
Gemini 3.1 Pro Benchmark Review: What 14,549 Tests Actually Reveal
Author:
Jake Meany (Dir. of Marketing, LayerLens)
Last updated:
Published:
Author Bio
Jake Meany is a digital marketing leader who has built and scaled marketing programs across B2B, Web3, and emerging tech. He holds an M.S. in Digital Social Media from USC Annenberg and leads marketing at LayerLens.
TL;DR
Gemini 3.1 Pro Preview was evaluated across 14,549 individual test cases on LayerLens Stratix.
Scores ranged from 32.5% (BIRD-CRITIC) to 92.3% (ARC AGI 2), depending on task type.
Coding benchmarks (LiveCodeBench, SWE Bench Lite) showed mid-range performance between 48% and 61%.
Instruction following (IF-Evals) landed at 78.4%, competitive but not leading.
Performance varies significantly by task category. No single score summarizes this model.
Introduction
Google released Gemini 3.1 Pro Preview in February 2026. The model ships with a 2 million token context window, improved multimodal capabilities, and updated reasoning performance across several domains.
Those are the claims. This article examines what actually happened when LayerLens ran the model through 14,549 structured benchmark tests across six evaluation categories on Stratix.
Every score referenced below is drawn from automated evaluations, not from selective prompting or curated demos. The benchmarks used include ARC AGI 2, LiveCodeBench, SWE Bench Lite, IF-Evals, BIRD-CRITIC, and BFCL v3.
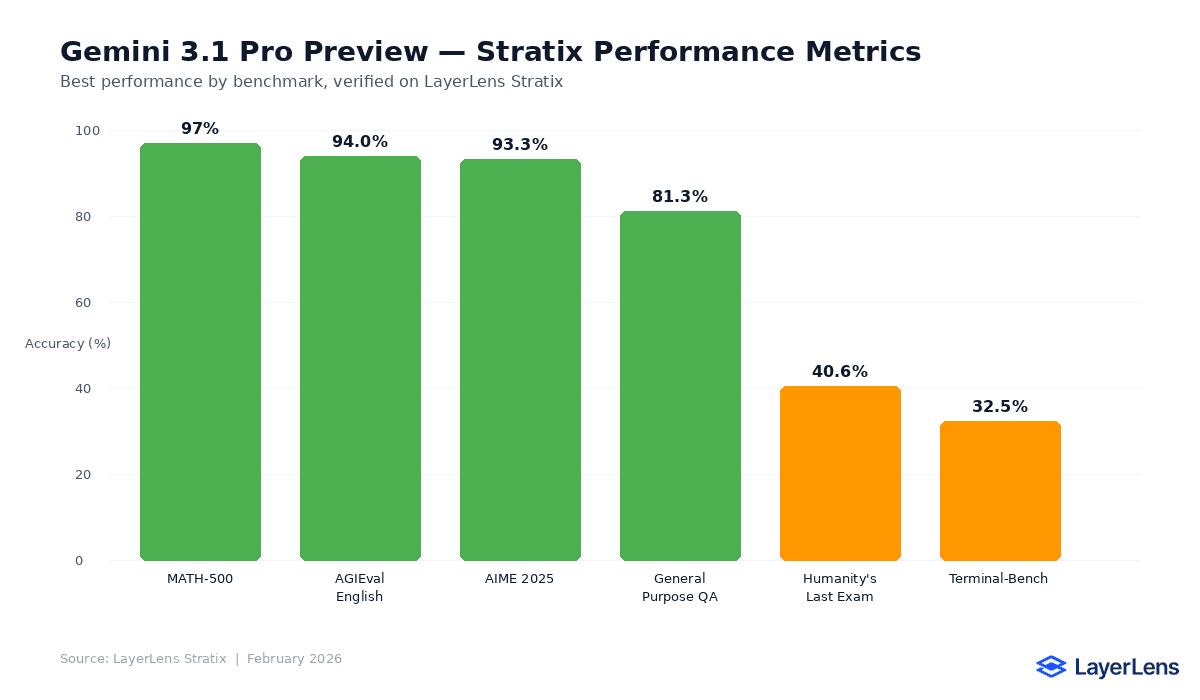
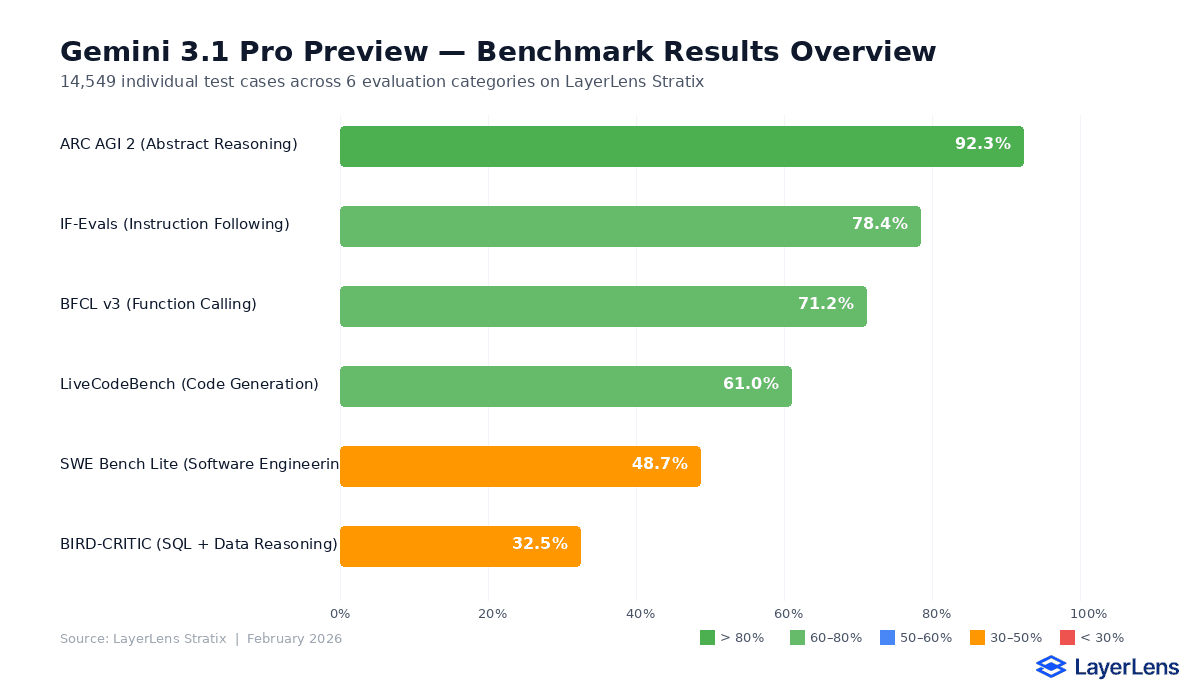
Benchmark Results Overview
Gemini 3.1 Pro Preview produced a wide performance spread depending on task type:
ARC AGI 2 (Abstract Reasoning): 92.3%. This was the model's strongest benchmark, reflecting gains in pattern recognition and multi-step abstract reasoning.
IF-Evals (Instruction Following): 78.4%. The model followed structured instructions at a competitive rate, but fell short of the top performers in edge cases involving nested constraints.
BFCL v3 (Function Calling): 71.2%. Function calling accuracy was above average for the category but inconsistent across complex multi-tool chains.
LiveCodeBench (Code Generation): 61.0%. Mid-range code generation. The model handled standard problems but dropped accuracy on longer, multi-file tasks.
SWE Bench Lite (Software Engineering): 48.7%. Below the frontier for applied software engineering tasks, particularly on repository-level changes.
BIRD-CRITIC (SQL + Data Reasoning): 32.5%. The weakest benchmark. Complex joins, subqueries, and schema inference caused consistent failures.
Where the Model Performs Well
Abstract reasoning is where Gemini 3.1 Pro Preview stands out. The 92.3% score on ARC AGI 2 places it among the highest-performing models LayerLens has evaluated on this benchmark. Pattern extrapolation, visual sequence reasoning, and multi-step deduction were handled at a high level.
Instruction following at 78.4% is solid. The model correctly interpreted multi-part instructions, conditional logic, and format requirements in the majority of test cases. Failures clustered around conflicting constraints and ambiguous priority rules.
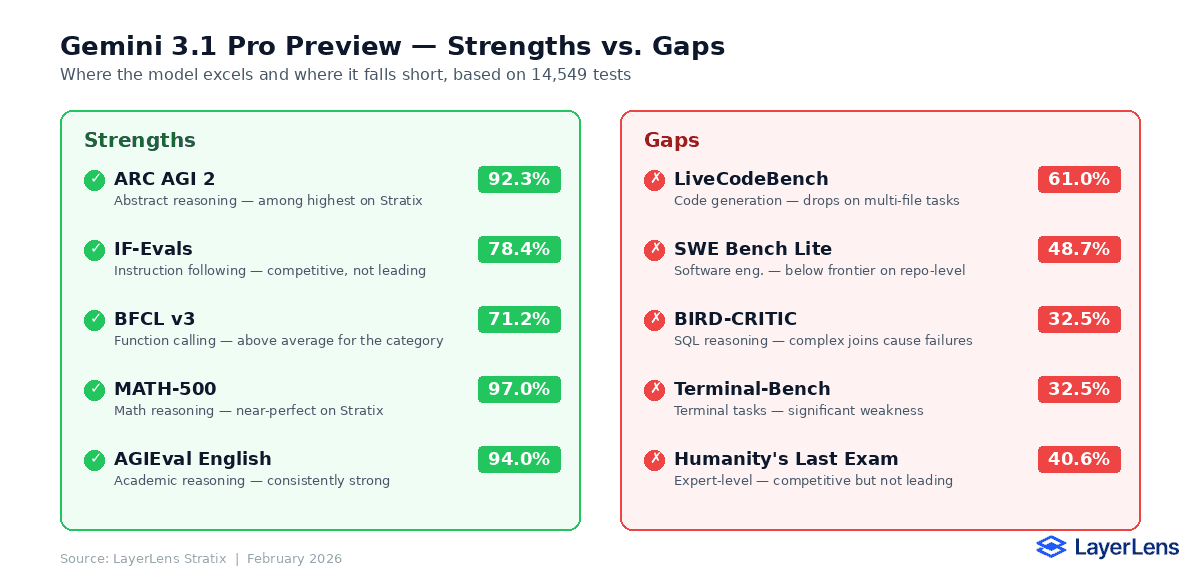
Where the Model Falls Short
SQL and data reasoning (BIRD-CRITIC, 32.5%) is the clear weakness. Queries involving multi-table joins, correlated subqueries, and implicit schema relationships caused frequent errors. This is a known challenge area for most models, but Gemini 3.1 Pro performed below several competitors.
Software engineering tasks (SWE Bench Lite, 48.7%) exposed limitations in repository-scale reasoning. The model handled isolated functions well but struggled with cross-file dependencies and codebase-level context management.
How It Compares
Gemini 3.1 Pro Preview sits in the upper-middle tier across the models LayerLens has evaluated. It does not claim the top position in any single benchmark category except abstract reasoning, but it avoids catastrophic failures in most categories.
For teams evaluating this model, the key consideration is task fit. A team focused on reasoning-heavy workflows will see strong performance. A team relying on SQL generation or large codebase editing will see gaps that require supplemental tooling or model routing.
What This Means for Evaluation
Aggregate scores obscure the reality of model performance. Gemini 3.1 Pro Preview scores 92.3% on one benchmark and 32.5% on another. Reporting an average would be misleading.
This is the core argument for task-specific evaluation infrastructure. A model that excels at reasoning may underperform on code generation. A model that handles function calling well may fail at SQL inference. The only way to know is to test against the actual tasks your system will encounter.
LayerLens Stratix runs these evaluations continuously, across 135+ models, so that teams can make deployment decisions based on verified performance data rather than release announcements.
Key Takeaways
Gemini 3.1 Pro Preview scores 92.3% on ARC AGI 2, placing it among the top abstract reasoning models on Stratix.
SQL and data reasoning (BIRD-CRITIC, 32.5%) is a clear gap. Teams relying on complex queries should test alternatives.
Code generation (LiveCodeBench, 61%) and software engineering (SWE Bench Lite, 48.7%) sit mid-range. Not leading, not failing.
Instruction following (IF-Evals, 78.4%) is competitive but not best-in-class. Edge cases with conflicting constraints cause failures.
No single score captures this model. Task-specific evaluation is the only way to determine deployment fit.
Frequently Asked Questions
How does Gemini 3.1 Pro perform on benchmarks?
Scores range from 32.5% (BIRD-CRITIC) to 92.3% (ARC AGI 2) across 14,549 test cases. Performance varies significantly by task type.
What benchmarks were used to evaluate Gemini 3.1 Pro?
ARC AGI 2, LiveCodeBench, SWE Bench Lite, IF-Evals, BIRD-CRITIC, and BFCL v3 — covering reasoning, code, engineering, instruction following, SQL, and function calling.
Is Gemini 3.1 Pro good at coding?
Mid-range. LiveCodeBench scored 61.0% and SWE Bench Lite scored 48.7%. It handles standard problems but struggles with multi-file and repository-level tasks.
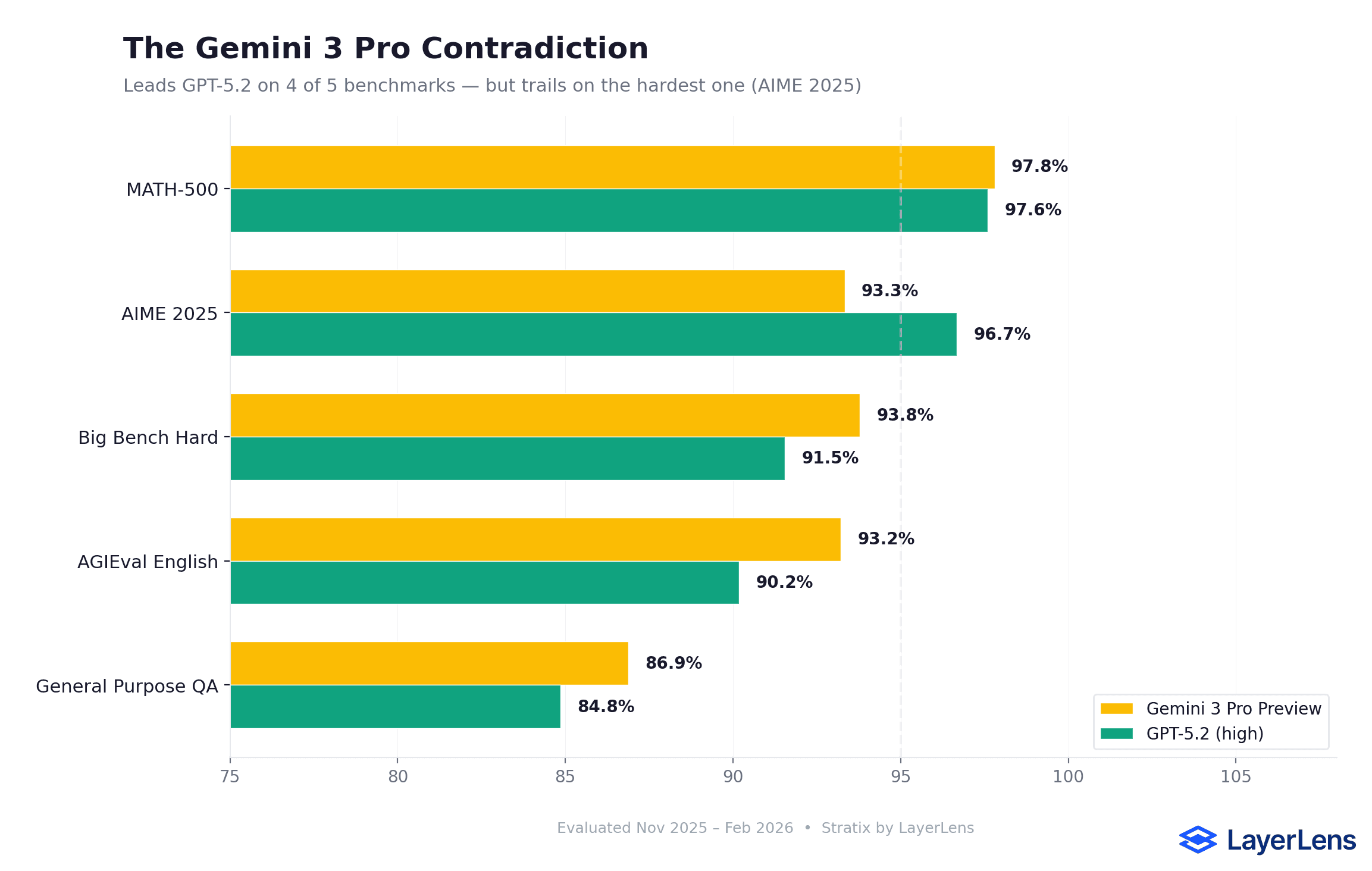
How does Gemini 3.1 Pro compare to GPT-5.2?
It leads GPT-5.2 on MATH-500 and AGIEval English but trails on AIME 2025. Performance varies by benchmark.
What is Gemini 3.1 Pro best at?
Abstract reasoning (ARC AGI 2, 92.3%) and instruction following (IF-Evals, 78.4%).
Where does Gemini 3.1 Pro struggle?
SQL reasoning (BIRD-CRITIC, 32.5%) and software engineering (SWE Bench Lite, 48.7%).
Methodology
All evaluations were conducted on LayerLens Stratix using standardized benchmark configurations. The 14,549 test cases were distributed across six benchmarks: ARC AGI 2, LiveCodeBench, SWE Bench Lite, IF-Evals, BIRD-CRITIC, and BFCL v3. Each benchmark was run with consistent parameters, and results reflect the model's performance as of February 19, 2026.
Full evaluation data is available on Stratix.