Feb 14, 2025

LayerLens was recently given access to the Kimi 1.5 Preview model for early testing and evaluation.
Kimi 1.5, developed by Chinese AI firm Kimi AI (also known as MoonShot AI), is a reasoning model built for cost efficiency and performance. Arriving just days after the release of DeepSeek R1, Kimi has already positioned itself as a strong contender in the AI space. Unlike DeepSeek, Kimi’s premier model is fully open-access—available for immediate use on Kimi AI’s homepage, without requiring a login or signup.
We recently covered R1’s release, and what it meant for the proverbial AI arms race between China and the United States. The launch of Kimi is poised to be yet another catalyst that is tipping the scales in favor of not only China but also the open-source development of AI. In this short article, we dive into our early internal tests with Kimi 1.5 Preview, noting particular areas where it matches or even outperforms its contemporaries. We supplement our findings with data directly from the Atlas Application, where we were able to test Kimi against multiple benchmarks across different scenarios or categories.
Diving into what’s good: speed and readability
Kimi 1.5 delivers exceptionally low latency and high readability, an impressive feat for a reasoning-focused model. Across all tested datasets, its average response time was 27.5 seconds—five times faster than DeepSeek R1, which struggled particularly with complex reasoning tasks, often taking over two minutes per prompt. Kimi was only 15 seconds slower than Claude 3.5 Sonnet, despite generating significantly longer responses.
Kimi also excels in readability, even in English, despite being natively trained in Chinese. It scored higher than its peers on the Flesch Human Readability scale, a metric we use to assess how easy a model’s outputs are to understand. This suggests Kimi’s outputs are not only faster but also clearer and more structured.
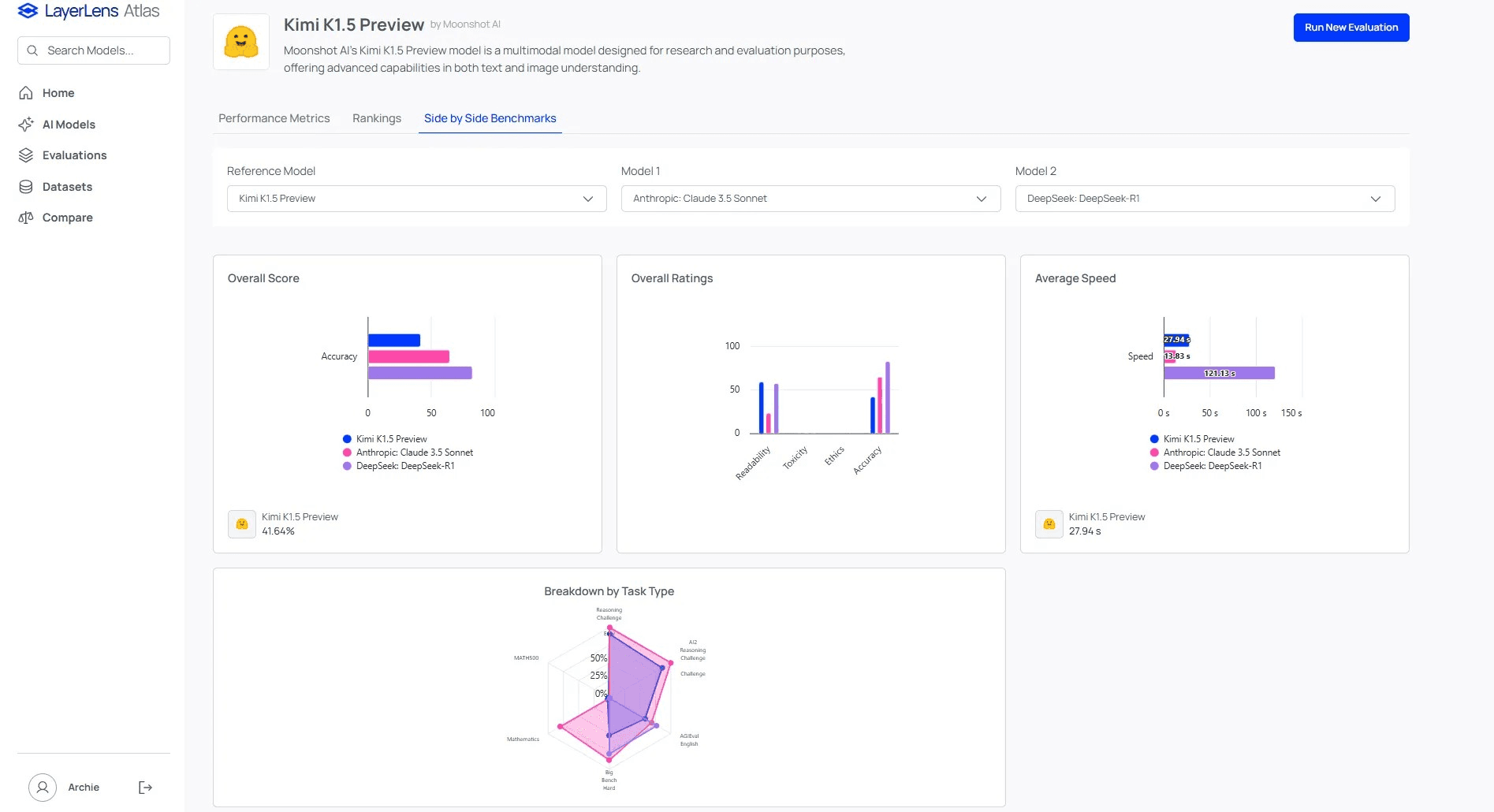
Comparison of metrics for Kimi, DeepSeek R1, and Claude 3.5 Sonnet
Pure Performance: Another indication that China is catching up
Kimi, like R1, is fully open-source, with its code available on GitHub and its development methodology outlined in a publicly available research paper.
While Kimi has not yet reached the top-tier U.S. frontier models, it is rapidly closing the gap. In fact, on key reasoning benchmarks, Kimi matches or surpasses established open-source models like Meta’s Llama 3.1. This is a significant leap forward for open-source AI, especially considering the rapid pace of recent advancements in the Chinese AI ecosystem.

Performance of AI2’s Jamba model, Llama 3 405 B model, and Kimi 1.5 Preview on the Allen AI Reasoning Challenge
What’s next?
Kimi 1.5 is currently in preview, with a model size of 20 billion parameters. We expect Kimi to open-source its API for developers soon. When that happens, we will conduct more fine-grained evaluations across various datasets.
Kimi 1.5’s release reinforces China’s growing influence in AI, particularly in the open-source space. With models like DeepSeek R1 and Kimi emerging in rapid succession, the AI landscape is shifting. Enterprises and researchers now have viable, high-performance alternatives to U.S. models. As Kimi continues to develop and open-source its API, its impact will extend beyond benchmarks, shaping real-world AI applications globally.
EXPLORE MORE ARTICLES
PREVIOUS

NEXT

