalances embedded in current benchmarking practices, questioning the neutrality and representativeness of widely trusted evaluation protocols.
Challenging the Arena: Three Critical Fault Lines
Private Submissions and Strategic RetractionsOne of the most serious claims made in the paper is the extent to which elite model providers—Meta, OpenAI, Google, and Amazon—exploit the submission mechanics of Chatbot Arena. For instance, Meta privately tested 27 variants before releasing Llama 4. The authors argue that this practice enables cherry-picking: only models with favorable win rates are publicly released, while underperforming variants are quietly discarded. This creates a distorted leaderboard that rewards selectivity rather than capability. The result is not a reflection of general model quality, but of strategic positioning.
Sampling Bias and Visibility LoopsChatbot Arena's sampling mechanism is tuned to optimize user experience by favoring models with higher historical win rates. While intuitive, this design introduces a dangerous feedback loop: high-performing models receive more pairings and exposure, reinforcing their lead. Conversely, newer or open-weight models are under-sampled, limiting their chances to improve visibility. According to the paper, proprietary models from Google and OpenAI received 20% of all test prompts each, while 83 open-weight models collectively saw just under 30%. Such imbalance inhibits meaningful evaluation across the full model landscape.
Silent Deprecations and Opaque ParticipationOf the 243 public models previously listed on Chatbot Arena, 205 were deprecated—many without public disclosure. Notably, 64% of these were open-weight or fully open-source models. TheSequence highlights how this deprecation pipeline disproportionately affects non-corporate contributors, further compounding structural disadvantages. Silent deprecation prevents longitudinal analysis and community scrutiny, allowing the leaderboard to become increasingly curated and less representative.
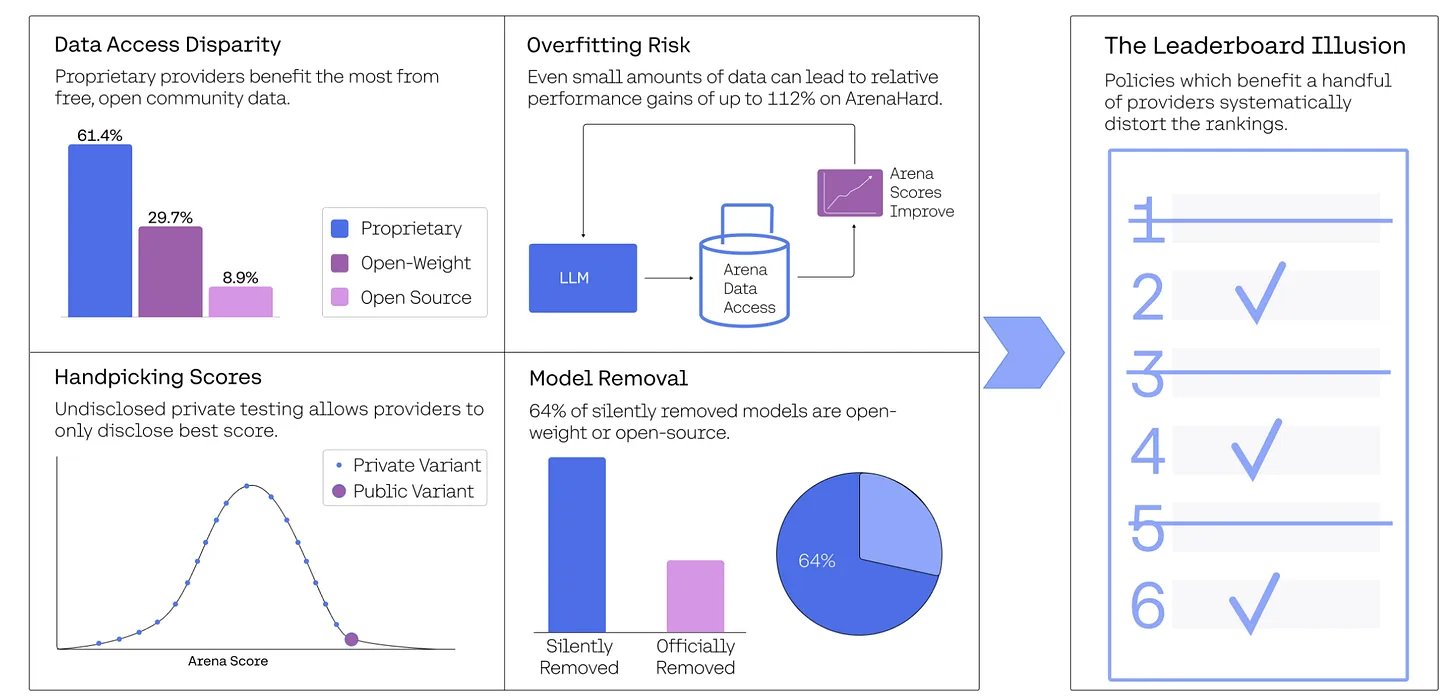
Image Credit: https://arxiv.org/abs/2504.20879
LMArena’s Defense: Practicality over Purity?
In response, LMArena offered a principled but pragmatic rebuttal. They argue that:
All developers are equally free to submit multiple model variants;
Sampling policies are a user-centric necessity to maintain quality interactions;
Transparency is served through the publication of final scores and open data.
Yet, TheSequence notes that these defenses, while operationally valid, sidestep the deeper issue: benchmarking systems designed without enforcement of submission parity and testing audit trails will naturally tilt in favor of those with more resources and tighter deployment cycles. In short, procedural openness is not synonymous with fairness.
The Goodhartian Trap: When Metrics Become Targets
"The Leaderboard Illusion" is a textbook illustration of Goodhart’s Law: when a measure becomes a target, it ceases to be a good measure. Once leaderboard rank becomes the prize, model design, evaluation frequency, and release schedules are optimized not for general performance, but for Arena dominance. This shift subtly alters the incentive structure of model development, encouraging exploitation of benchmark design rather than pushing the boundaries of foundational capabilities.
Conclusion: Restoring Trust in Measurement
Leaderboards are essential but fragile tools. As LLM development accelerates, the importance of transparent, representative, and auditable evaluation increases. "The Leaderboard Illusion" reveals the quiet erosion of trust that occurs when benchmarking becomes a game, not a measure. If the AI community is to maintain credible standards of progress, it must recognize that benchmarking is not a neutral act—it is an architectural choice that shapes what models we build, release, and ultimately trust.
EXPLORE MORE ARTICLES
NEXT

