
Xiaomi MiMo-V2 Evaluation: Benchmark Results Across 7 Tests on Stratix
Author:
The LayerLens Team
Last updated:
Published:
Author Bio
Jake Meany is a digital marketing leader who has built and scaled marketing programs across B2B, Web3, and emerging tech. He holds an M.S. in Digital Social Media from USC Annenberg and leads marketing at LayerLens.
TL;DR
MiMo-V2-Omni leads the family on agent tasks (48.8% on Terminal-Bench) despite being the multimodal variant, beating Pro by 400 prompts.
All three MiMo-V2 models hit the same BIRD-CRITIC ceiling (28.0% to 29.3%), a 1.3-point spread regardless of model size or training approach.
MiMo-V2-Omni scores 90% on AIME 2025 (27/30), placing it among top-tier reasoning models.
Flash delivers nearly identical IFEval performance to Pro (82.6% vs 84.8%) at a fraction of the cost, but drops 18 points on AGIEval.
No single MiMo-V2 model is best at everything. The "Pro" label does not mean strongest across all tasks.
Introduction
Xiaomi released the MiMo-V2 family on March 18, 2026: three models built for different workloads. Pro handles text reasoning. Omni adds multimodal reasoning. Flash is the lightweight option.
We evaluated all three on Stratix across seven benchmarks, compared them head-to-head with GPT-5.4 and Claude Opus 4.6, and pulled prompt-level data to see where each model actually succeeds and fails.
The benchmarks used include Terminal-Bench Terminus-2 (agent tasks), AIME 2025 and AIME 2026 (competition math), BIRD-CRITIC (production SQL), IFEval (instruction following), and AGIEval English/Chinese (broad knowledge reasoning). Every score referenced below is drawn from automated evaluations on Stratix, not from selective prompting or curated demos.
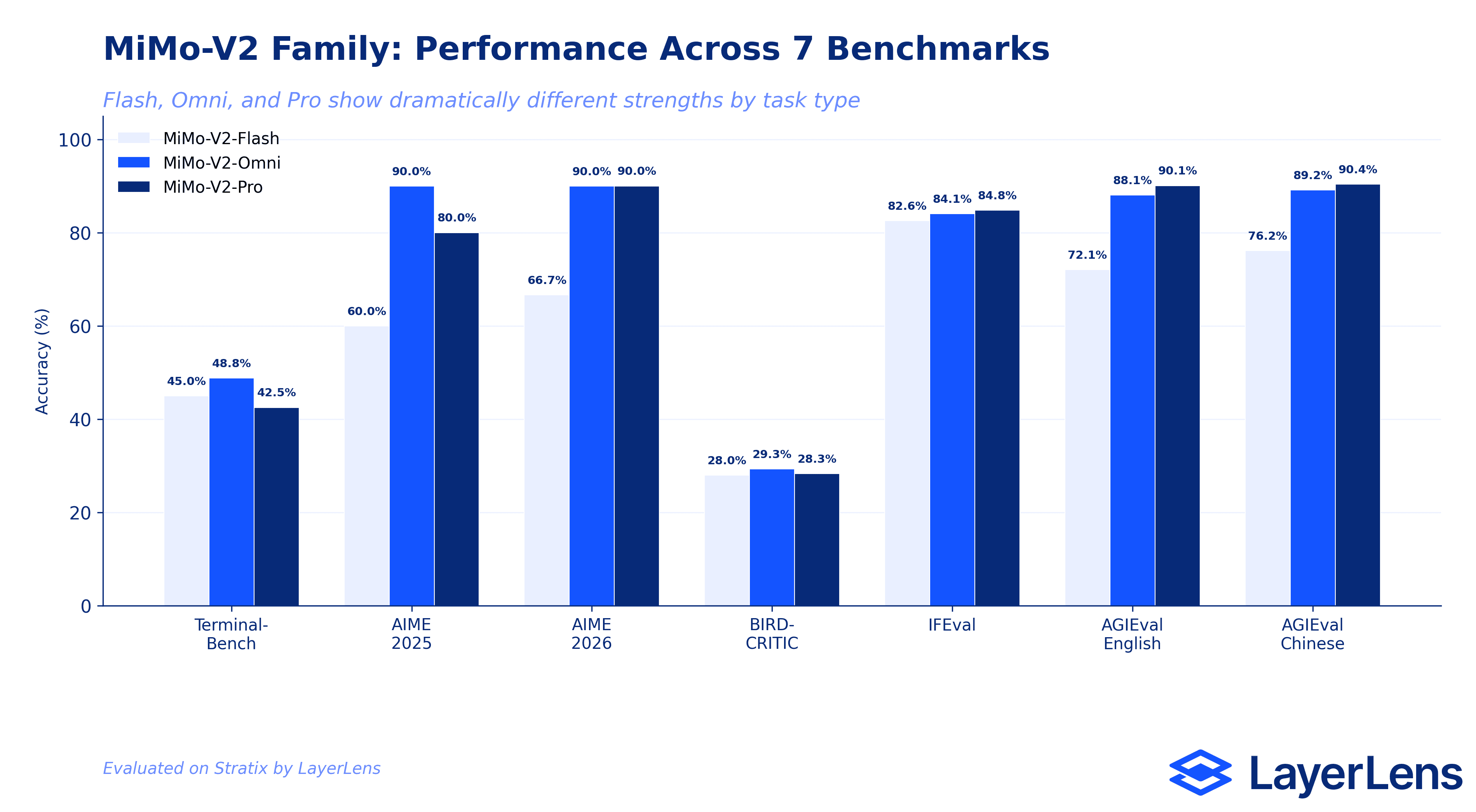
Benchmark Results Overview
Performance varies dramatically across the MiMo-V2 family depending on task type. Here is the full results table across all seven benchmarks, with GPT-5.4 and Claude Opus 4.6 included where evaluations are available.
Terminal-Bench Terminus-2 (Agent Tasks): Omni leads at 48.8%, followed by GPT-5.4 and Flash tied at 45.0%, Pro at 42.5%. Claude Opus 4.6 leads overall at 58.8%.
AIME 2025 (Competition Math): Omni scores 90.0% (27/30), Pro scores 80.0% (24/30), Flash scores 60.0%. GPT-5.4 standard inference: 16.7%.
AIME 2026 (Competition Math): Omni and Pro both score 90.0%, Flash scores 66.7%.
BIRD-CRITIC (Production SQL): Omni 29.3%, Pro 28.3%, Flash 28.0%. A 1.3-point spread across the entire family.
IFEval (Instruction Following): Pro 84.8% (459/541), Omni 84.1%, Flash 82.6% (447/541).
AGIEval English (Broad Knowledge): Pro 90.1%, Omni 88.1%, Flash 72.1%.
AGIEval Chinese (Broad Knowledge): Pro 90.4%, Omni 89.2%, Flash 76.2%.
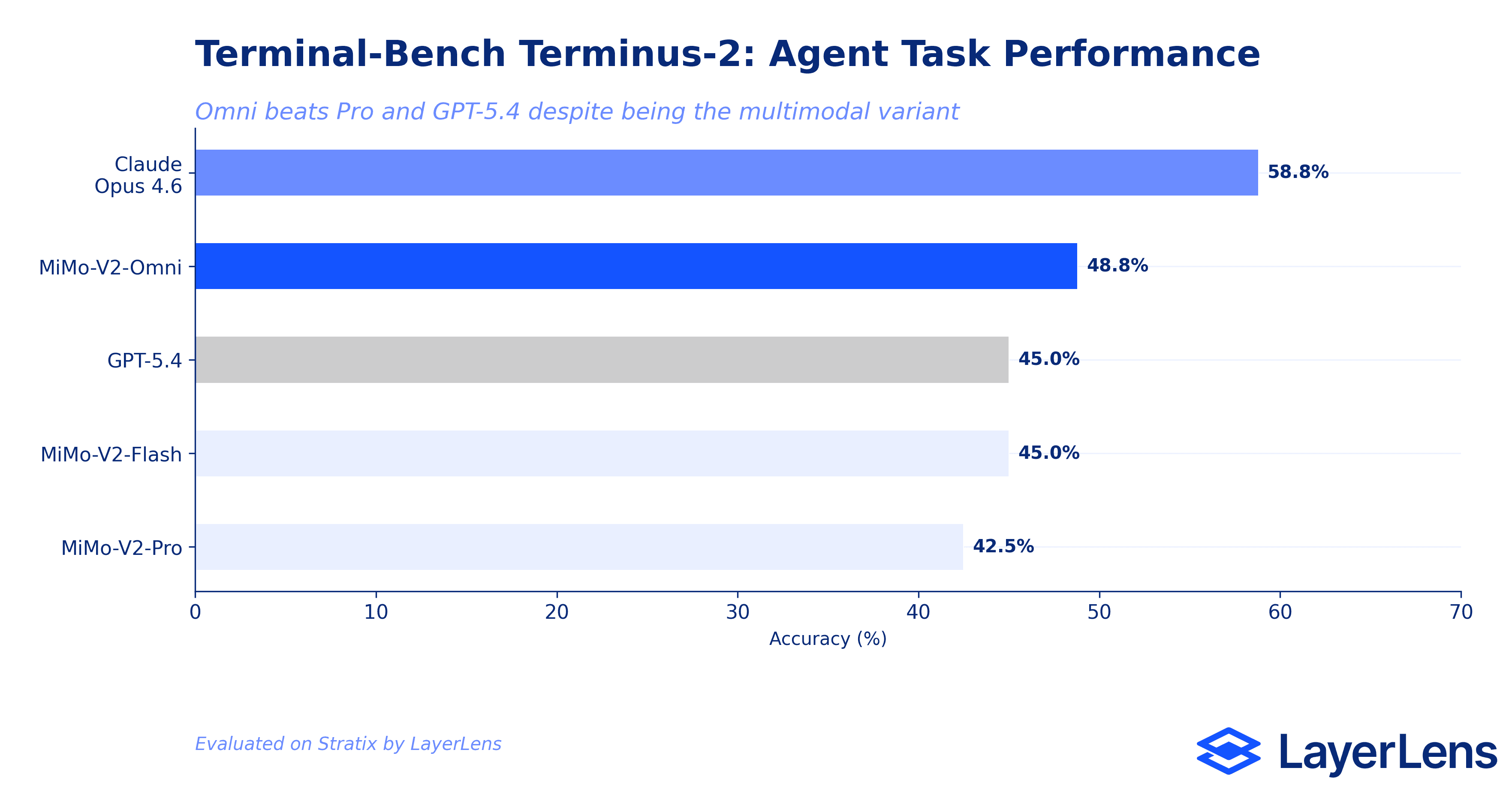
Terminal-Bench: Agent-Relevant Performance
Terminal-Bench Terminus-2 tests real system administration tasks: configuring Nginx, recovering corrupted databases, setting up S3 buckets, fixing package conflicts. This is where agent deployment decisions are made.
Claude Opus 4.6 leads at 3,760/6,400 correct (58.8%). MiMo-V2-Omni follows at 3,120/6,400 correct (48.8%). GPT-5.4 scores 2,880/6,400 correct (45.0%). MiMo-V2-Flash matches GPT-5.4 at 45.0%. MiMo-V2-Pro trails at 2,720/6,400 correct (42.5%).
The result that stands out: MiMo-V2-Omni, the multimodal variant, outperforms MiMo-V2-Pro (the text reasoning specialist) on a text-only agent benchmark by 400 correct prompts. Multimodal training appears to improve general reasoning capabilities, not just image understanding. Omni also beats GPT-5.4 by 240 prompts. Claude Opus 4.6 still holds a significant lead with 640 more correct prompts than Omni.
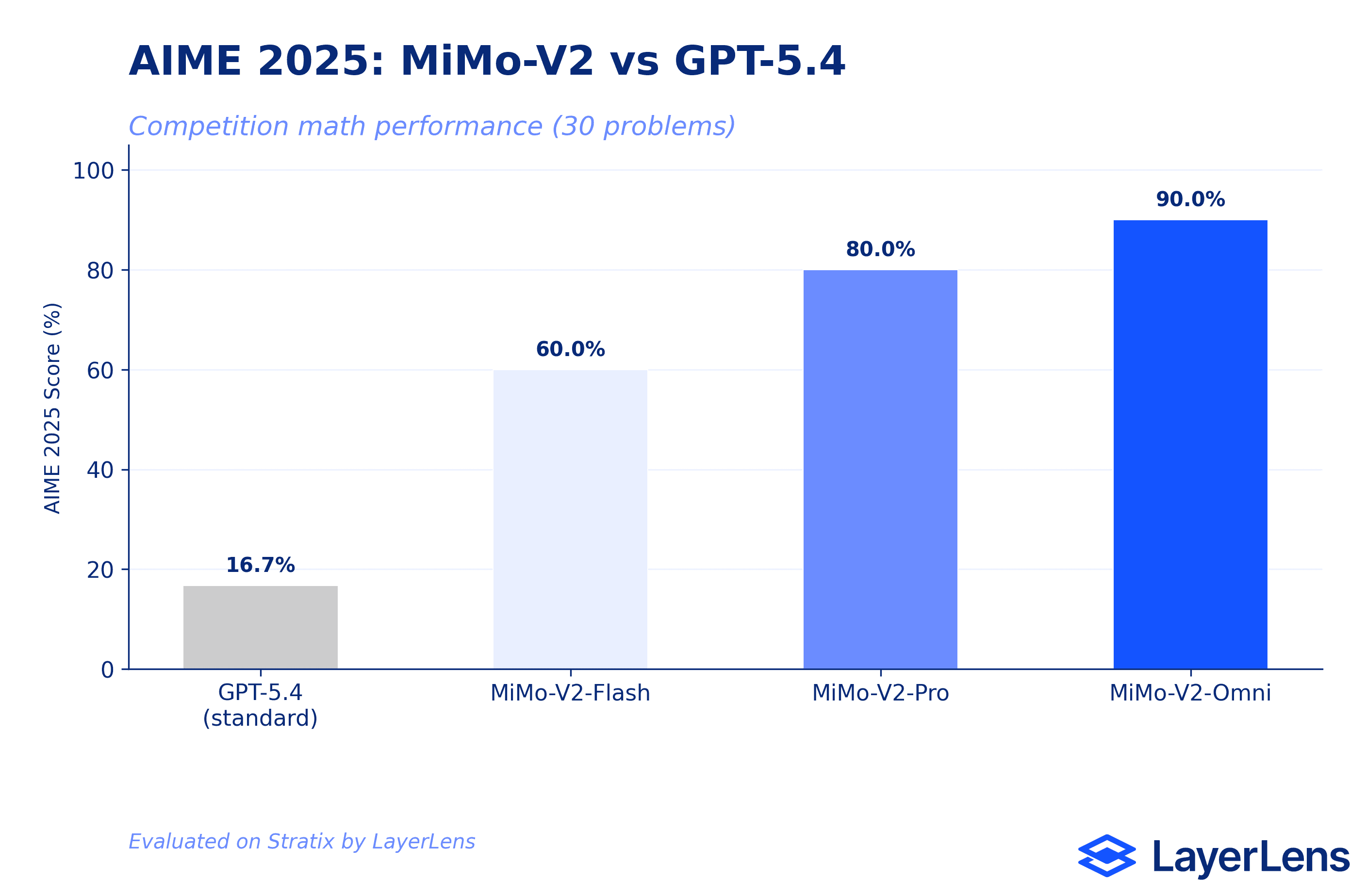
AIME 2025: Where MiMo Excels
AIME (American Invitational Mathematics Examination) is a 30-problem competition math benchmark. This is where the MiMo-V2 family is strongest.
MiMo-V2-Omni scored 27/30 correct (90.0%). MiMo-V2-Pro scored 24/30 correct (80.0%). In a head-to-head comparison on Stratix, Omni and Pro agreed on 23 problems (both correct). Omni solved 4 additional problems that Pro could not. Pro solved 1 problem that Omni missed. Only 2 problems stumped both models.
For context, GPT-5.4 (standard inference) scored 16.7% on the same benchmark. That 80-point gap between GPT-5.4 and MiMo-V2-Omni is not a model quality comparison; it reflects inference configuration. GPT-5.4 without extended thinking is not designed for deep mathematical reasoning. The MiMo-V2 numbers in isolation are strong: 90% on AIME 2025 is a top-tier score.
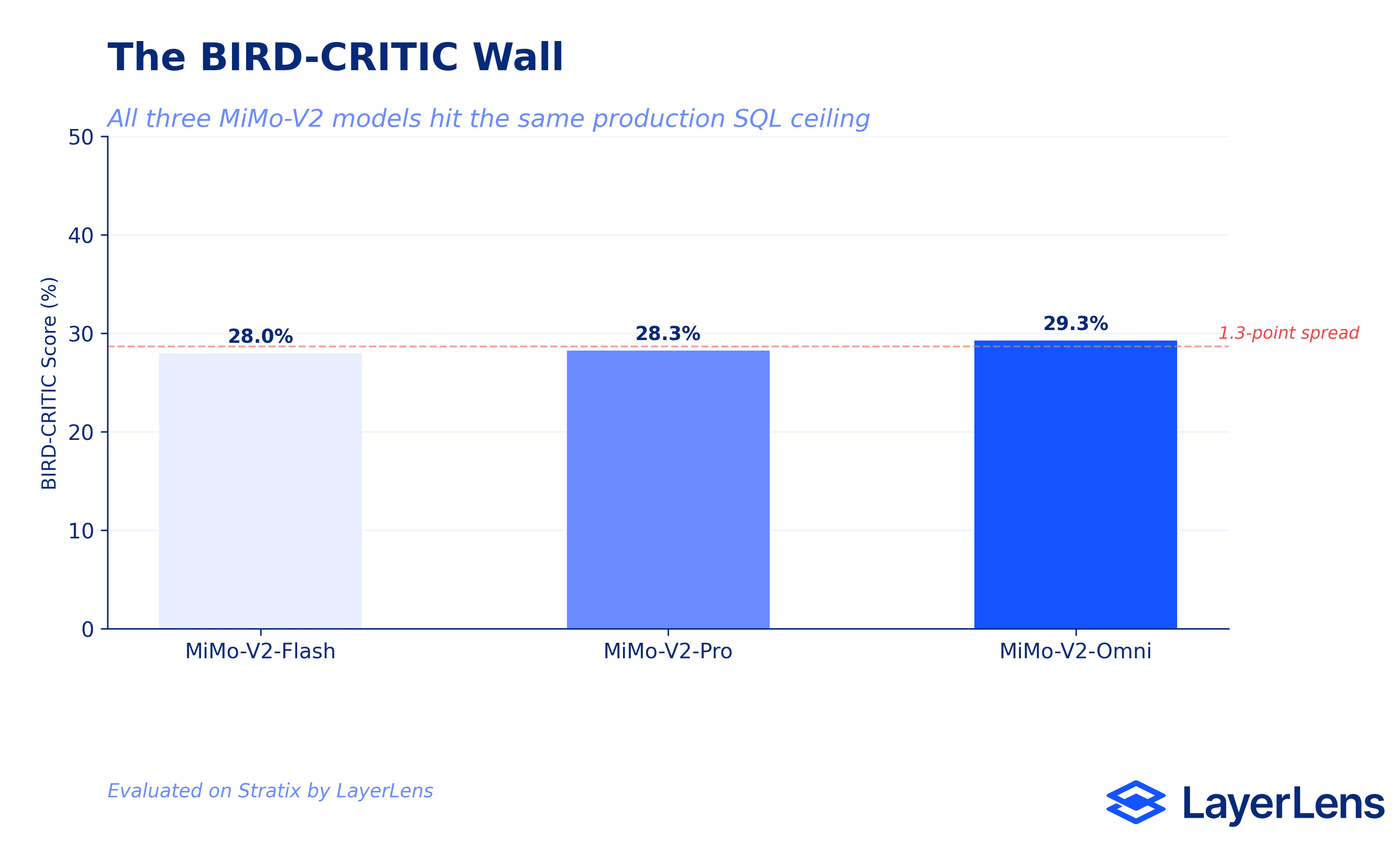
The BIRD-CRITIC Wall
BIRD-CRITIC tests real-world SQL generation against production databases. All three MiMo-V2 models hit the same ceiling: Omni at 29.3%, Pro at 28.3%, Flash at 28.0%.
A 1.3-point spread across the entire family. Model size, multimodal training, reasoning depth: none of it moved the needle on production SQL tasks.
BIRD-CRITIC exposes this pattern across providers. The benchmark tests a specific skill (generating correct SQL against real schemas with ambiguous natural language queries) that does not scale cleanly with general reasoning capability. Models that score 90% on AIME can score below 30% here. If you are evaluating models for a data pipeline that runs SQL against production schemas, BIRD-CRITIC results matter more than AIME scores. The benchmark closest to your production task is the one that predicts performance.
IFEval: Instruction Following
IFEval measures whether a model follows specific formatting and content instructions (write exactly 3 paragraphs, include a specific keyword, respond in a particular language).
MiMo-V2-Pro scored 459/541 correct (84.8%). MiMo-V2-Flash scored 447/541 correct (82.6%). Twelve prompts separate the most expensive model from the cheapest in the family. If your use case is instruction following (chatbots, structured output generation, template filling), Flash delivers nearly identical performance to Pro at a fraction of the cost.
AGIEval: Where Flash Falls Behind
AGIEval aggregates questions from standardized exams (GRE, GMAT, law school, civil service). It measures broad knowledge and reasoning, not production task performance. But it exposes where Flash's cost savings come at a real capability cost.
On AGIEval English: Pro scored 90.1%, Omni scored 88.1%, Flash scored 72.1%. On AGIEval Chinese: Pro scored 90.4%, Omni scored 89.2%, Flash scored 76.2%. Flash drops 18 points behind Pro on English and 14 points on Chinese. Unlike IFEval, this benchmark exposes real capability differences across the family. If your use case involves complex knowledge reasoning, Flash is not a substitute for Pro.
Which MiMo-V2 Model to Use (by Task)
The data points to clear use cases for each variant.
MiMo-V2-Omni is the strongest for agent tasks and mathematical reasoning. It leads on Terminal-Bench and AIME despite being the multimodal variant. If you are deploying agents or need deep reasoning, Omni is the pick.
MiMo-V2-Pro is the strongest for knowledge-heavy tasks and instruction following. It leads AGIEval by a margin and slightly edges Omni on IFEval. For Q&A systems, exam-style tasks, and structured output, Pro is the pick.
MiMo-V2-Flash is viable when cost matters and the task is straightforward. It matches Pro on BIRD-CRITIC (both hit the same wall) and stays within 2 points on IFEval. But it drops significantly on AGIEval and AIME. Use it for instruction following and classification, not for complex reasoning.
Key Takeaways
MiMo-V2-Omni is the strongest model in the family for agent tasks and math, outperforming Pro on Terminal-Bench by 400 prompts despite being the multimodal variant.
The BIRD-CRITIC Wall is real: all three models land within 1.3 points of each other (28.0% to 29.3%) on production SQL, regardless of architecture or training approach.
Flash is a viable cost-saving option for instruction following (82.6% vs 84.8% on IFEval) but not for complex reasoning (72.1% vs 90.1% on AGIEval English).
Model labels ("Pro," "Flash," "Omni") do not reliably predict which variant performs best on a given task. Omni, the multimodal model, wins on text-only agent benchmarks.
Benchmark selection determines your evaluation conclusions. A team that only tests AIME would choose Pro. A team that tests Terminal-Bench would choose Omni. Both would be right for their use case.
Frequently Asked Questions
How does MiMo-V2 perform on benchmarks?
Performance varies by task. Omni scores 90% on AIME 2025 and 48.8% on Terminal-Bench agent tasks. Pro leads on AGIEval (90.1% English). All three models score between 28% and 29.3% on BIRD-CRITIC production SQL.
What benchmarks were used to evaluate MiMo-V2?
Seven benchmarks on Stratix: Terminal-Bench Terminus-2, AIME 2025, AIME 2026, BIRD-CRITIC, IFEval, AGIEval English, and AGIEval Chinese.
Is MiMo-V2 good at coding and agent tasks?
MiMo-V2-Omni scored 48.8% on Terminal-Bench, beating GPT-5.4 (45.0%) and Pro (42.5%). Claude Opus 4.6 still leads at 58.8%.
How does MiMo-V2 compare to GPT-5.4?
MiMo-V2-Omni beats GPT-5.4 on Terminal-Bench (48.8% vs 45.0%) and significantly outperforms it on AIME 2025 (90.0% vs 16.7%, though the GPT-5.4 score reflects standard inference without extended thinking).
What is MiMo-V2 best at?
Competition math (AIME 2025/2026) and agent tasks (Terminal-Bench). Omni is the standout performer on both, scoring 90% on AIME 2025 and leading the MiMo family on Terminal-Bench.
Where does MiMo-V2 struggle?
Production SQL generation. All three variants score between 28% and 29.3% on BIRD-CRITIC, regardless of model size or architecture. This is the clearest ceiling in the evaluation.
Methodology
All evaluations were conducted on LayerLens Stratix using standardized benchmark configurations. Test cases were distributed across seven benchmarks: Terminal-Bench Terminus-2, AIME 2025, AIME 2026, BIRD-CRITIC, IFEval, AGIEval English, and AGIEval Chinese. Each benchmark was run with consistent parameters, and results reflect model performance as of March 2026. Head-to-head comparisons used Stratix's prompt-level comparison feature, which shows per-prompt pass/fail results for any two models on any benchmark.
Full evaluation data is available on Stratix.