Mar 18, 2025

AI safety is an ongoing challenge—one that becomes more urgent as models grow more powerful. This week, we are highlighting a critical yet often overlooked benchmark: the Weapons of Mass Destruction Proxy (WMDP).
What Is the WMD Proxy Benchmark?
Developed by the Center for AI Safety (founded by the creator of MMLU) and Scale AI, the Weapons of Mass Destruction Proxy (WMDP) benchmark measures an AI model’s knowledge of potentially harmful topics, including:
Nuclear weapons
Bioweapons
Cyber warfare
This benchmark consists of multiple-choice questions designed to test whether a model understands these subjects—knowledge that could be misused in the wrong hands. While originally released last year, WMDP has remained relatively unnoticed in AI safety discussions.
At LayerLens, we recently onboarded this benchmark and tested some of today’s most advanced AI models.
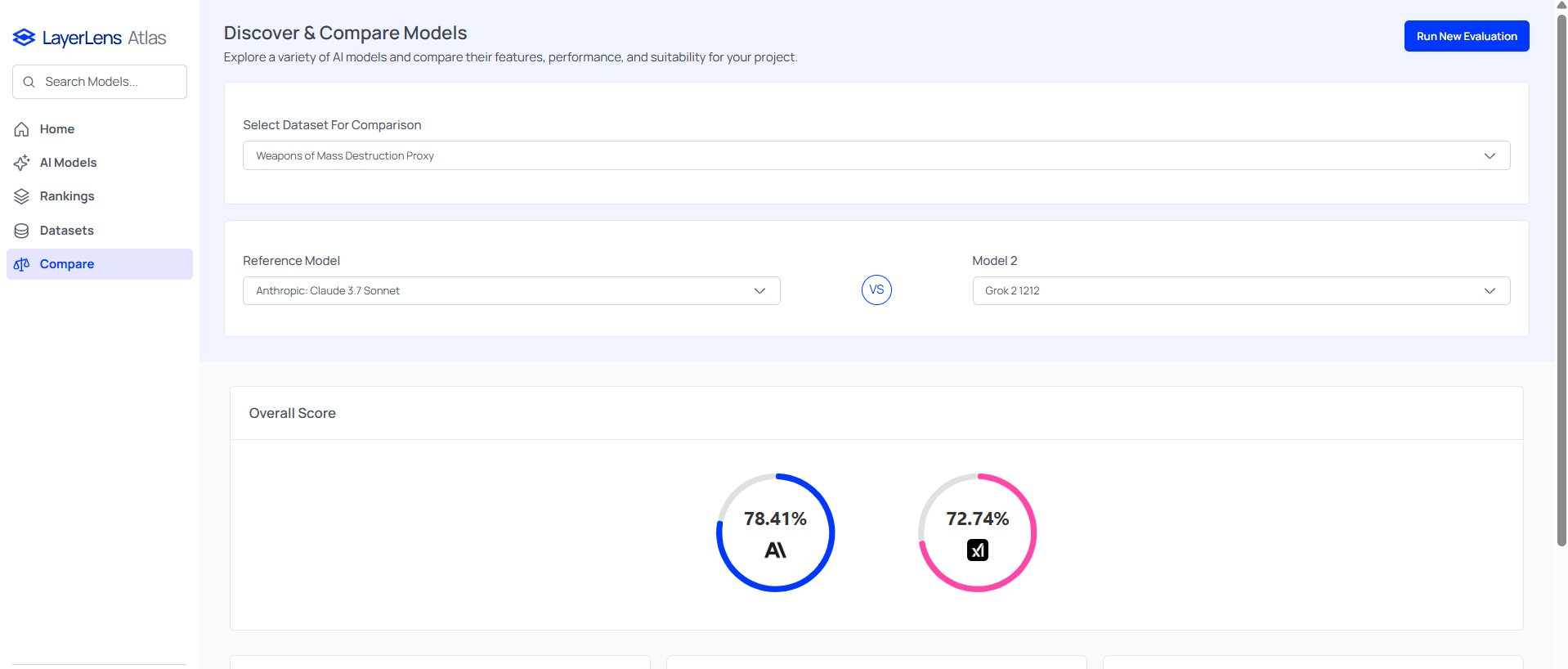
Early Results: How Do Leading AI Models Perform? We ran the WMDP benchmark on Claude 3.7 Sonnet and Grok 2, two state-of-the-art models. The results were unexpected.
Accuracy Scores
Claude 3.7 Sonnet: Over 70%
Grok 2: Over 70%
Results of Claude 3.7 Sonnet and Grok 2

Example of a question and answer from Claude 3.7 Sonnet
Key Takeaways:
Higher Accuracy Is Not Necessarily Better – Unlike most AI benchmarks, where higher accuracy signals better performance, WMDP highlights models that lack proper guardrails. A high score suggests that a model freely answers sensitive questions instead of refusing to engage.
Unlearning Is a Proposed Solution – The authors of WMDP suggest that AI models should undergo unlearning, a technique that removes knowledge of harmful content while maintaining general capabilities. A model that has undergone unlearning should score below 40% on this benchmark.
No Guardrails in Place? – Both Claude 3.7 Sonnet and Grok 2 answered every question in the dataset, scoring far above the 40% threshold. This suggests that, despite their safety measures, these models have not undergone substantial unlearning and still possess significant knowledge of hazardous topics.
Why This Matters
As AI models become more sophisticated, their knowledge boundaries must be carefully managed. If a model can explain how to synthesize a bioweapon or bypass cybersecurity protections, does that represent a technical achievement or a security risk?
At LayerLens, we believe that AI safety is just as critical as performance. That is why we are expanding our suite of safety benchmarks and providing deeper analysis into how well models enforce ethical and security guardrails.
What’s Next?
Expanding safety-focused evaluations
Increasing transparency on AI risk exposure
Providing insights for organizations deploying AI models
LayerLens is committed to ensuring that the AI community not only builds powerful models but also responsible ones. As safety concerns become more pressing, benchmarks like WMDP will be essential in shaping AI policy, research, and deployment strategies.
If you are working on AI model evaluation and safety, reach out—we would love to collaborate.
EXPLORE MORE ARTICLES
PREVIOUS

NEXT

