
GPT-5.4 Benchmark Review: What Stratix Data Shows Across the Full Model Family
Author:
Jake Meany
Last updated:
Published:
Author Bio
Jake Meany is a digital marketing leader who has built and scaled marketing programs across B2B, Web3, and emerging tech. He holds an M.S. in Digital Social Media from USC Annenberg and leads marketing at LayerLens.
TL;DR
GPT-5.4 scores 94.6% on MATH-500 but only 16.67% on AIME 2025, a 77-point gap between structured math and competition-level reasoning that you will not see in any OpenAI press release.
GPT-5.4 failed SWE-bench Lite entirely. Claude Opus 4.6 scored 62.67% on the same benchmark. For software engineering teams, that gap is the decision.
In a counter-intuitive finding from Stratix data, GPT-5.4 Nano (26.67%) outscored the flagship GPT-5.4 (16.67%) on AIME 2025. Smaller does not always mean weaker when the benchmark changes.
All three GPT-5.4 variants score under 11% on Humanity's Last Exam (HLE), confirming that expert-level multi-domain reasoning is not yet a strength of this model family regardless of tier.
For production decisions, the right question is not "which GPT-5.4 tier is best?" but "which tier handles your specific task type?" The data shows the answer varies by benchmark more than by model size.
Introduction
On March 5, 2026, OpenAI released GPT-5.4 alongside two efficiency variants: GPT-5.4 Mini and GPT-5.4 Nano. The flagship ships with a 1M+ token context window (922K input, 128K output), native computer use, interruptible reasoning, and a Mixture-of-Experts architecture. OpenAI positioned it as a unified successor to the Codex and GPT lines, designed to be the default model for both general-purpose tasks and software engineering. Mini and Nano, released March 17, target high-throughput and speed-critical workloads respectively, each with a 400K context window and lower price points.
Those are the claims. This article examines what actually happened when LayerLens ran the full GPT-5.4 family through independent evaluations on Stratix. Every score in this article comes from those evaluations.
The results reveal a model family with a pronounced strength in structured mathematical reasoning and meaningful gaps in competition math, general knowledge QA, and expert scientific reasoning. Understanding where that ordering breaks down matters for anyone building on this family.
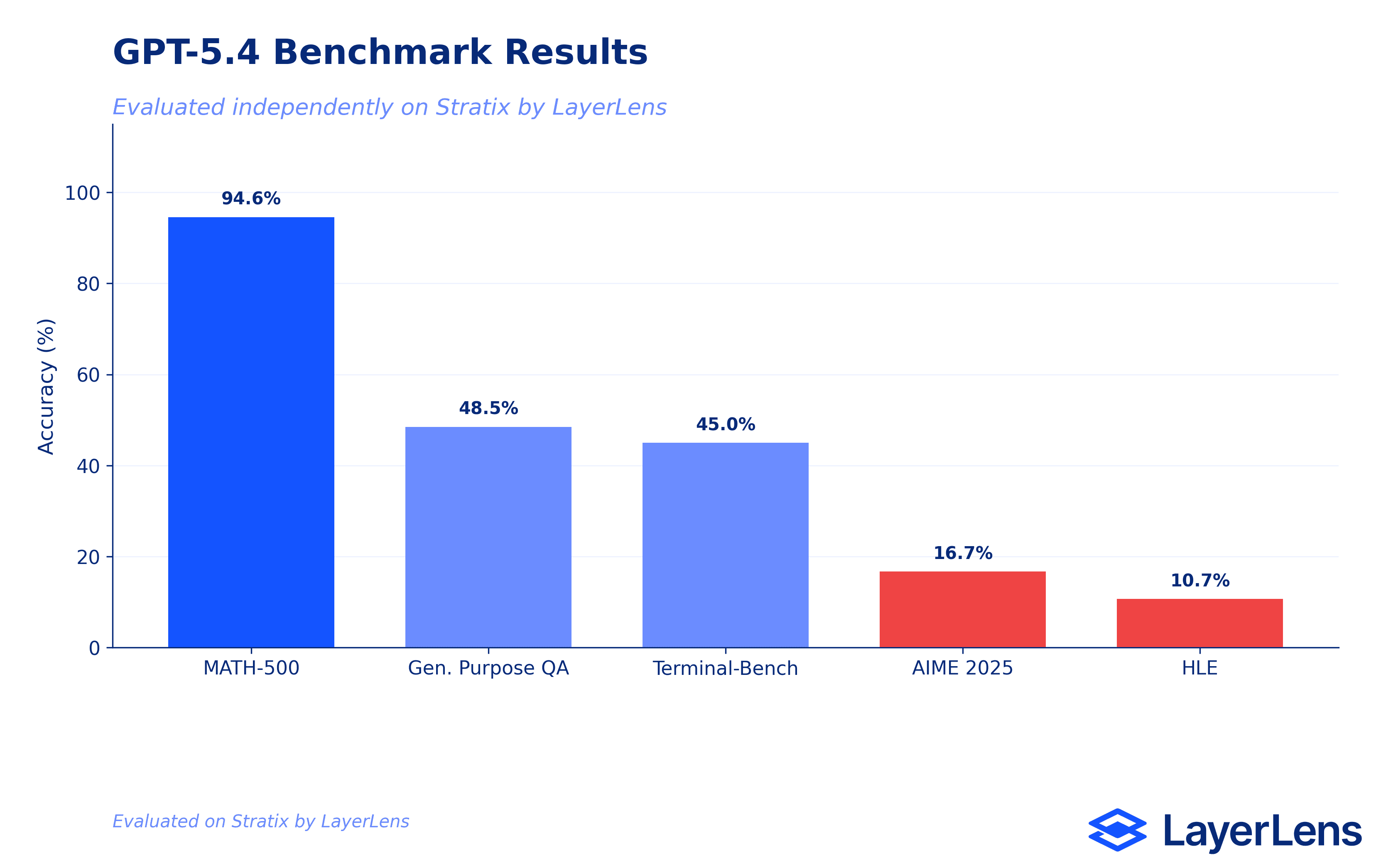
Benchmark Results Overview: GPT-5.4 Flagship
The flagship model ran five benchmarks on Stratix. The spread is wide: a 78-point range from the highest score to the lowest, unusually large for a model at this tier and price point ($2.50 input / $15.00 output per million tokens).
MATH-500 (Math Problem Solving): 94.6%. The strongest result in the benchmark set. Covers algebraic reasoning, number theory, geometry, and precalculus with strict LaTeX output formatting.
General Purpose Question Answering (MultiBench): 48.48%. Measures multimodal content understanding across text, image, and tabular inputs. Below-average for a frontier model at this pricing tier.
Terminal-Bench (Terminus-2): 45.0%. A comprehensive evaluation of LLM capabilities across reasoning types, knowledge areas, and task formats.
AIME 2025: 16.67%. Competition-level mathematical reasoning. The most significant finding in the flagship evaluation set.
Humanity's Last Exam: 10.67%. Expert-level multi-domain scientific reasoning. Single-digit territory for a model at the frontier tier.
SWE-bench Lite (SWE-agent): Evaluation returned a failure status. No score recorded.
Benchmark Results Overview: GPT-5.4 Mini and Nano
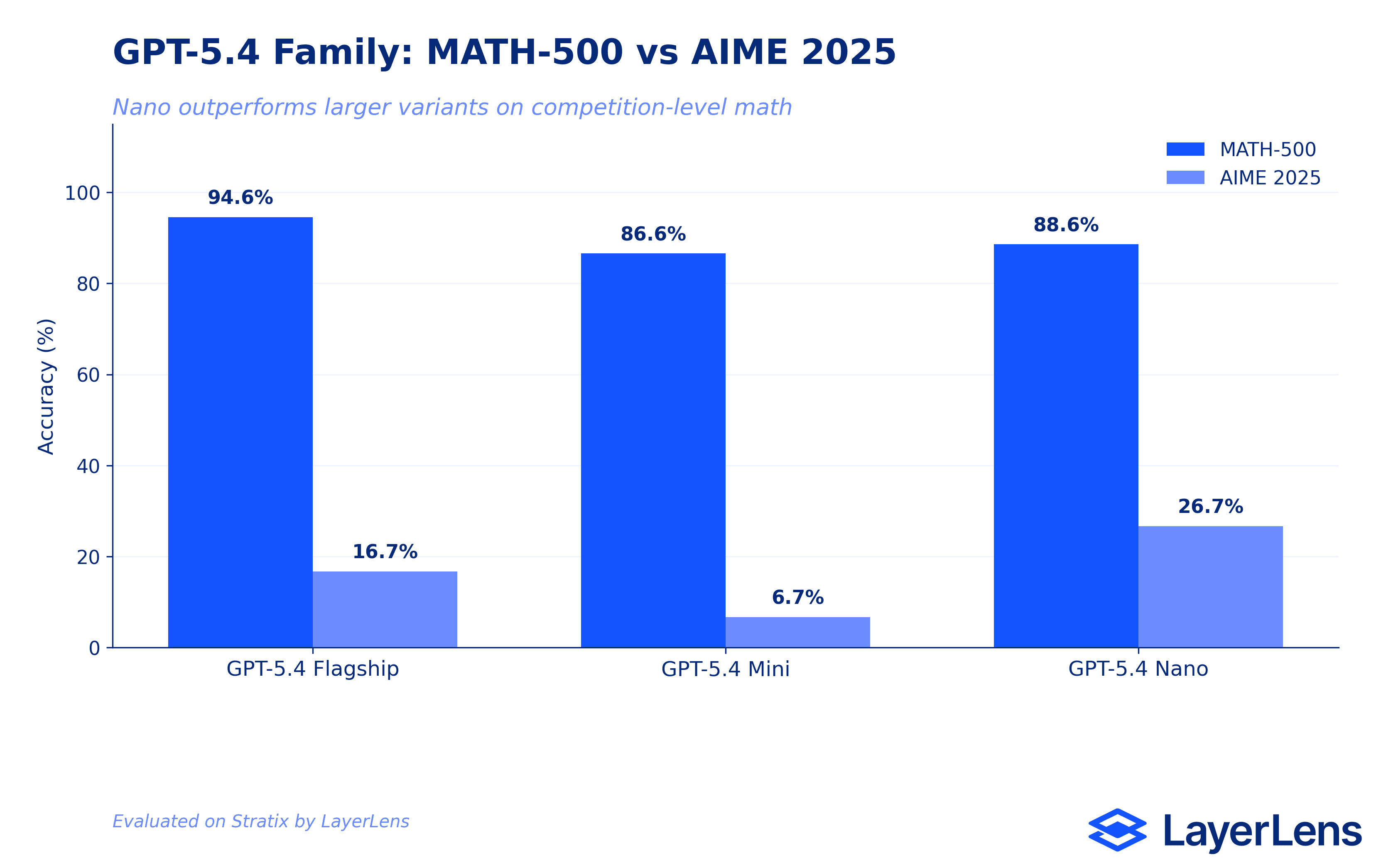
Mini and Nano ran overlapping but distinct benchmark sets, enabling a three-way comparison on several tests.
MATH-500: Nano 88.6% / Mini 86.6% / Flagship 94.6%. Flagship leads, but Nano edges out Mini.
AIME 2025: Nano 26.67% / Mini 6.67% / Flagship 16.67%. Nano outscores both the flagship and Mini. The flagship does not lead here.
AIME 2026: Nano 30.0% / Mini 6.67%. Nano maintains its advantage on competition-style math regardless of test year.
General Purpose QA: Mini 42.42% / Nano 37.37% / Flagship 48.48%. The flagship leads.
Big Bench Hard: Mini 58.02% / Nano 45.63%. Mini leads Nano by 12 points on multi-step reasoning.
MMLU Pro: Mini 55.29% / Nano 35.61%. Mini's largest lead over Nano across any shared benchmark.
AGIEval English: Mini 63.04% / Nano 46.47%. Mini leads on academic English reasoning.
Multimodal Understanding: Mini 55.67% / Nano 42.44%. Mini leads on vision-language tasks.
Humanity's Last Exam: Flagship 10.67% / Mini 5.56% / Nano 3.81%. All three variants under 11%. Family-wide limitation.
SWE-bench Lite: Nano 32.33% / Flagship: failure. Nano is the only variant with a scored result.
Where the GPT-5.4 Family Performs Well
Structured mathematical reasoning is the clearest strength across all three variants. GPT-5.4 at 94.6% on MATH-500 covers the full range of algebraic, geometric, and precalculus problem types. Mini (86.6%) and Nano (88.6%) both hold above the 85% threshold on the same benchmark, making math problem solving the most reliable use case across the entire product family.
AGIEval English is a secondary strength for Mini (63.04%), testing academic reasoning tasks drawn from standardized exams. Big Bench Hard (58.02% Mini) shows multi-step reasoning capability above chance, though it does not represent a leading position relative to comparable frontier models.
Where the GPT-5.4 Family Falls Short
The 77-point gap between MATH-500 and AIME 2025 on the flagship model tells a specific story. MATH-500 tests structured problem types with well-defined solution paths. AIME 2025 tests competition-level mathematical reasoning where the path is not obvious and error compounds across steps. GPT-5.4 solves the former at 94.6% and the latter at 16.67%. For teams using the model for quantitative reasoning in ambiguous or novel scenarios, that distinction matters more than the headline math score.
The SWE-bench Lite failure on the flagship is the other critical finding. OpenAI positioned GPT-5.4 explicitly for software engineering workflows. Claude Opus 4.6 scored 62.67% on the same benchmark. Engineering teams evaluating the GPT-5.4 flagship for code-heavy workloads should run this benchmark in their own environment before committing to a deployment decision.
Humanity's Last Exam scores (Flagship 10.67%, Mini 5.56%, Nano 3.81%) confirm that expert-level scientific reasoning is a consistent weakness across the family. Teams relying on the model for deep scientific or medical analysis should weight this finding accordingly.
The Counter-Intuitive Nano Finding
The most unexpected result in the Stratix evaluation set: GPT-5.4 Nano (26.67%) outscored both GPT-5.4 (16.67%) and GPT-5.4 Mini (6.67%) on AIME 2025. Nano also leads all three variants on AIME 2026 with 30.0%. At $0.20 per million input tokens versus the flagship's $2.50, Nano is 12x cheaper and outperformed its larger counterpart on competition-style math reasoning.
Either interpretation produces the same operational conclusion: benchmark-specific routing is more valuable than defaulting to the most expensive tier. If your workflow includes structured math tasks alongside complex reasoning tasks, the answer is probably Nano for the former and Mini for the latter, not the flagship for both.
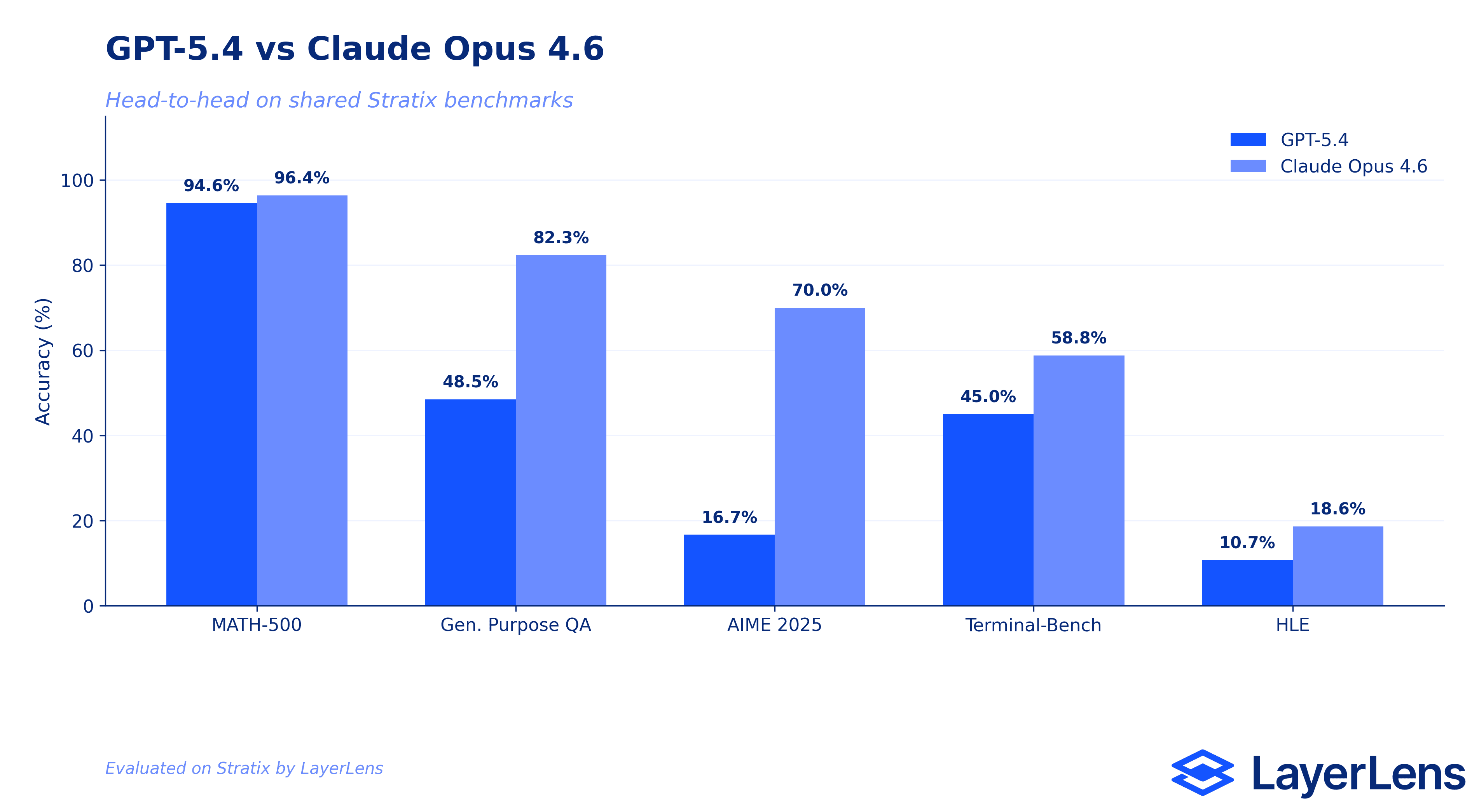
How GPT-5.4 Compares to Claude Opus 4.6
Stratix has five benchmarks with scored results for both models, enabling a direct comparison across the same evaluation conditions.
MATH-500: Claude Opus 4.6 96.4% / GPT-5.4 94.6%. Claude leads by 1.8 points. Not operationally significant for most use cases.
AIME 2025: Claude Opus 4.6 70.0% / GPT-5.4 16.67%. A 53-point gap. The strongest signal for teams where competition-level mathematical reasoning is a core workflow requirement.
General Purpose QA: Claude Opus 4.6 82.32% / GPT-5.4 48.48%. A 34-point gap. General knowledge QA is substantially stronger in Claude Opus 4.6.
Terminal-Bench: Claude Opus 4.6 58.75% / GPT-5.4 45.0%. Claude leads by 13.75 points on command-line reasoning tasks.
Humanity's Last Exam: Claude Opus 4.6 18.59% / GPT-5.4 10.67%. Both score poorly. Claude leads, but neither model is reliable for expert scientific reasoning at this difficulty level.
Across all five shared benchmarks, Claude Opus 4.6 leads GPT-5.4 on every test. The SWE-bench comparison is unavailable: GPT-5.4's evaluation failed; Claude Opus 4.6 scored 62.67%.
What This Means for Evaluation
The GPT-5.4 family illustrates a problem that aggregate benchmark scores cannot solve. A model that scores 94.6% on MATH-500 and 16.67% on AIME 2025 is not "a 55% math model." It is a model with a specific performance profile that either matches or does not match your task. The composite average erases the distinction between those two outcomes.
The counter-intuitive Nano result reinforces the same point from a different angle. A 12x cheaper variant outperformed the flagship on the benchmark most relevant to competition-style reasoning. Continuous evaluation, run against the benchmarks that reflect your actual workload, is the only mechanism that surfaces this kind of finding before it shows up as a production failure.
Full evaluation data for GPT-5.4, GPT-5.4 Mini, and GPT-5.4 Nano is available on Stratix at app.layerlens.ai.
Key Takeaways
GPT-5.4's strongest result is MATH-500 at 94.6%, making structured mathematical reasoning the clearest validated use case. Mini (86.6%) and Nano (88.6%) both hold above 85% on the same benchmark.
The flagship failed SWE-bench Lite. Claude Opus 4.6 scored 62.67% on the same benchmark. Teams evaluating GPT-5.4 for software engineering should run independent evaluations before deployment.
GPT-5.4 Nano outscored both the flagship and Mini on AIME 2025 (26.67% vs 16.67% vs 6.67%) and AIME 2026 (30.0% vs 6.67%). For competition-style math reasoning, Nano is the better and cheaper choice based on current Stratix data.
Across all five shared benchmarks, Claude Opus 4.6 leads GPT-5.4. The gap is narrow on MATH-500 (+1.8 points) and substantial on AIME 2025 (+53.3 points) and General Purpose QA (+33.8 points).
All three GPT-5.4 variants score under 11% on Humanity's Last Exam. Expert-level scientific and multi-domain reasoning is a family-wide limitation regardless of model tier.
Frequently Asked Questions
How does GPT-5.4 perform on benchmarks?
GPT-5.4 scored 94.6% on MATH-500, 48.48% on General Purpose QA, 45.0% on Terminal-Bench, 16.67% on AIME 2025, and 10.67% on Humanity's Last Exam. SWE-bench Lite returned a failure status.
What benchmarks were used to evaluate the GPT-5.4 family?
LayerLens ran the flagship across MATH-500, General Purpose QA (MultiBench), AIME 2025, Humanity's Last Exam, Terminal-Bench (Terminus-2), and SWE-bench Lite. Mini and Nano were additionally evaluated on AIME 2026, Big Bench Hard, MMLU Pro, AGIEval English, Multimodal Understanding, and SWE-bench Lite (Nano only).
Is GPT-5.4 good at math?
For structured mathematical problems, yes: 94.6% on MATH-500. For competition-level reasoning (AIME 2025), the score drops to 16.67%. The distinction between these two math benchmark types is operationally important.
How does GPT-5.4 compare to Claude Opus 4.6?
Claude Opus 4.6 leads GPT-5.4 on all five shared benchmarks: MATH-500 (+1.8 points), General Purpose QA (+33.8 points), AIME 2025 (+53.3 points), Terminal-Bench (+13.75 points), and Humanity's Last Exam (+7.9 points). Claude Opus 4.6 also scored 62.67% on SWE-bench Lite where GPT-5.4 returned a failure status.
What is GPT-5.4 best at?
Structured mathematical problem solving: MATH-500 at 94.6% is the highest score across all benchmark runs for the flagship. For multimodal and general-purpose reasoning, Mini's AGIEval English (63.04%) and Big Bench Hard (58.02%) represent secondary strengths at a lower price point.
Where does GPT-5.4 struggle?
The three weakest areas: competition-level math (AIME 2025: 16.67%), expert scientific reasoning (Humanity's Last Exam: 10.67%), and software engineering task completion (SWE-bench Lite: failure). General Purpose QA at 48.48% also underperforms relative to comparable frontier models.
Should I use GPT-5.4 Nano instead of the flagship?
For competition-style math reasoning: yes. GPT-5.4 Nano (26.67% on AIME 2025, 30.0% on AIME 2026) outscored the flagship (16.67%) and Mini (6.67%) on both AIME benchmarks while costing 12x less. For general knowledge tasks, multi-step reasoning, or professional knowledge benchmarks, Mini leads Nano.
Is GPT-5.4 suitable for software engineering workflows?
The Stratix evaluation of GPT-5.4 on SWE-bench Lite returned a failure status. GPT-5.4 Nano scored 32.33% on the same benchmark. Claude Opus 4.6 scored 62.67%. For engineering-heavy workflows, current Stratix data does not support the flagship as a primary choice.
Methodology
All evaluations were conducted on LayerLens Stratix using standardized benchmark configurations. GPT-5.4 was evaluated across six benchmark runs (five scored, one failure). GPT-5.4 Mini ran nine benchmarks and GPT-5.4 Nano ran ten. Comparisons against Claude Opus 4.6 use independently run evaluations on the same platform. Results for GPT-5.4 Mini and Nano reflect evaluations submitted March 17, 2026; flagship evaluations reflect data current as of March 18, 2026.
Full evaluation data, including prompt-level results and benchmark configurations, is available on Stratix at app.layerlens.ai.