May 30, 2025

At LayerLens, we are obsessed with everything related to AI evaluations and last week we came across some work from @AIatMeta that might hint how the future of AI evals look like.
Meta AI J1 marks a breakthrough in how we think about language model evaluation. Traditionally, LLMs have excelled at generation but struggled to evaluate content—whether their own or others’—with consistency and clarity. J1 aims to change that by training models not just to generate, but to reason and judge. The result is a reinforcement learning–driven approach that yields generalist “judge” models, capable of high-quality, self-reflective assessments across a range of tasks.
From Scalar Scores to Chain-of-Thought Judgment
The inspiration behind J1 stems from a simple but powerful insight: evaluation should be a structured reasoning process, not just a scalar reward. Traditional reward models collapse evaluation into numeric scores, often obscuring the rationale behind judgments and introducing biases. J1 reframes evaluation as a full-fledged cognitive task by training models to produce detailed chain-of-thought (CoT) reasoning before arriving at a final verdict.
This is operationalized through Group Relative Policy Optimization (GRPO), a reinforcement learning technique that optimizes both the “thinking trace” and the final verdict. The J1 framework supports two key modes:
Pairwise-J1: Compares two candidate responses and decides which one is better, supported by multi-step internal reasoning.
Pointwise-J1: Scores a single response independently, trained via distant supervision derived from pairwise comparisons.
One of J1’s architectural strengths lies in its use of synthetic preference data. The team generated structured preference pairs using both mathematical (MATH) and conversational (WildChat) datasets. This approach removes dependence on human-annotated labels while covering both verifiable and subjective domains.
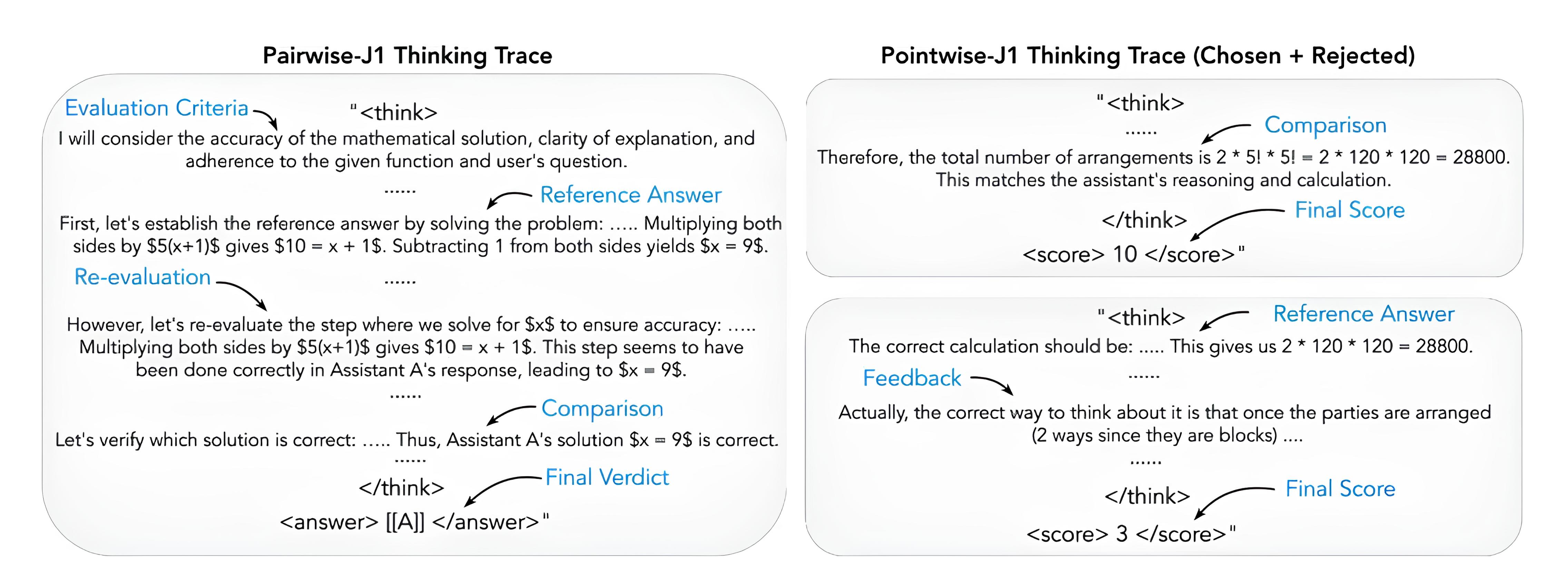
Image Credit: Meta AI
Designing a Judge that Thinks
Key to J1’s success is the integration of position-agnostic training and consistency-based rewards. Pairwise data is fed in both forward and reverse order, with the model penalized if its verdict changes based on response order. This directly addresses position bias—a known issue in comparative evaluations.
J1 also supports flexible prompting strategies. The simplest “Thinking” prompt encourages structured reasoning, while more elaborate formats like “Plan & Execute” guide the model through evaluation recipes before scoring. This flexibility improves robustness across tasks and domains.
In evaluation, J1 models dominate across multiple benchmarks:
On RewardBench, J1-Llama-70B achieved 93.3%, outperforming DeepSeek-GRM-27B and nearly matching EvalPlanner-70B.
On JudgeBench, J1 models demonstrated superior position-consistent accuracy against GPT-4o-based outputs.
On PPE Correctness, the Pointwise-J1 models yielded more consistent judgments with lower tie rates than pairwise variants.
Rethinking Reward Models
What sets J1 apart is not just performance but interpretability. The model produces traceable, auditable reasoning paths—something traditional reward models lack. These traces help researchers understand how and why a model made a judgment, which is critical in high-stakes applications.
Moreover, J1 opens the door to next-generation feedback loops. Imagine AI agents that not only act but critique themselves, improve over time, and help align others. With J1 as a foundation, these scenarios are no longer speculative—they are within reach.
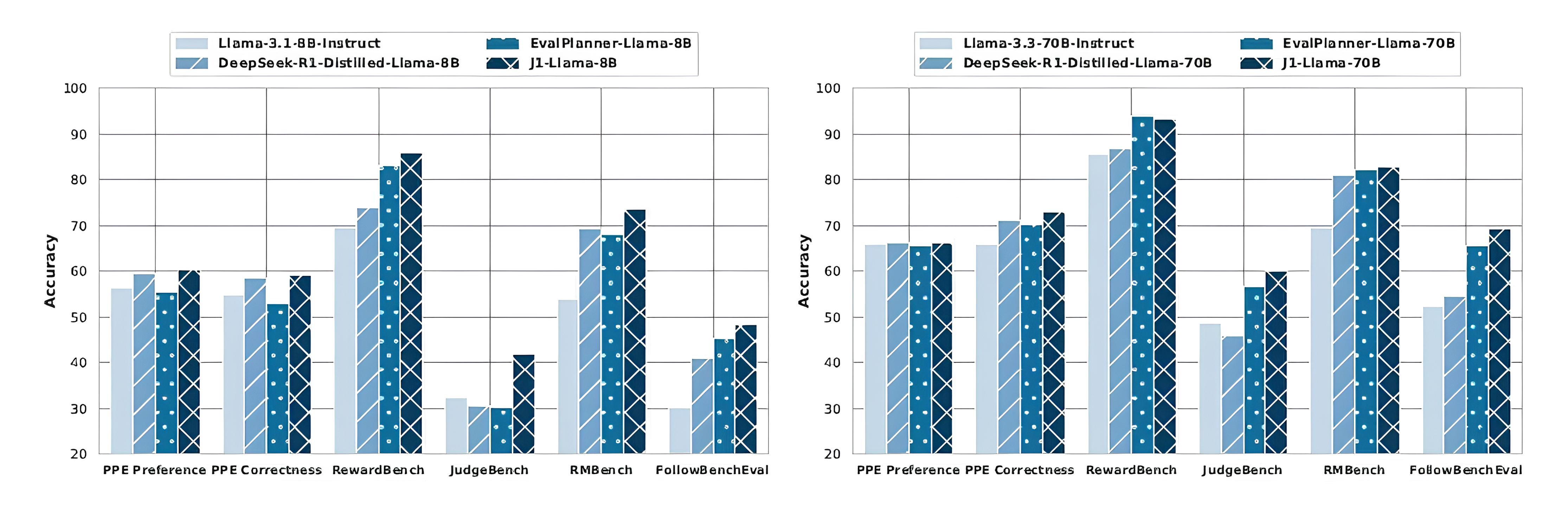
Image Credit: Meta AI
Final Thoughts
Meta AI’s J1 is more than a framework—it’s a reimagination of evaluation. It blends reinforcement learning, synthetic supervision, and structured reasoning into a cohesive architecture that transforms LLMs into self-aware evaluators. As AI systems grow in complexity and autonomy, building models that can reliably reflect on their own behavior isn’t just a nice-to-have—it’s a necessity. J1 shows us how to get there.
EXPLORE MORE ARTICLES
PREVIOUS
NEXT

