Jan 30, 2025

In just a few days, DeepSeek R1 has sent shockwaves through the AI world—topping the App Store, disrupting the U.S. stock market, and positioning China as a rising force in artificial intelligence. But how does it actually stack up against the best AI models from the U.S.? Its associated mobile app has catapulted to number one overall on the App Store, and its rumored low inference cost relative to its performance has cast legitimate doubt on the US’s dominance in artificial intelligence and technology, creating a ripple in the US stock markets.
However, this reaction has certainly merited the question: “Is China now the dominant player in AI technology?”. The answer is complicated: despite the claims being made on social media, on the news, or even by academia, we still don’t have a comprehensive view of exactly where the premier Chinese models stand with regard to pure performance when compared to their counterparts. Today, we are diving into data produced by LayerLens Atlas App, a tool that allows for the execution of a variety of benchmarking datasets against over 200 open source and close sourced models, to determine just how well R1 (and other Chinese models) stack up against all too familiar American AI models such as ChatGPT, Claude, and Grok.
What does this data mean?
Before we dive in, let’s clarify what benchmarking actually tells us. AI benchmarks measure a model’s ability to complete predefined tasks—like solving math problems, writing code, or making logical inferences. For example, the BigBenchHard test assesses critical thinking through multiple-choice logic puzzles, while HumanEval tests if a model can generate working Python code. The data we are about to analyze does not encompass the full range of performance, or user-experience, that one might expect out of a language model. Non-quantiative traits, such as R1’s ability to show its thinking process, or its low price barrier, likely play a large role in its wide-scale adoption and virality this week. What this data does show is R1’s performance on objective, knowledge-based tasks. These tasks encompass everything from ability to program in Python to being able to manage a spreadsheet related to accounting or taxes.
R1 vs US counterparts: the raw data
R1 is extremely competitive: in our initial tests, R1 surpasses premier models such as GPT-4o, Claude Sonnet, and Amazon Nova for most categories. In generalized reasoning, R1 beat Amazon Nova, and was only slightly behind XAI’s Grok 2.
Where R1 Excels
Reasoning & Logic: Outperforms Amazon Nova and is nearly on par with Grok 2 in AI2 and BigBenchHard benchmarks, which assess critical thinking and problem-solving abilities.
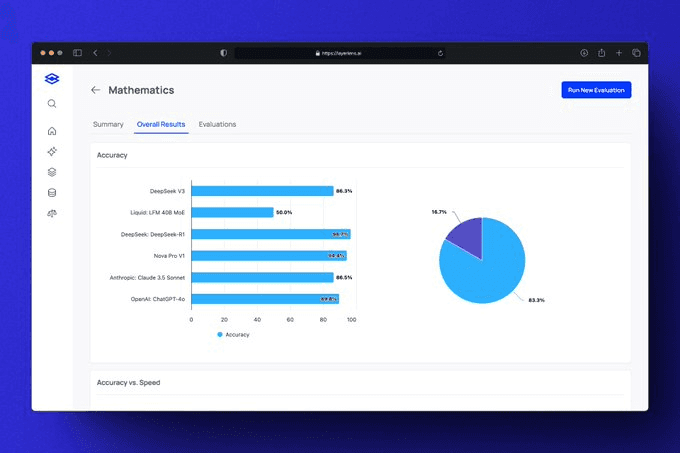
Mathematics: Leads the math benchmarks, demonstrating strong analytical capabilities.
Stock Market Analysis: DeepSeek V3, a model closely related to R1, ranks highly on the Stock BCS dataset, which evaluates a model’s ability to analyze financial data and predict stock movements.
Where R1 Falls Short
Coding: Anthropic’s Claude remains the best for generating runnable Python code, though DeepSeek V3 is closing the gap. However, these coding benchmarks only measure functional correctness, not efficiency or best coding practices.
Practical Business Tasks: OpenAI models (GPT-4) still dominate in spreadsheet management, bookkeeping, and enterprise automation, where structured, rule-based reasoning is required.
Speed: R1 is significantly slower than competitors due to its more complex reasoning process, making it less viable for time-sensitive commercial applications.
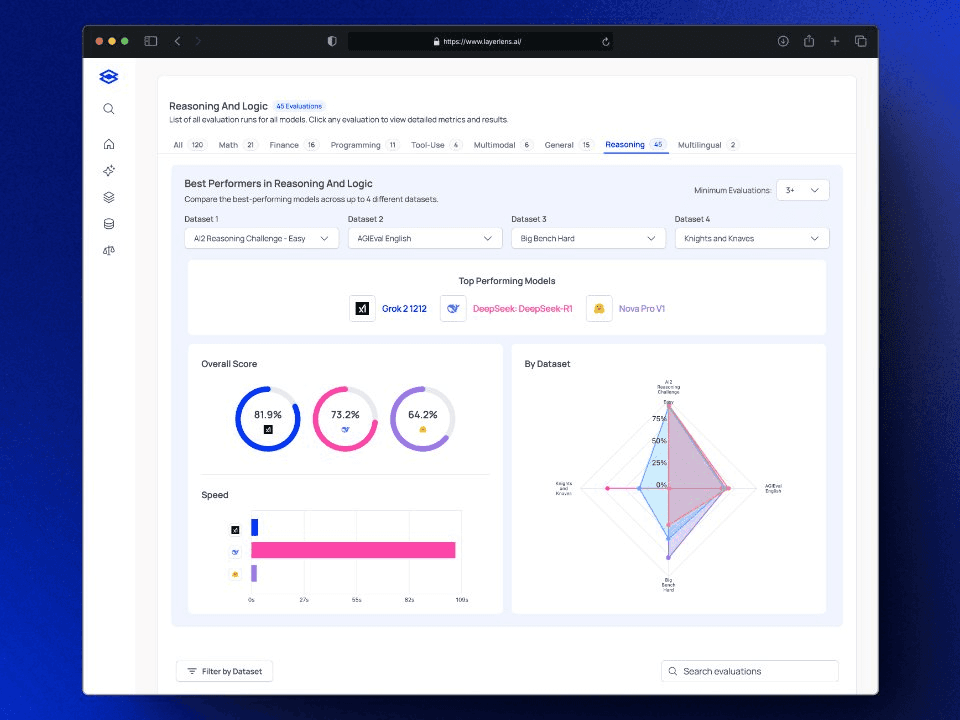
R1 vs Grok 2 vs Nova Pro for Reasoning and Logic
Reasoning and Logic tests, such as AI2 or BigBenchHard, are mostly multiple-choice questions that measure a model’s ability to apply critical reasoning to solve a task. Note that R1 was a lot slower in its response time, mostly due to the fact that it spends a significant amount of time on each question on reasoning and thinking through the prior conversation history.
In coding, Anthrophic’s Claude models still lead (reflecting popular assumptions), although it seems that DeepSeek’s V3 model is on the verge of catching it in terms of pure performance. Note that these coding tests simply measure whether the output (in Python) is able to compile and execute successfully: they don’t measure efficiency or code cleanliness.
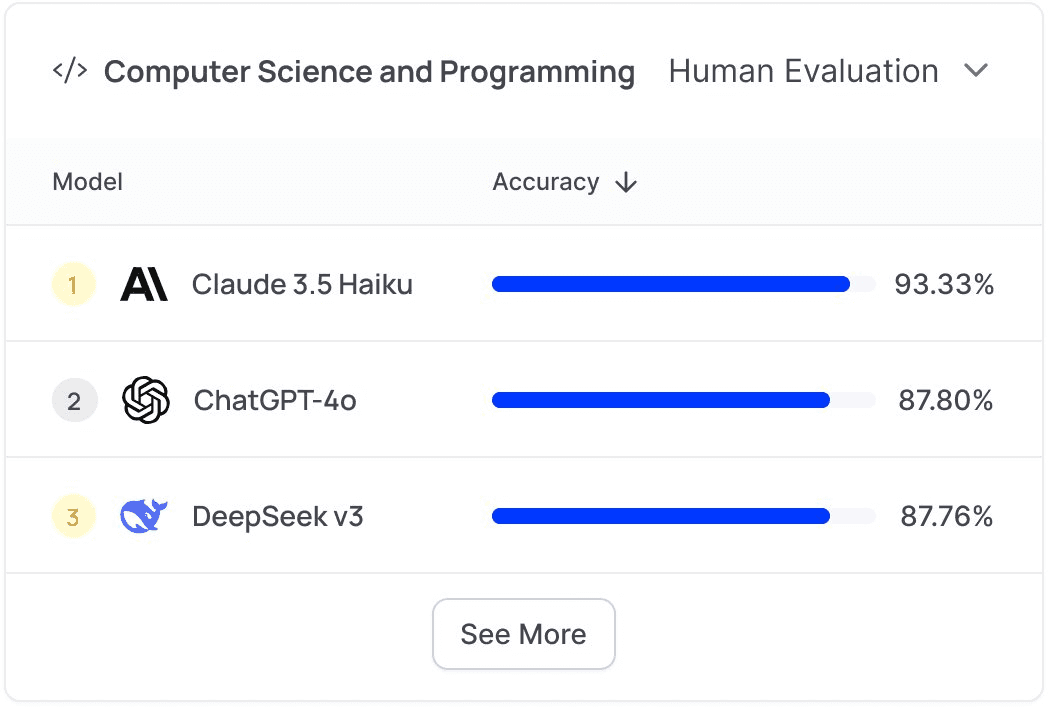
Leaderboard for HumanEval, a popular coding dataset
Finally, when it comes to more practical tasks, such as managing books or spreadsheets, OpenAI still leads. However, it is noteworthy that DeepSeek’s models seem to be extremely good at analytical tasks. R1 leads in the mathematics benchmark, while also V3 scores high on Stock BCS, a dataset that measures the ability of a model to make trading predictions for a tradeable security based on data.
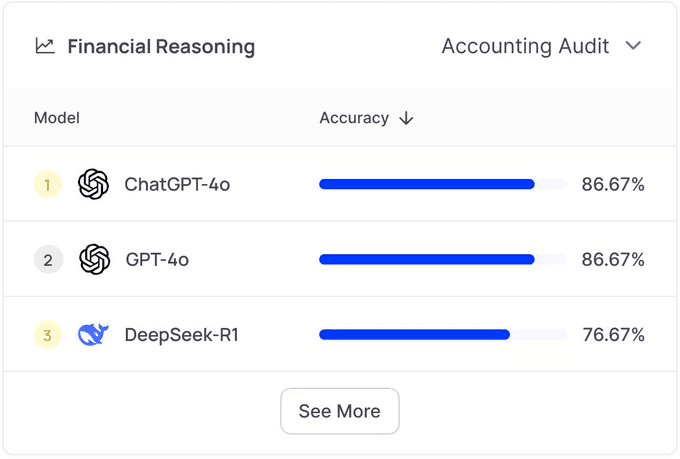
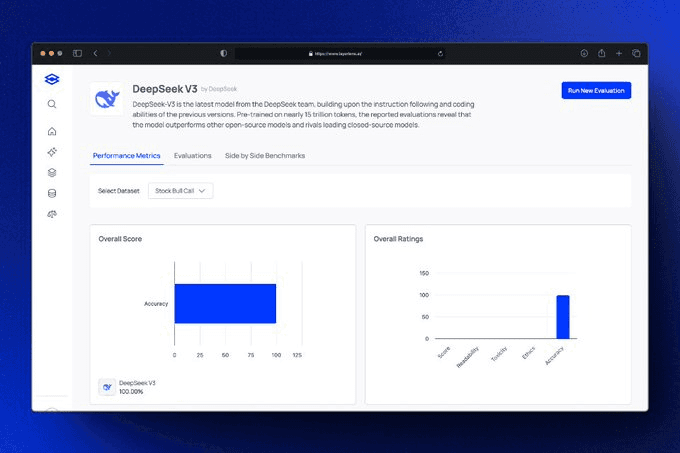
Key Takeways
R1 is certainly catching up, but has not completely eclipsed the premier US models, especially on practical, non-quantative tasks. Although both it and its cousin DeepSeek V3 show incredible performance on academic benchmarks, it still lags behind when it comes to practical tasks, such as coding or accounting. Furthermore, its speed (or lack thereof) also makes it less viable for most commercial or consumer use-cases. While the American frontier model companies and labs should be worried, the reaction shouldn’t be panic, but rather reprioritizing the development of safe and reliable intelligence.
LayerLens Atlas
LayerLens will continue prioritizing the validation of foundational models, whether it is through the independent and open execution of benchmarks against new models, or doing independent analysis of models when faced with unique or niche tasks. Our analysis of DeepSeek showed that its latest suite of models are performing competitively with the top labs, even with significantly fewer resources. As enterprises decide which AI models to trust, objective benchmarking will be more critical than ever. At LayerLens, we’ll continue testing the latest models—not just to compare China vs. the U.S., but to help businesses make informed AI decisions. Stay tuned for our next deep dive. Ready to see how LayerLens can help your enterprise unlock the full potential of AI? Schedule a demo or learn more today!
EXPLORE MORE ARTICLES
PREVIOUS

NEXT

