
AI Teams Are Repeating the Biggest Mistake in Software History
Author:
The LayerLens Team
Last updated:
Published:
The LayerLens Team builds continuous evaluation infrastructure for AI. Stratix evaluates 200+ models across 100+ benchmarks, using a 4-generation judge system that reaches 96-98% accuracy on production traces.
TL;DR
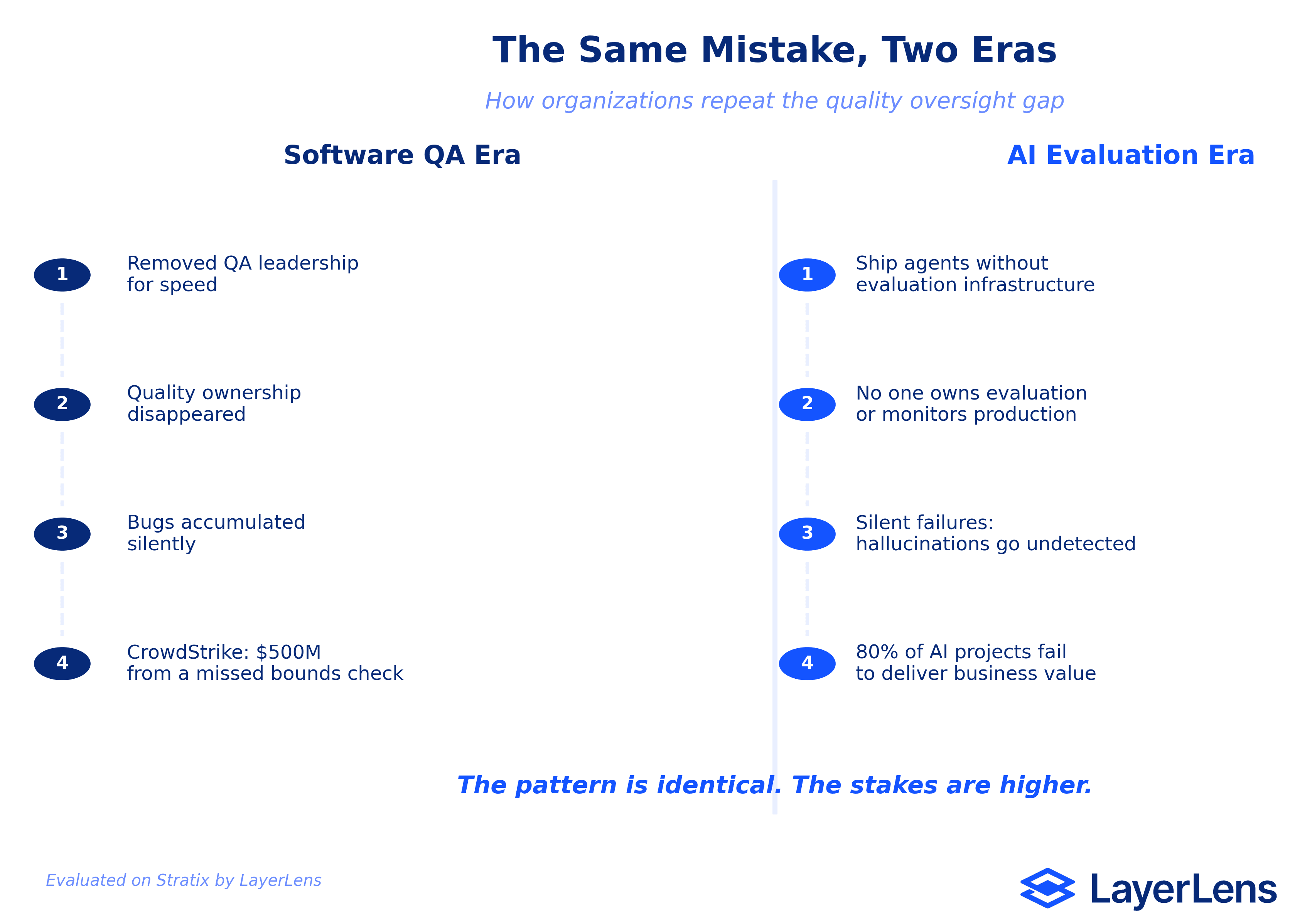
When Agile arrived, organizations removed QA leadership to move faster. Software quality collapsed. The CrowdStrike outage of 2024, caused by a missing array bounds check, was one consequence.
The same pattern is playing out in AI. Teams ship agents to production without evaluation infrastructure, ownership, or strategic oversight. 80% of AI projects fail to deliver business value.
Automation alone does not fix this. Static benchmarks show a 37% gap from real-world performance. 47% of enterprise AI users have based major business decisions on hallucinated content.
Continuous evaluation infrastructure restores the missing layer: structured judgment, production monitoring, and evaluation that learns. The same strategic oversight that QA leadership once provided, rebuilt for AI systems.
The Pattern That Keeps Repeating
Software engineering has a habit of removing the people responsible for quality and then wondering why quality disappears.
When Agile swept through the industry in the mid-2000s, organizations restructured around speed. Dedicated QA teams were dissolved. Testing leadership was shown the door. The logic seemed sound: embed testing into development, ship smaller increments, move faster.
What actually happened was different. Removing QA leaders did not distribute quality ownership. It eliminated it. Strategic test governance vanished. Process control disappeared. The people who understood how to think about quality at a systems level, the ones who asked "what breaks when this interacts with that," were gone.
The consequences accumulated quietly. Faster release cycles shipped more bugs. Integration failures multiplied. And then, occasionally, the debt came due all at once.
On July 19, 2024, CrowdStrike pushed a content update to its Falcon endpoint detection platform. A mismatch between 21 expected input fields and 20 provided fields, a basic array bounds check, crashed millions of Windows machines worldwide. Delta Air Lines filed a $500 million lawsuit alleging gross negligence. The root cause, according to multiple post-incident analyses: CrowdStrike's update architecture only rigorously tested some updates. Template instances, the low-level data that tells the sensor what to do, shipped without thorough QA.
A missing bounds check. A skipped test. A quality process that assumed speed could substitute for oversight.
This is what happens when the people who think strategically about quality are no lo
nger in the room.
The AI Version of the Same Mistake
The pattern is repeating, almost exactly, in AI.
Teams build agents. They benchmark them against static test sets. The scores look good. They ship to production. And then the failures start, except this time, the failures are silent.
A March 2026 survey of 650 enterprise technology leaders found that 78% of enterprises have AI agent pilots running. Only 14% have reached production scale. The rest are stuck in what researchers call the "pilot-to-production gap," a space where promising demos collapse under the weight of real-world complexity.
The numbers from RAND Corporation's analysis are worse: 80.3% of AI projects fail to deliver their intended business value. One-third are abandoned before reaching production. Another 28% reach completion but fail to deliver expected value. Only 19.7% of AI initiatives achieve their objectives.
These are not technology failures. They are oversight failures. The five root causes cited most frequently across enterprise surveys: integration complexity, inconsistent output quality at volume, absence of monitoring tooling, unclear organizational ownership, and insufficient domain-specific evaluation data.
Three of those five are structural problems. No one owns evaluation. No one monitors production quality. No infrastructure exists to catch what goes wrong after deployment.
What Silent Failure Actually Looks Like
Traditional software fails loudly. A null pointer throws an exception. A timeout triggers an alert. A crash generates a stack trace.
AI systems fail quietly. An agent completes a workflow, returns a confident response, and the output is wrong. The error surfaces hours or days later, when a downstream decision built on hallucinated data falls apart.
Production incidents in AI systems are now universal, not exceptional. When 84.9% of teams experience incidents within six months of deployment, the question is not "if" but "how quickly the team detects."
The hallucination data is specific and sobering. Frontier models in 2026 hallucinate between 3.1% and 19.1% of responses depending on task complexity. On legal questions, rates reach 18.7%. On medical queries, 15.6%. MIT research found that models use more confident language when generating incorrect information: 34% more likely to say "definitely" or "certainly" when the answer is wrong.
And here is the statistic that should concern every executive: 47% of enterprise AI users have based at least one major business decision on hallucinated content.
This is what a system without evaluation leadership looks like. The failures are invisible unti

l they are expensive.
Why Automation Alone Cannot Fix This
The instinct, in both the QA era and the AI era, is to automate the problem away. Write more unit tests. Run more benchmarks. Add another CI check.
Automation catches predictable failures. It does not catch the failures that matter.
Enterprise agentic AI systems show a 37% gap between lab benchmark scores and real-world deployment performance. A model that scores well on a curated test set encounters edge cases, ambiguous inputs, adversarial data, and domain-specific failure modes that no static benchmark anticipated. 43% of AI-generated code changes require manual debugging in production even after passing QA and staging tests.
Static benchmarks are the unit tests of AI evaluation: necessary, insufficient, and dangerous when treated as the whole picture. A model score is not a deployment guarantee. A system that gets the right answer for the wrong reasons on a benchmark is not robust. It is temporarily lucky.
The parallel to QA is exact. Automated test suites were supposed to replace QA leadership. They replaced the mechanical act of running tests. They did not replace the strategic thinking about what to test, when to test it, and what a passing test actually means in the context of a shipping product.
AI evaluation has the same gap. Running benchmarks is mechanical. Deciding which benchmarks matter for a specific production use case, defining what "good enough" means for a particular domain, monitoring for degradation over time, catching the failure modes that benchmarks were never designed to find: that is evaluation leadership. And in most organizations deploying AI, no one owns it.
What Evaluation Infrastructure Actually Looks Like
The answer is not more automation. It is not less automation either. It is structured evaluation with human judgment built into the system.
A soccer team does not choose between having players and having a coach. The coach provides strategic oversight, reads the field, adjusts the formation, and makes the calls that individual players cannot make from their position on the pitch. Remove the coach, and eleven talented athletes run around without coordination.
Evaluation infrastructure is the coaching layer for AI systems. It provides three things that ad-hoc testing and static benchmarks cannot:
Production-grade monitoring that catches what benchmarks miss. Real evaluation infrastructure watches every tool call, every retry, every hallucinated step in a production agent trace. It does not score a frozen test set once and declare victory. It scores live behavior continuously.
Structured judgment, not just automated scoring. One judge gets it wrong twenty percent of the time. Three judges that disagree force the system to pick one and explain why. This is the principle behind deliberation panels: multiple evaluation perspectives that surface disagreements, resolve them through structured reasoning, and reach verdicts that single-judge systems miss. The accuracy difference is measurable: single LLM-as-Judge systems achieve roughly 70% accuracy. Deliberation panels reach 96-98%.
Evaluation that learns from production. Static benchmarks decay. The edge cases that mattered six months ago are not the edge cases that matter today. Evaluation infrastructure builds benchmarks from actual production data: real support tickets, real user queries, real failure modes. Drop in a folder of production edge cases, and the system builds an evaluation suite

from the data that actually matters to the business.
The 4-Generation Evaluation Ladder
Evaluation technology has progressed through four generations, each closing a gap the previous generation left open:
Generation 1: LLM-as-Judge. A single language model scores another model's output. Fast, scalable, roughly 70% accurate. The equivalent of automated unit tests: catches obvious failures, misses context.
Generation 2: Agent-as-Judge. An agent with tool access evaluates outputs by checking external sources, running code, verifying claims. Roughly 85% accurate. Adds verification but still operates from a single perspective.
Generation 3: Agentic Judge. Multiple evaluation agents coordinate, each specializing in different quality dimensions (factual accuracy, coherence, safety, task completion). Roughly 90% accurate. The equivalent of a QA team with specialized roles.
Generation 4: Deliberation Panel. Multiple judges evaluate independently, surface disagreements, and resolve them through structured deliberation with explicit reasoning chains. 96-98% accuracy. The equivalent of a QA review board: diverse perspectives, structured debate, documented decisions.
Each generation does not replace the previous one. They layer. Production evaluation infrastructure runs all four, using lighter judges for routine checks and escalating to deliberation panels for high-stakes decisions. The same way a well-run QA organization uses automated tests for regression, manual testing for exploration, and leadership review for release decisions.
The Cost of Waiting
The QA leadership lesson took the software industry nearly two decades to learn. Organizations that removed testing leadership in 2005 were still dealing with the consequences in 2024. The CrowdStrike incident was not an anomaly. It was the predictable result of an industry that systematically underinvested in quality oversight for twenty years.
AI teams do not have twenty years. The deployment velocity is faster. The failure modes are less visible. The business decisions built on AI outputs are higher-stakes. And the regulatory environment is tightening: the 2026 International AI Safety Report explicitly flags evaluation infrastructure gaps as a systemic risk.
The organizations that build evaluation infrastructure now, that invest in structured judgment and production monitoring and continuous assessment, will be the ones whose AI systems actually work at scale. The ones that rely on benchmarks and hope will join the 80% failure statistic.
The question is not whether AI needs evaluation leadership. The data already answered that. The question is whether teams will learn from software's twenty-year mistake, or repeat it.
Key Takeaways
The Agile transformation removed QA leadership from software organizations. Quality did not get distributed. It disappeared. The CrowdStrike outage was one of many consequences.
AI teams are repeating the pattern: shipping to production without evaluation ownership, monitoring infrastructure, or strategic oversight. 80% of AI projects fail to deliver business value.
Silent failures are the defining risk of production AI. Models hallucinate with more confidence than they state facts. 47% of enterprises have made major decisions based on hallucinated content.
Static benchmarks show a 37% gap from production performance. Automation catches predictable failures. Domain expertise and structured judgment catch the failures that matter.
Deliberation panels (multi-judge evaluation with structured reasoning) achieve 96-98% accuracy versus 70% for single-judge systems. The gap is the difference between a team with a coach and a team without one.
Evaluation infrastructure is not optional overhead. It is the structural layer that determines whether AI systems deliver value or join the 80% failure rate.
Frequently Asked Questions
What is continuous evaluation infrastructure for AI?
Continuous evaluation infrastructure monitors AI systems in production, scores live behavior against quality criteria, and builds evaluation benchmarks from real-world data. Unlike one-time benchmark testing, it runs continuously, catching degradation, silent failures, and edge cases that static test sets miss.
Why do 80% of AI projects fail?
According to RAND Corporation's analysis, the primary causes are integration complexity, inconsistent output quality at volume, absence of monitoring tooling, unclear organizational ownership, and insufficient domain evaluation data. Three of the five root causes are structural: no one owns evaluation, monitors quality, or maintains evaluation infrastructure.
What is a deliberation panel in AI evaluation?
A deliberation panel uses multiple AI judges to evaluate the same output independently, then surfaces disagreements and resolves them through structured reasoning. This mirrors how expert review boards operate: diverse perspectives, explicit debate, documented decisions. Single judges achieve roughly 70% accuracy. Deliberation panels reach 96-98%.
How is the AI evaluation gap similar to the QA leadership problem?
In both cases, organizations prioritized speed over structured quality oversight. Agile removed dedicated QA leadership. AI teams ship without evaluation infrastructure. The result is the same: faster delivery of lower-quality outputs, with failures that surface too late to prevent damage.
Can automated testing solve AI quality problems?
Automated benchmarks are necessary but insufficient. Enterprise AI systems show a 37% gap between benchmark scores and production performance. Automated tests catch predictable failures. Human judgment, domain expertise, and structured evaluation catch the edge cases and context-dependent failures that determine whether an AI system actually works for its intended purpose.
What should teams prioritize first when building AI evaluation?
Start with production monitoring: instrument agent traces to see every tool call, retry, and failure in real time. Then add structured judges for the highest-risk workflows. Finally, build custom benchmarks from production data so evaluation reflects the actual use cases the system handles, not generic test sets.
Methodology
This article synthesizes findings from multiple industry sources: RAND Corporation's 2025 analysis of AI project outcomes (2,000+ projects), a March 2026 survey of 650 enterprise technology leaders on AI agent deployment, the 2026 International AI Safety Report, OutSystems' 2026 State of AI Development survey (1,900 IT leaders), hallucination benchmarks across frontier models, and post-incident analyses of the July 2024 CrowdStrike outage. AI evaluation accuracy figures (70% for single-judge, 96-98% for deliberation panels) are based on production evaluation data from Stratix.
Explore the full evaluation infrastructure at Stratix.